21.6 Biclustering
In some cases, we have a data matrix , and we want the cluster the rows and the columns. This is known as biclustering.
This is widely used in bioinformatic, where rows represent genes and columns represent conditions. It can also be used in collaborative filtering, where the rows represent users and columns represent movies.

21.6.1 Spectral Co-clustering
The spectral co-clustering algorithm finds bi-cluster with values higher than those in the corresponding other rows and columns.
Each row and each column belongs exactly to one bicluster, so rearranging the rows and columns to make partitions contiguous reveals these high values along the diagonal.
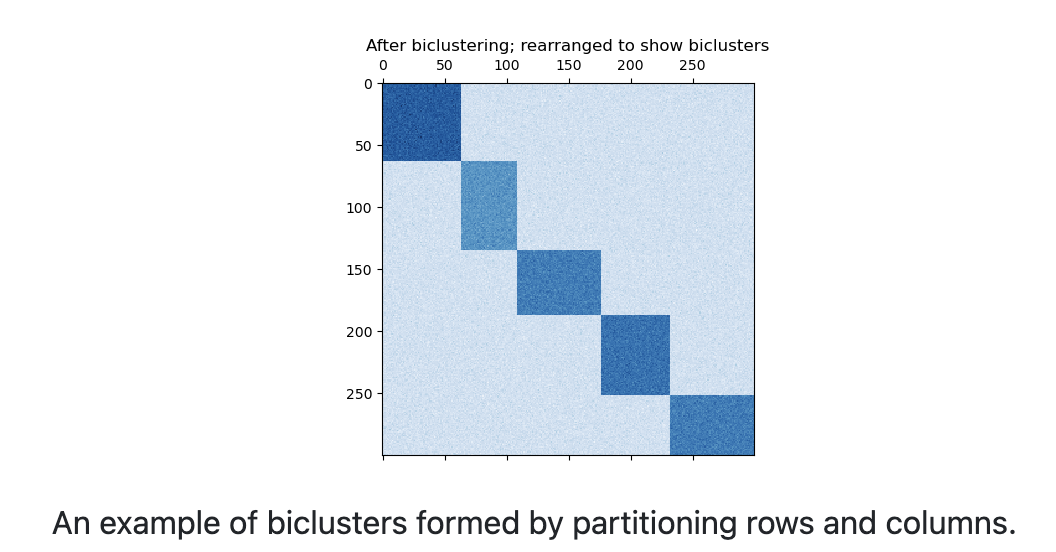
An approximate solution to the optimal normalized cut may be found via the generalized eigenvalue decomposition of the graph Laplacian.
If the original data has shape , then the Laplacian matrix for the corresponding bipartite graph has shape .
However, in this case it is possible to work directly with , which is smaller and make the compute more efficient.
is preprocessed as follow:
where and .
The SVD decomposition , provides the partition of rows and columns:
- A subset of gives the rows partitions
- A subset of gives the columns partitions.
The singular vectors, starting from the second give the partition.
We can then form a low dimensional matrix:
where the columns of are and similarly for .
Finally, we apply K-means on to find our rows and columns partitioning.
21.6.2 Spectral Biclustering
The spectral biclustering assumes that the input data matrix has a hidden checkerboard structure.
The rows and columns matrix with this structure may be partitioned so that the entries of any bicluster in the Cartesian product of row cluster and column cluster is approximately constant.
For instance, if there are 2 row partitions and 3 column partitions, each row will belong to 3 bicluster and each column will belong to 2 bicluster.
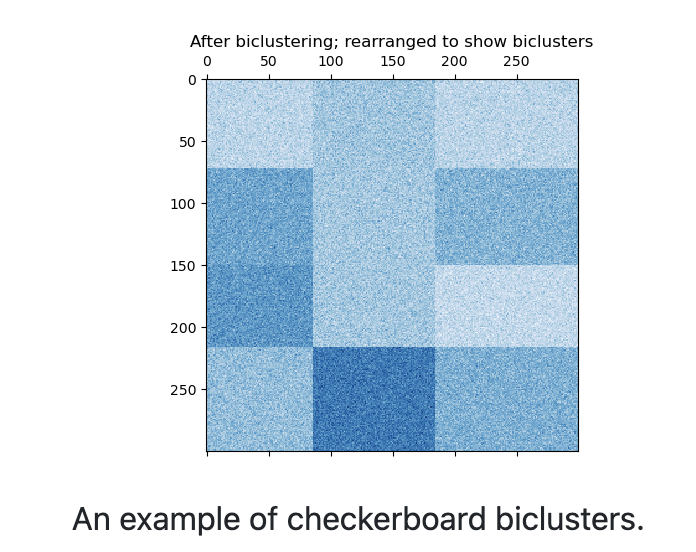
The input matrix is first normalized to make the checkerboard pattern obvious. There are three possible methods:
-
Independent row and column normalization, as in spectral co-clustering.
-
Bistochastization: repeat row and column normalization until convergence. This methods make both rows and columns sum to the same constant.
-
Log normalization: we compute and we normalize by the following:
After normalizing, the first few eigenvectors are computed, as in co-clustering.
We rank the first singular vectors and according to which can be best approximated by a piecewise constant vector.
The approximation for each vector are found by using a 1d k-means and score via Euclidean distance.
Next, the data is projected to this best subset of singular vectors by computing and , and clustered.