22.2 Implicit feedback
So far, we have assumed that the user gives explicit ratings for each item they interact with, which is very restrictive.
More generally, we would like to learn from the implicit feedback that users give by interacting with a system. For instance, we could treat all movies watched by a user as positive, and all the others as negative. We end-up with a sparse, positive-only ratings matrix.
Alternatively, we can consider a user watching item but not item as an implicit signal that they prefer over . The resulting data can be represented as a set of tuples , where is a positive pair, and is a negative, unlabeled pair.
22.2.1 Bayesian personalized ranking
To fit a model of the form , we need to use a ranking loss, so that the model ranks ahead of for user .
A simple way to do it is to use a Bernoulli form of the data:
If we combine this with a Gaussian prior for , we get the following MAP estimation problem:
where , where is the set of items user selected, and are all the items.
This is known as Bayesian personalized ranking (BPR).
As an example, if and the user chose to interact with , we get the following implicit item-item preference matrix:
where means user prefer item over , and means that we can’t determine its preferences.
When the set of possible items is large, the number of negative in can be large. Fortunately, we can approximate the loss by subsampling negatives.
Note that an alternative to the log-loss above is to use the hinge loss, similar to the approach used for SVMs:
where is the safety margin. This ensures the negative items never scores more than higher than the positive items .
22.2.2 Factorization machines
The AutoRec approach of section 22.1.4 is nonlinear but treats users and items asymmetrically.
We start with a linear and symmetrical discriminative approach, by predicting the output (such as a rating) of a user-item one-hot-encoded pair:
where , is the number of inputs, is a weight matrix, is a weight vector, and is a global offset.
This is known as a factorization machine (FM), and is a generalization of the equation in section 22.1.3:
since can handle information beyond user and item.
Computing the generalized equation takes time since it considers all pairwise interactions between users and items.
Fortunately, we can rewrite this to compute it in as follows:
For sparse vectors, the complexity is linear in the number of nonzero components, so here it is just .
We can fit this model to minimize any loss we want, e.g., MSE loss if we have explicit feedbacks, ranking loss if we have implicit feedbacks.
Deep factorization machines combine the above with an MLP applied to a concatenation of the embedding vectors, instead of the inner product. The model has the form:
The idea is that the bilinear FM model captures explicit interactions between users and features, while the MLP captures implicit relation between user features and item features, which allows the model to generalize.
22.2.3 Neural matrix factorization
The **Neural matrix factorization (opens in a new tab)** model is another way to combine bilinear model with neural nets.
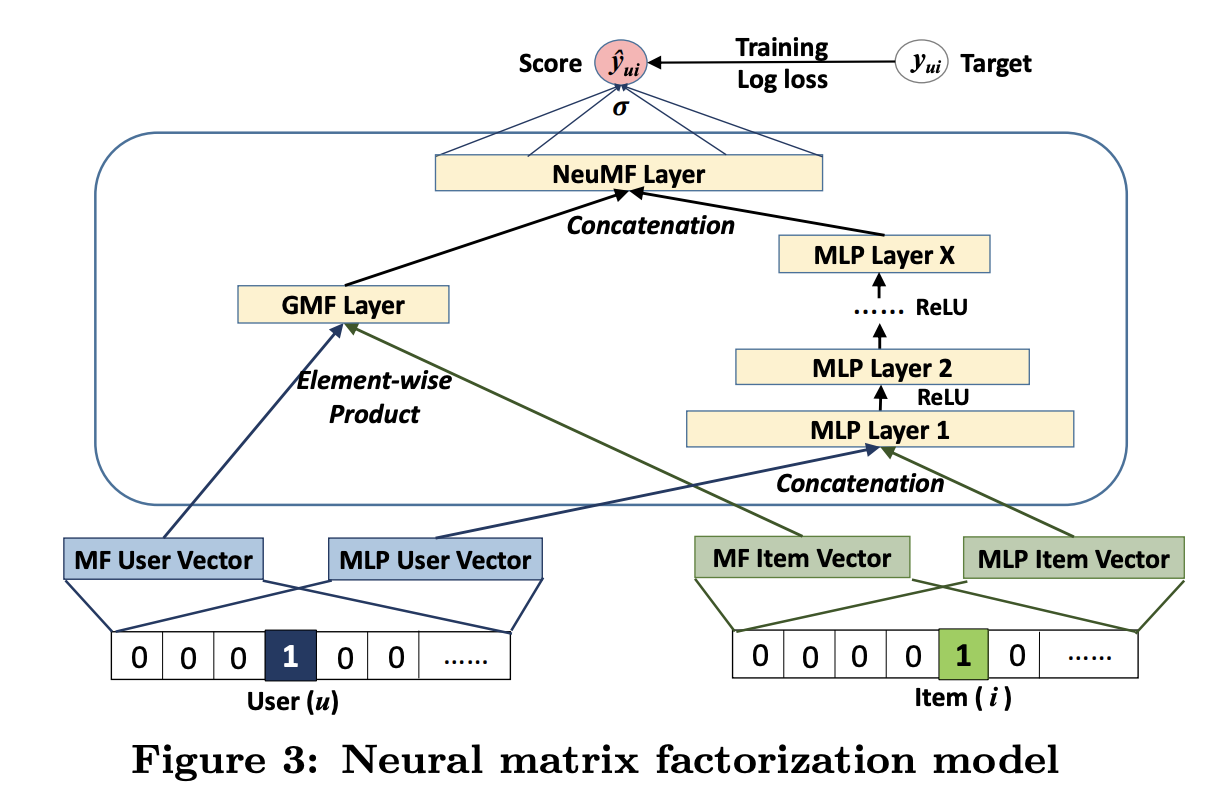
The bilinear part is used to define the generalized matrix factorization (GMF) pathway, which computes the following feature for user and item :
where and are user and item embedding matrices.
The DNN part is a MLP applied to the concatenation of other embedding vectors:
Finally, the model combines these to get:
The model is trained on implicit feedback, where if the interaction is observed, otherwise. However it could be trained to minimize BPR loss.