14.6 Generating images by inverting CNNs
A CNN trained for image classification is a discriminative model of the form , returning a probability distribution over class labels.
In this section, we convert this model into a conditional generative image model of the form . This will allow us to generate images belonging to a specific class.
14.6.1 Converting a trained classifier into a generative model
We can define a joint distribution over images and labels .
If we select a specific label value, we can create a conditional generative model .
Since is not an invertible function, the prior will play an important role as a regularizer.
One way to sample from this model is to use Metropolis Hasting algorithm, were the energy function is:
Since the gradient is available, we then make the update:
where:
This is called the Metropolis adjusted Langevin algorithm (MALA).
As an approximation we skip the rejection part and accept every candidate, this is called the unadjusted Lanvin algorithm and we used for conditional image generation (opens in a new tab).
Thus, we get an update over the space of images that looks like a noisy SGD, but the gradient are taken w.r.t the inputs instead of the weights:
- ensures the image is plausible under the prior
- ensures the image is plausible under the likelihood
- is a noise term to enforce diversity. If set to 0, the method a deterministic algorithm generating the “most likely image” for this class.
14.6.2 Image priors
We now discuss priors to regularize the ill-posed problem of inverting a classifier. Priors, combined with the initial image, determine the kinds of outputs to generate.
14.6.2.1 Gaussian prior
The simplest prior is , assuming the pixels have been centered. This can prevent pixels to have extreme values.
The update due to the prior term has the form:
The update is (assuming and ):
This can generate the following samples:

14.6.2.2 Total variation (TV) prior
To help generating more realistic images, we can add extra regularizers like total variation or TV norm of an image. This is the integral of the per-pixel gradients, approximated as:
where is the pixel value of at location for channel .
We can rewrite this in term of the horizontal and vertical Sobel edge detector applied to each channel:

Using:
discourage images from having high frequency artifacts.
Gaussian blur can also be used instead of TV, with similar effects.

14.6.3 Visualizing the feature learned by a CNN
Activation maximization (AM) optimizes a random image to maximize the activation of a given layer. This can be useful to get a better grasp of the features learned by the ConvNet.
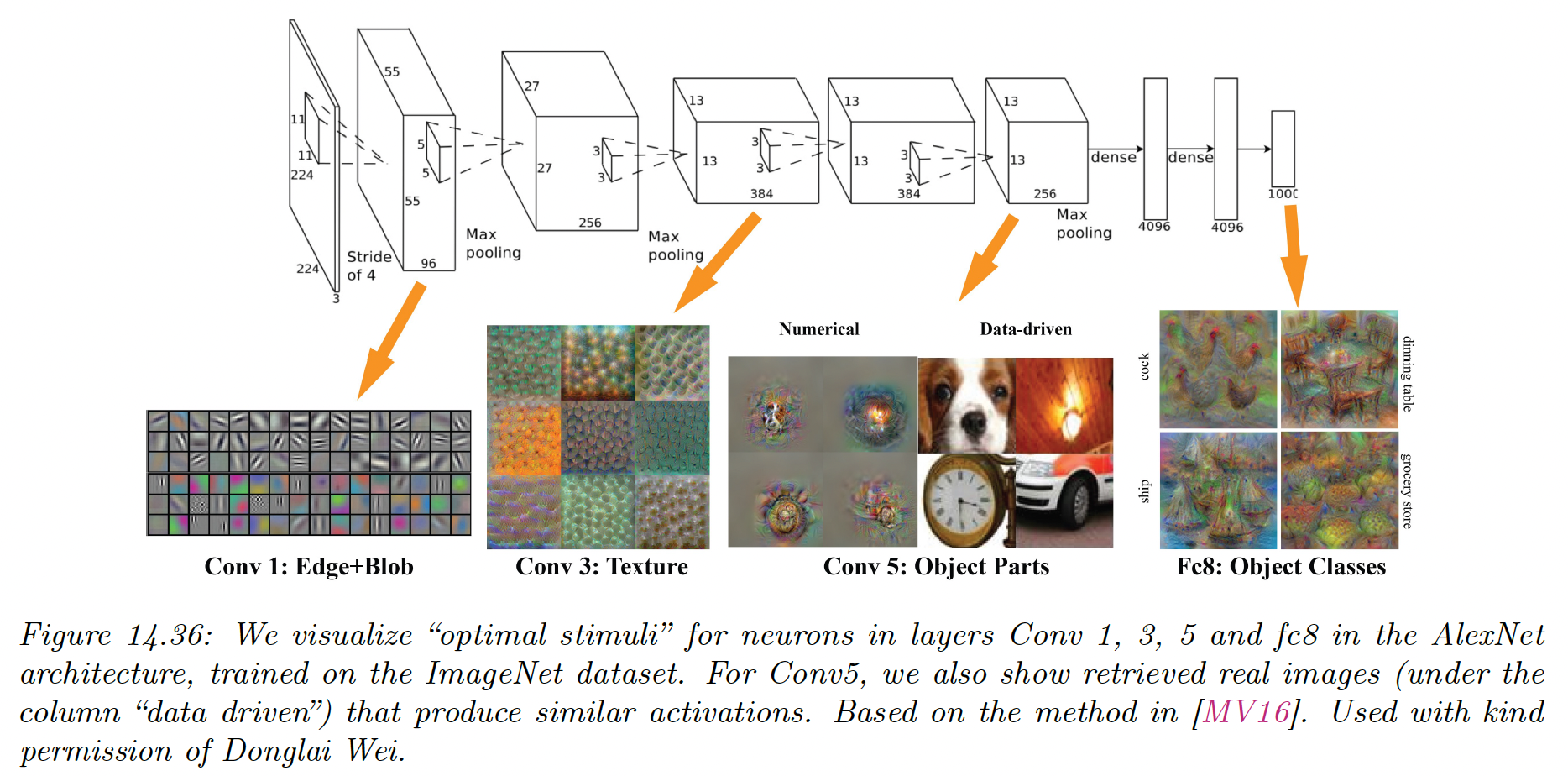
Below are the results for each layer of an AlexNet, using a TV prior. Simple edges and blobs are recognized first, and then as depth increase, we find textures, object parts and finally full objects.
This is believed to be roughly similar to the hierarchical structure of the visual cortex.
14.6.4 Deep Dream
Instead of generating images that maximize the feature map of a given layer or class labels, we now want to express these features over an input image.
We view or trained classifier as a feature extractor. To amplify features from layers , we define a loss function of the form:
where
is the feature vector for layer .
We can now use gradient descent to optimise this loss and update our original image. By using the output as input in a loop, we iteratively add features to it.
This is called DeepDream, because the model amplifies features that were only initially hinted.

The output image above is a hybrid between the original image and “hallucinations” of dog parts, because ImageNet contains contains so many kinds of dogs.
14.6.5 Neural style transfer
Neural style transfer (opens in a new tab) give more generative control to the user, by specifying a “content” image and a “style” image . The model will try to generate new image that re-renders\bold{x}$$\bold{x}_c by applying the style .
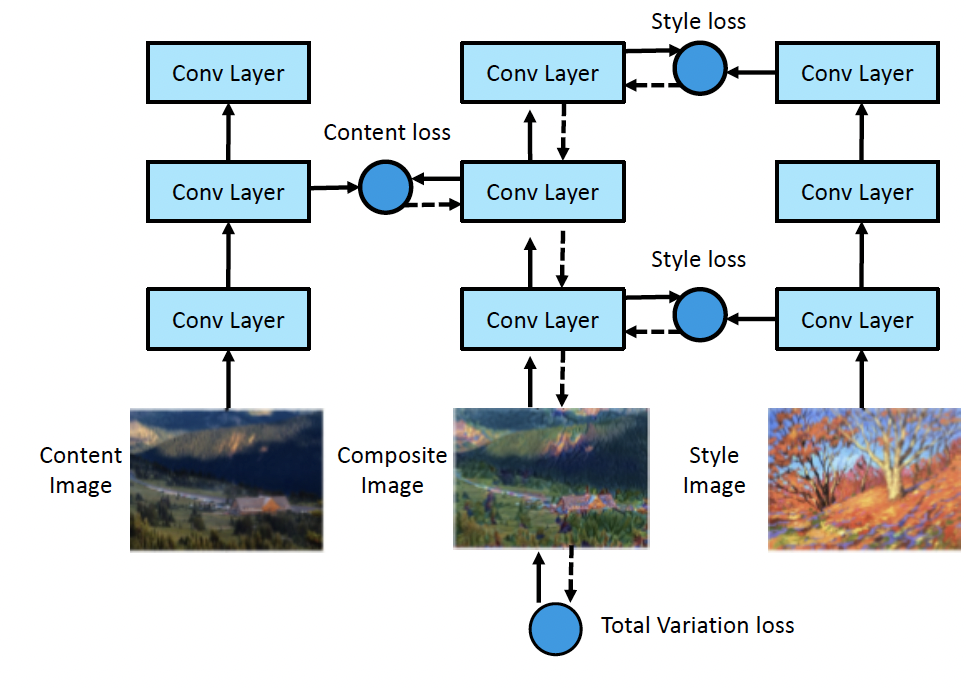

14.6.5.1 How it works
Style transfer works by optimizing the loss function:
where is the total variation prior.
The content loss measures similarity between to by comparing feature maps of a pre-trained ConvNet in the layer :
We can interpret the style as a statistical distribution of some kinds of image features. Their location don’t matter, but their co-occurence does.
To capture the co-occurence statistics, we compute the Gram matrix for the image using feature maps at layer :
The Gram matrix is a matrix proportional to the uncentered covariance.
Given this, the style loss is:
14.6.5.2 Speeding up the method
In the Neural style transfer paper, they used L-BFGS to optimize the total loss, starting from white noise.
We can get faster results if we use Adam and we start from an actual image instead of noise. Nevertheless, running optimization for every single content and style image is slow.
i) Amortized optimization
Instead, we can train a network to predict the outcome of this optimization. This can be viewed as a form of amortized optimization.
We fit a model for every style image:
We can apply this to new content images without having to reoptimize.
ii) Conditional instance normalization
More recently, it has been shown that we can train a network that take both the content image and a discrete style representation as inputs:
This avoids training a separate network for every style instances.
The key idea is to standardize the features at a given layer using scale and shift parameters that are specific to the style.
In particular, we use conditional instance normalization:
where and are the mean and std of feature maps at a given layer, and and are parameters for style .
This simple trick is enough to capture many kind of styles.
iii) Adaptative instance normalization
The drawback of the above techniques is that they are limited to a set of pre-defined styles.
Adaptative instance normalization (opens in a new tab) proposes to generalize this by replacing and by learned parameters from another network, taking arbitrary style image as input: