9.4 Generative vs Discriminative classifiers
A model of the form is generative since it can be used to generate features given the target.
A model of the form is discriminative since it can only be used to discriminate between the targets.
9.4.1 Advantages of the Discriminative Classifiers
- Better predictive accuracy because is often much simpler to learn than .
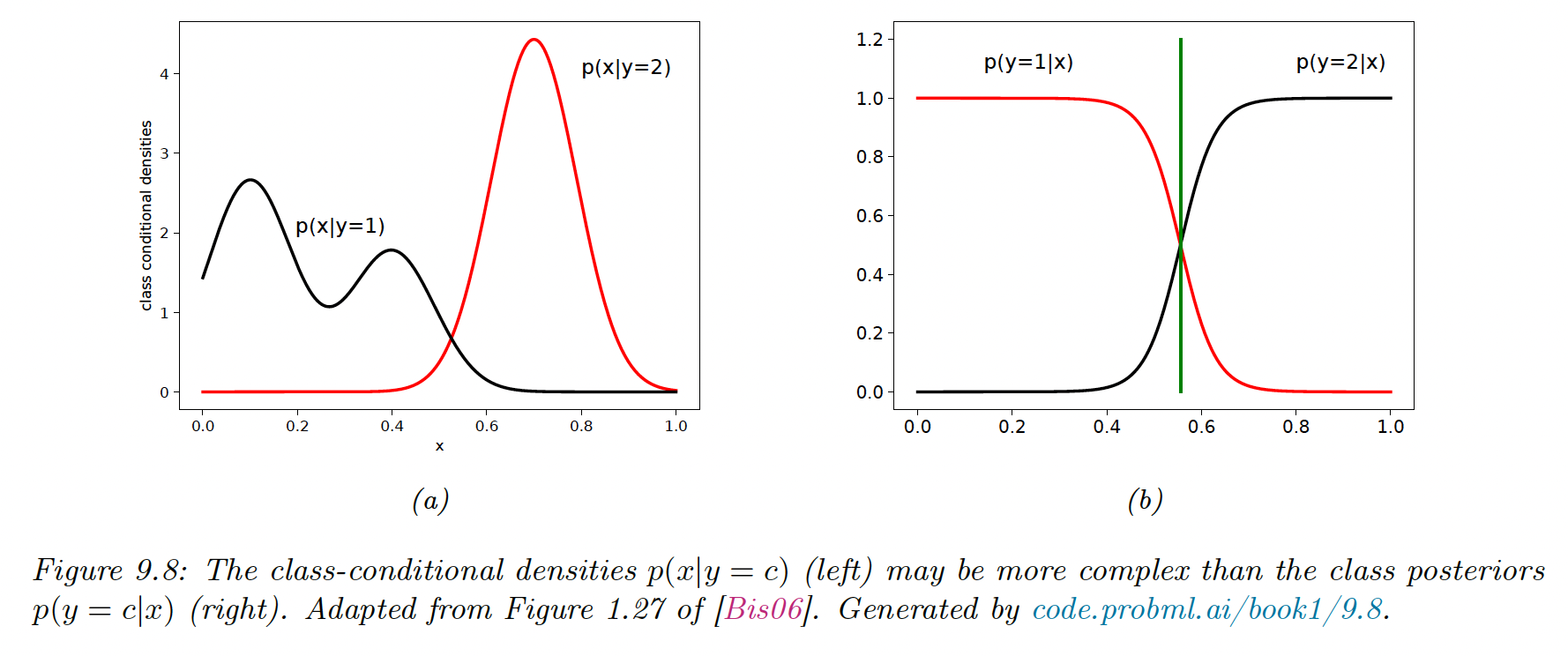
- Can arbitrarily handle feature preprocessing, for example, polynomial expansion of the feature inputs, or replace strings with embeddings. It is hard to do with generative models since the new features can be correlated in complex ways.
- Well-calibrated probabilities. Some generative models like NBC make strong and often invalid independence assumptions, leading to extreme posterior class probabilities (near 0 and 1).
9.4.2. Advantages of the Generative Classifiers
- Easy to fit, the NBC only needs counting and averaging, whereas Logistic Regression needs to solve a convex optimization problem and Neural Nets non-convex optimizations.
- Can easily handle missing values by filling them with the fitted generative model (can be the empirical mean for each variable)
- Can fit classes separately, we estimate each class density independently. With discriminative models, however, all parameters interact so we need to retrain the model if we add new classes.
- Can handle unlabeled training data, it is easy to use generative models for semi-supervised learning, in which we combine labeled data and unlabeled data . Discriminative classifiers have no uniquely optimal way to leverage .
- May be more robust to spurious features, a discriminative model may choose features that discriminate well on the training set, but hardly generalize outside of it. By contrast, generative models may be better at capturing the causal mechanism underlying the data generative process, and hence be more robust to distribution shifts.
9.4.3 Handling missing features
With a generative model, we can easily deal with missing parts of during training or testing (we assume a MAR situation).
For example, suppose we don’t have access to , we have to compute:
If we make the Naive Bayes assumption, it leads to: