18.4 Random Forests
Bagging relies on the assumption that re-running the algorithme on different subsets of the data will result in sufficiently diverse base models.
The random forests approach tries to decorrelate the base learners even further by learning trees based on a randomly chosen subset of input variables (at each node of the tree) , as well as a randomly chosen subset of data case.
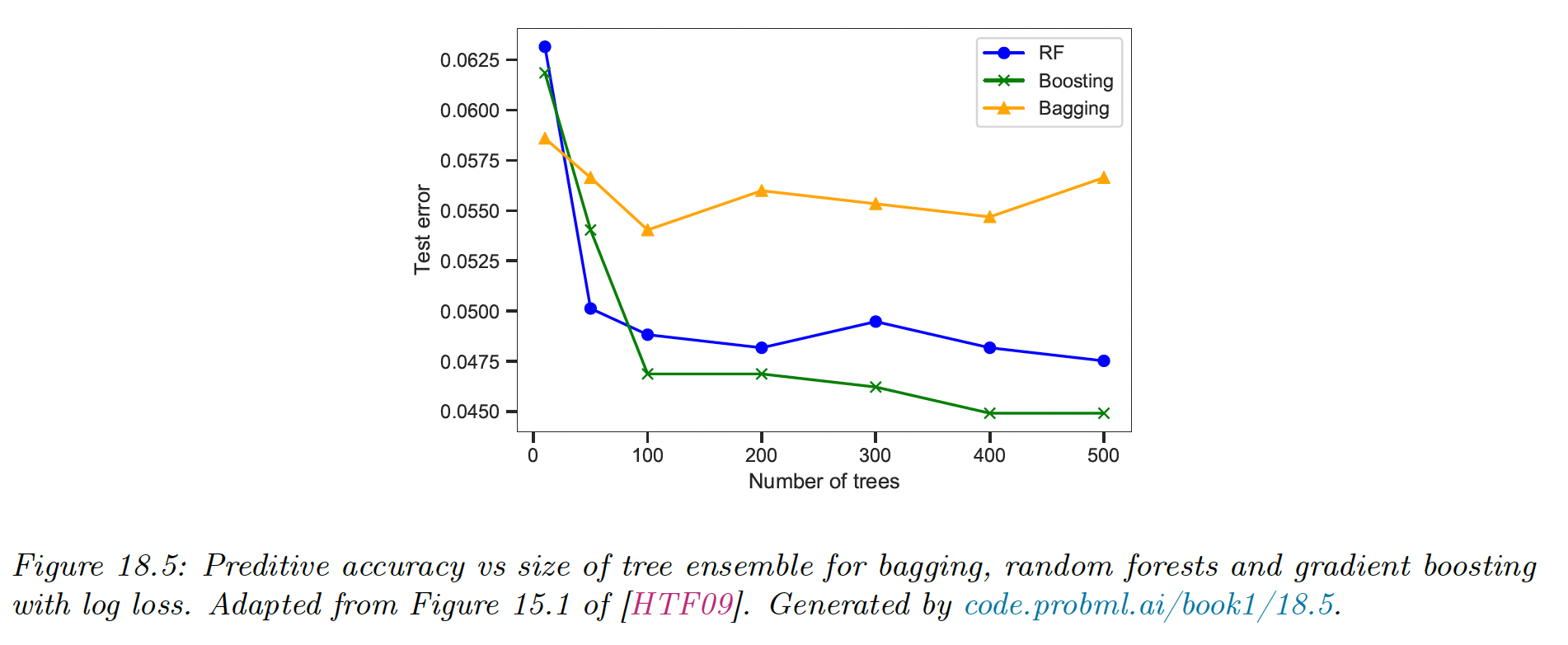
The figure above shows that random forest work much better than bagged decision trees, because in this spam classification dataset, many input features are irrelevant.
We also see that boosting works even better, but relies on a sequential fitting of trees, whereas random forests can be fit in parallel.
When it comes to aggregating the predictions of base models, note that the scikit-learn random forests implementation (opens in a new tab) combines classifiers by averaging their probabilistic prediction, instead of letting each classifier vote for a single class.
See scikit-learn comparison of random forests and gradient boosting trees (opens in a new tab).