17.3 Support vector machines (SVM)
We now discuss a form of (non-probabilistic) predictors for classification and regression problems which have the form:
By adding some constraints, we can ensure only few coefficient are non-zero, so that predictions only depends on a subset of the training points, called support vectors.
The resulting model is called support vector machine (SVM).
17.3.1 Large margin classifiers
Consider a binary classifier of the form , where the decision boundary is given by:
In the SVM literature, it is common to use class labels of rather than . We denote such targets as instead of .
There might be many lines that separate the data, and intuitively we want to pick the one that has the maximum margin. This represents the distance between the closest point to the decision boundary.
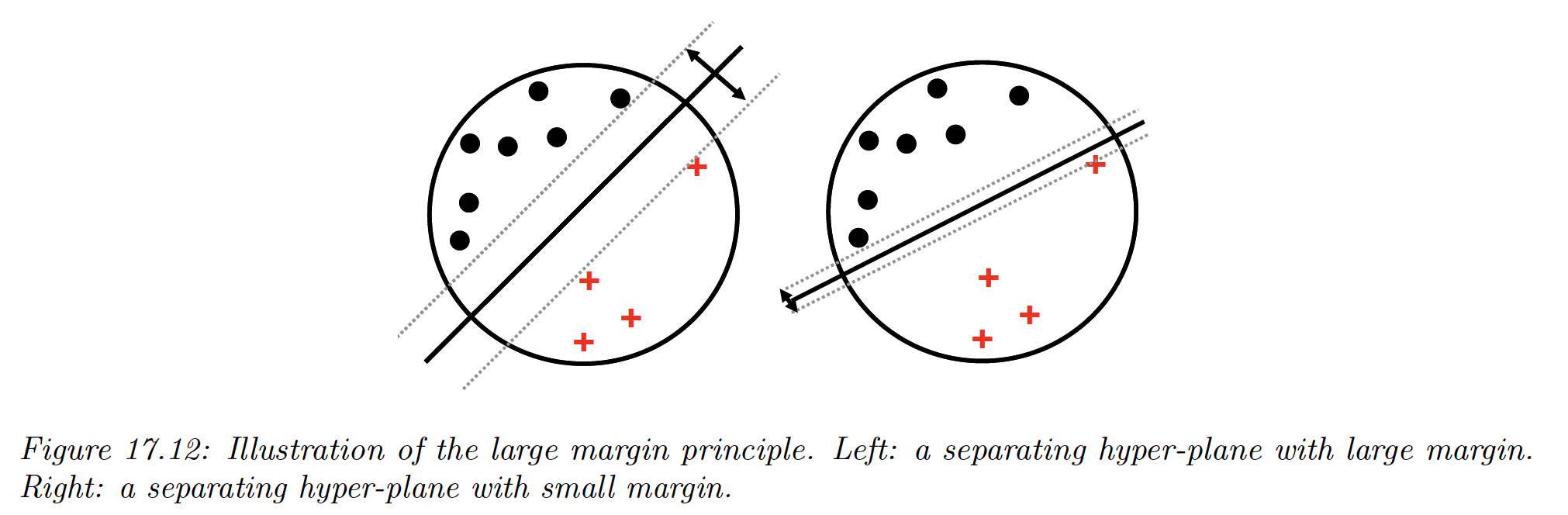
The model on the left gives the best solution, because more robust to perturbation of the data.
How can we compute such a large margin classifier? First, we need to derive an expression of the distance of a point to the decision boundary.
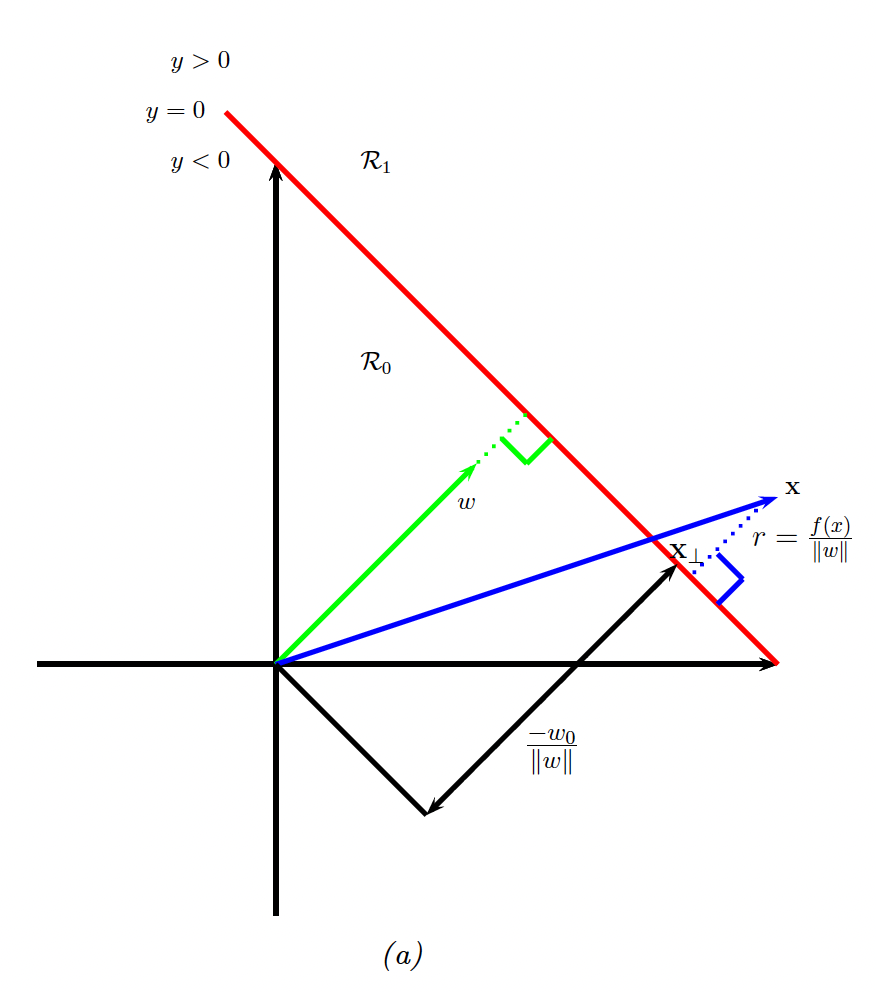
We see that:
where is the distance from to the decision boundary whose normal vector is , and is the orthogonal projection of on the decision boundary.
We would like to maximize , so we need to express it as a function of :
Since , therefore
Since we want to ensure that each point is on the correct point of the boundary, we also require .
We want to maximize the distance to the closest point, so our final objective is:
Note that rescaling the parameters using don’t change the distance to the decision boundary, since we divide by .
Therefore let’s define the scale factor such as that closest point to the decision boundary. Hence for all .
Thus, we get the new objective:
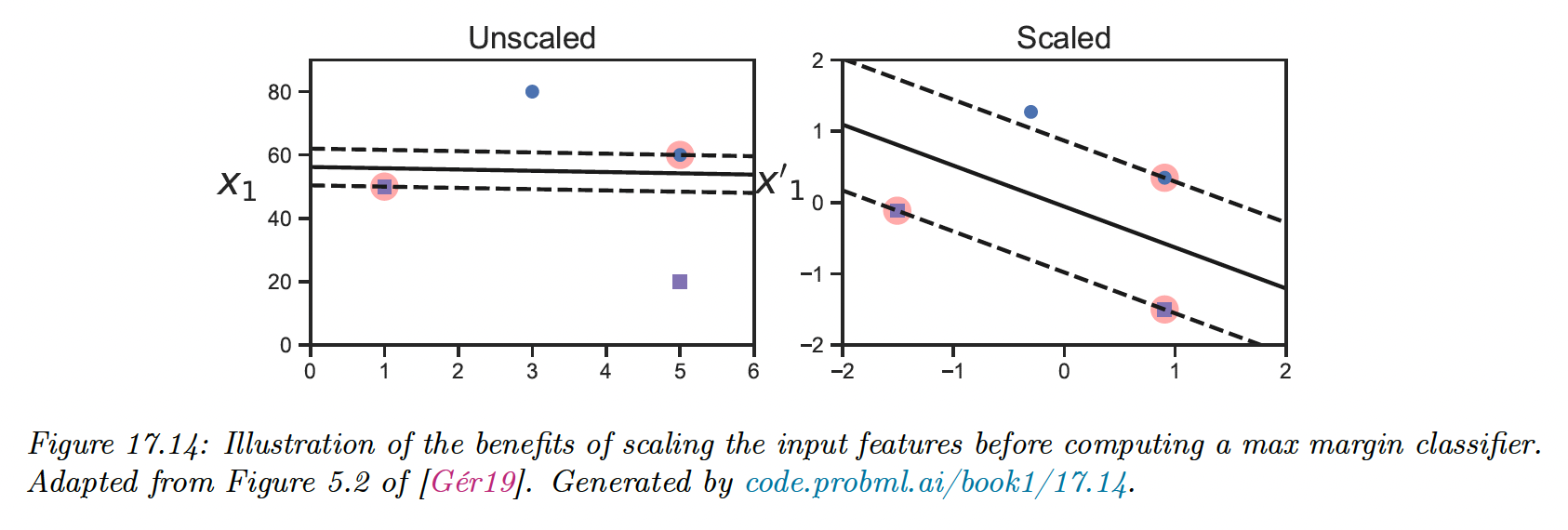
Note that it is important to scale the input variables before using an SVM, otherwise the margin measures distance of a point to the boundary using all input dimensions equally.
17.3.2 The dual problem
The last objective is a standard quadratic programming problem since we have a quadratic objective subject to linear constraints. This has variables for constraints, and is known as a primal problem.
In convex optimization, for every primal problem we can derive a dual problem. Let be the dual variables, corresponding to Lagrangian multipliers that enforce inequality constraints.
The generalized Lagrangian is:
To optimize this, we must find stationary point that satisfies:
We do it by computing the partial derivatives wrt and and setting them to zero:
Hence:
Plugging these into the Lagrangian yields:
This is called the dual form of the objective. We want to maximize this wrt subject to the constraints that and
The above objective is a quadratic problem with variables. Standard QP problems solvers take time.
However, specialized algorithms, such as sequential minimal optimization (SMO), have been developed to avoid using generic QP solvers. These take to time.
Since this is a convex objective, it must satisfied the KKT conditions, which yields the following properties:
Hence either or the constraint is active. This latter condition means that example lies on the decision boundary, so it is a support vector.
We denote the set of support vectors by . To perform prediction, we use:
To solve for , we can use the fact that for any support vector, we have .
Multiplying each side by and exploiting the fact that , we get
We take to mean to obtain a more robust estimate:
17.3.3 Soft margin classifiers
If the data is not linearly separable, there will be no feasible solution in which for all .
We therefore introduce slack variables and replace the hard constraints with soft margin constraints .
The objective becomes:
where is a hyperparameter controlling how many points we allow to violate the margin constraint. If , we recover the previous unregularized hard margin classifier.
The corresponding Lagrangian is:
where and are the Lagrange multipliers.
Optimizing out , and gives the dual form:
This is identical to the hard margin case, however the constraints are different. The KKT conditions imply that:
- If , the point is ignored.
- If then so the point lies on the margin.
- If , then the point can lie inside the margin, and can either be correctly classified if , or misclassified if .
Hence, is an upper bound on the number of misclassified points.
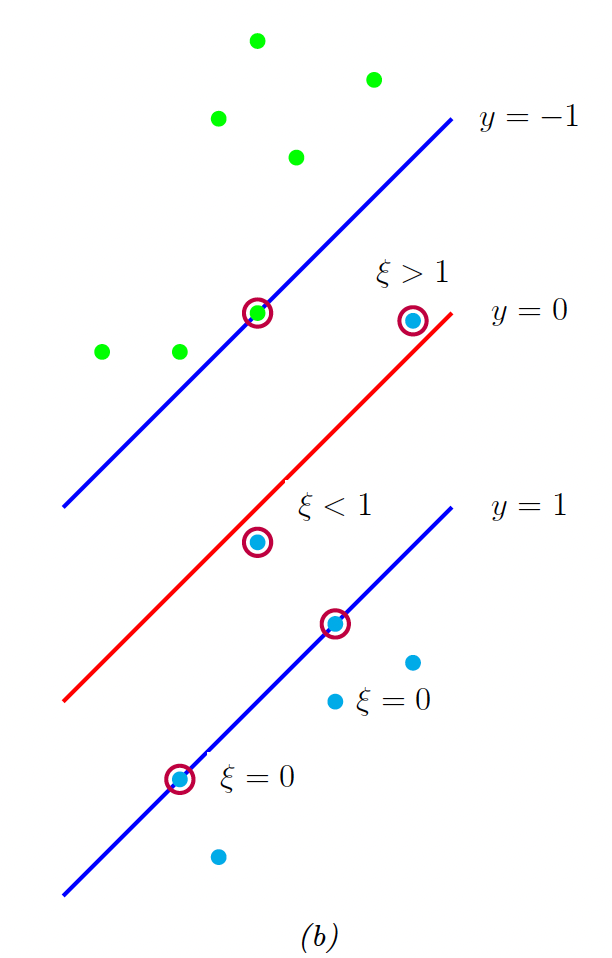
As before, the bias term can be computed using:
where is the set of points having .
There is an alternative formulation called -SVM classifier. This involves maximizing:
subject to the constraints:
This has the advantage that the parameter , which replace the parameter , can be interpreted as an upper bound on the fraction of margin errors (point for which ), as well as a lower bound on the number of support vectors.
17.3.4 The kernel trick
We have converted the large margin classification problem into a dual problem in unknowns which takes time to solve, which is slow.
The benefit of the dual problem is that we can replace all inner product operation with a call to a positive definite Mercer kernel function, . This is called kernel trick.
We can rewrite the prediction equation as:
We also need to kernelize the bias term:
The kernel trick allows us to avoid dealing with explicit feature representation, and allows us to easily apply classifiers to structured objects, such as strings and graphs.
17.3.5 Converting SVM outputs into probabilities
An SVM classifier produce hard labeling . However, we often want a measure of confidence in our prediction.
One heuristic approach is to interpret as the log-odds ratio . We can then convert an SVM output to probability:
where , can be estimated using MLE on a separate validation set. This is known as Platt scaling.
However, the resulting probabilities are not well calibrated, since there is nothing that justifies interpreting as the log-odds ratio.
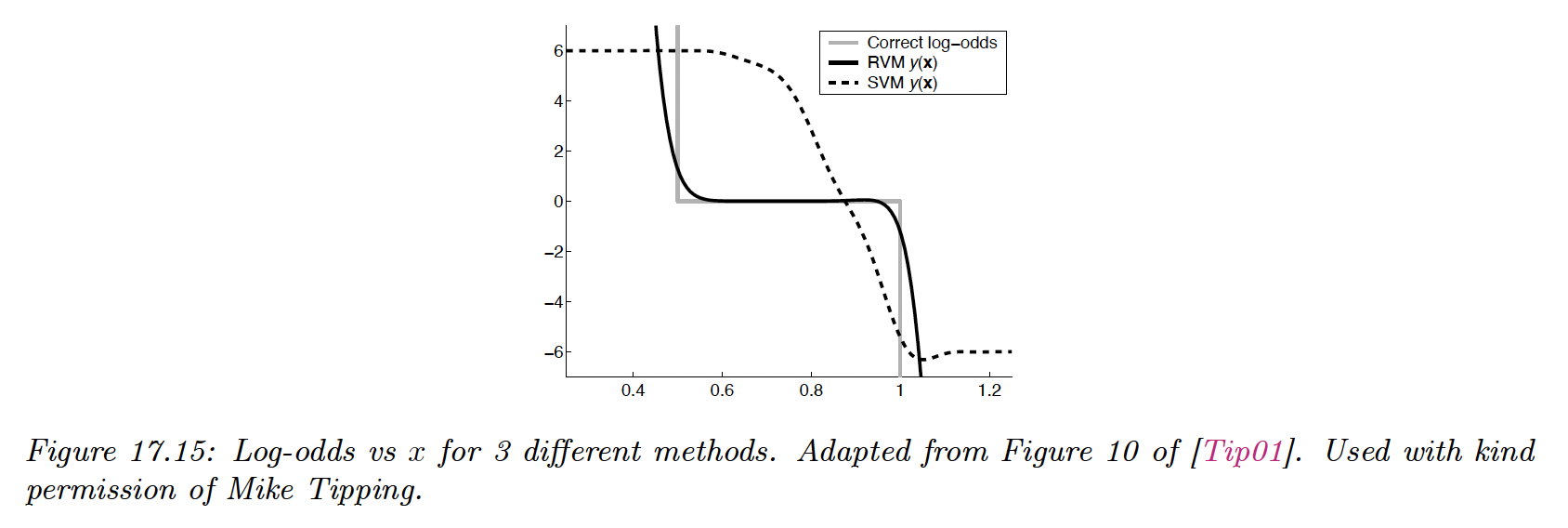
To see this, suppose we have 1d data where:
Since the class-conditional distributions overlap in this interval, the log-odd should be 0 inside it and infinite outside.
We train a probabilistic kernel classifier (RVM) and a SVM with Gaussian kernel. Both model can perfectly capture the decision boundary and achieve a generalization error of 25%, which is Bayes optimal in this problem.
However, the SVM doesn’t yield a good approximation of the true log-odds.
17.3.6 Connection with logistic regression
Data points that are on the (correct side) decision boundary have , the others have . Therefore we can rewrite the soft-margin objective in its primal form as:
where and the hinge loss is defined as:
This is a convex, piecewise differentiable upper-bound to the 0-1 loss.
By contrast, the (penalized) logistic regression optimizes:
where the log loss is given by:
The two major differences between both loss is that:
- The hinge loss is piecewise linear, so we can’t use regular gradient methods to optimize it.
- The hinge loss has a region where it is strictly 0. This results in sparse estimates.
17.3.7 Multi-class classification with SVMs
SVMs are inherently binary classifiers.
One way to convert them to a multi-class classification model is to train binary classifiers, where the data from class is treated as positive, and the rest is negative.
We then predict the label by using the rule:
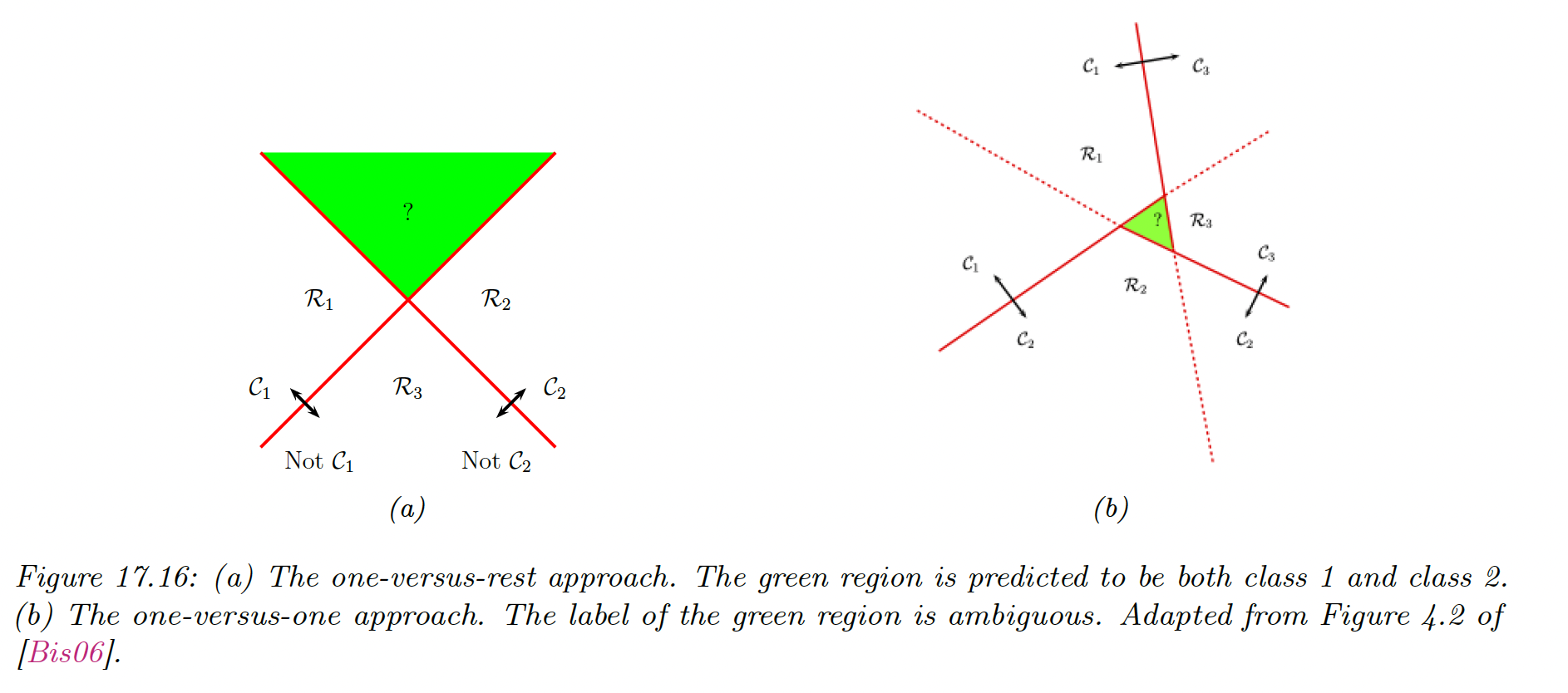
where . This is known as the one-vs-rest approach (aka one-vs-all).
Unfortunately, this has shortcomings:
- This can result in regions of input space where the predicted label is ambiguous
- The magnitude of the scores are not calibrated well with each other, so there are hard to compare.
- Each binary subproblem is likely to suffer from imbalance problem, which can hurt performances: for 10 equally represented classes, each positive class represents only 10% of labels.
We can also use the one-vs-one (OVO) approach, in which we train classifiers to discriminate all pairs . We then classify a point into a class that has the higher number of votes.
However this can also result in ambiguities, and this require fitting models.
17.3.8 How to choose the regularizer
SVMs require to specify the kernel function and the parameter , usually chosen with cross-validation.
Note however that interact quite strongly with kernel parameters, for example with precision .
- If is large, corresponding to narrow kernel, we may need heavy regularization, hence small
- If is small, a larger value of should be used.
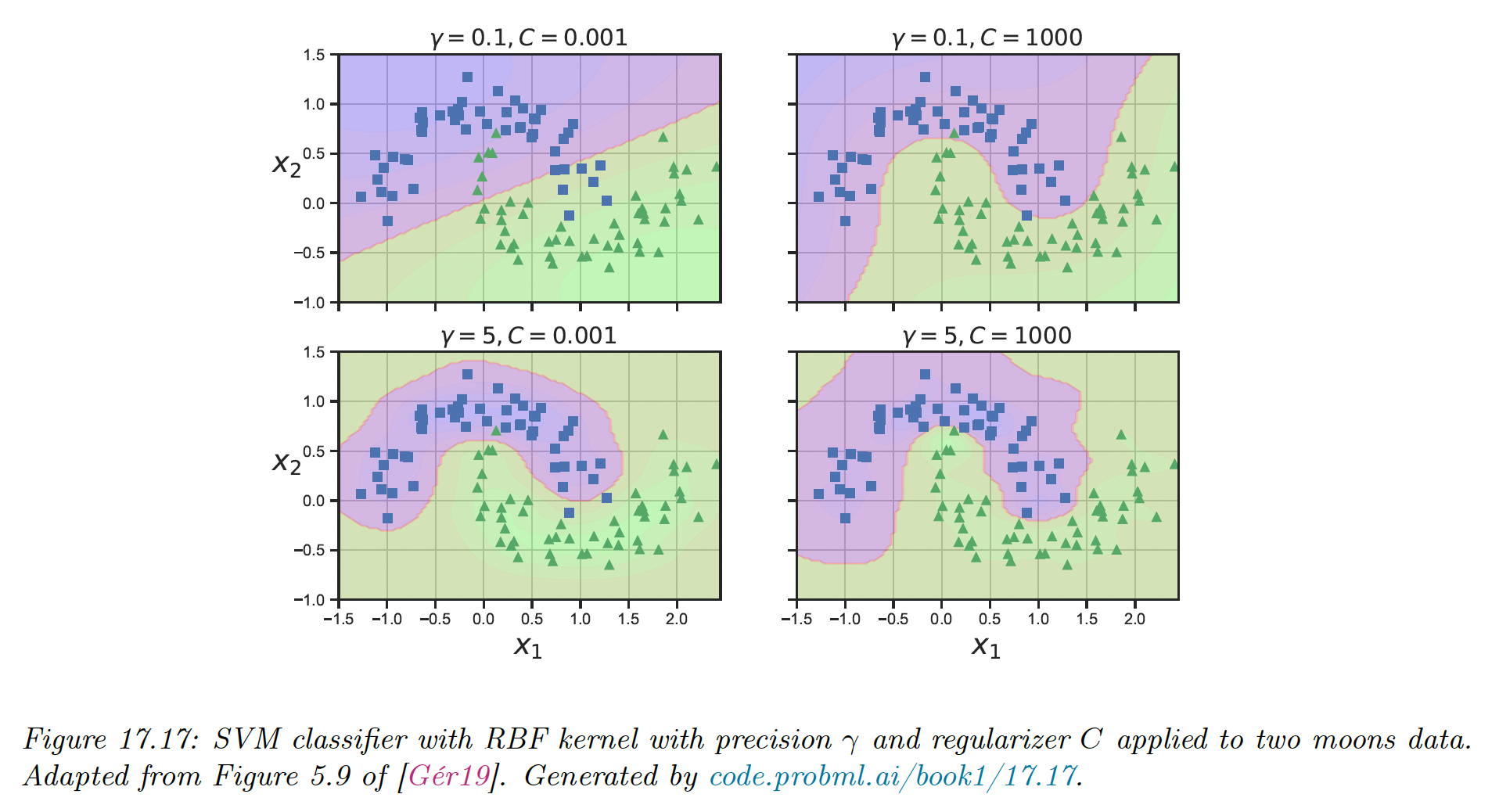
The authors of libsvm recommend using CV over a 2d grid with values and
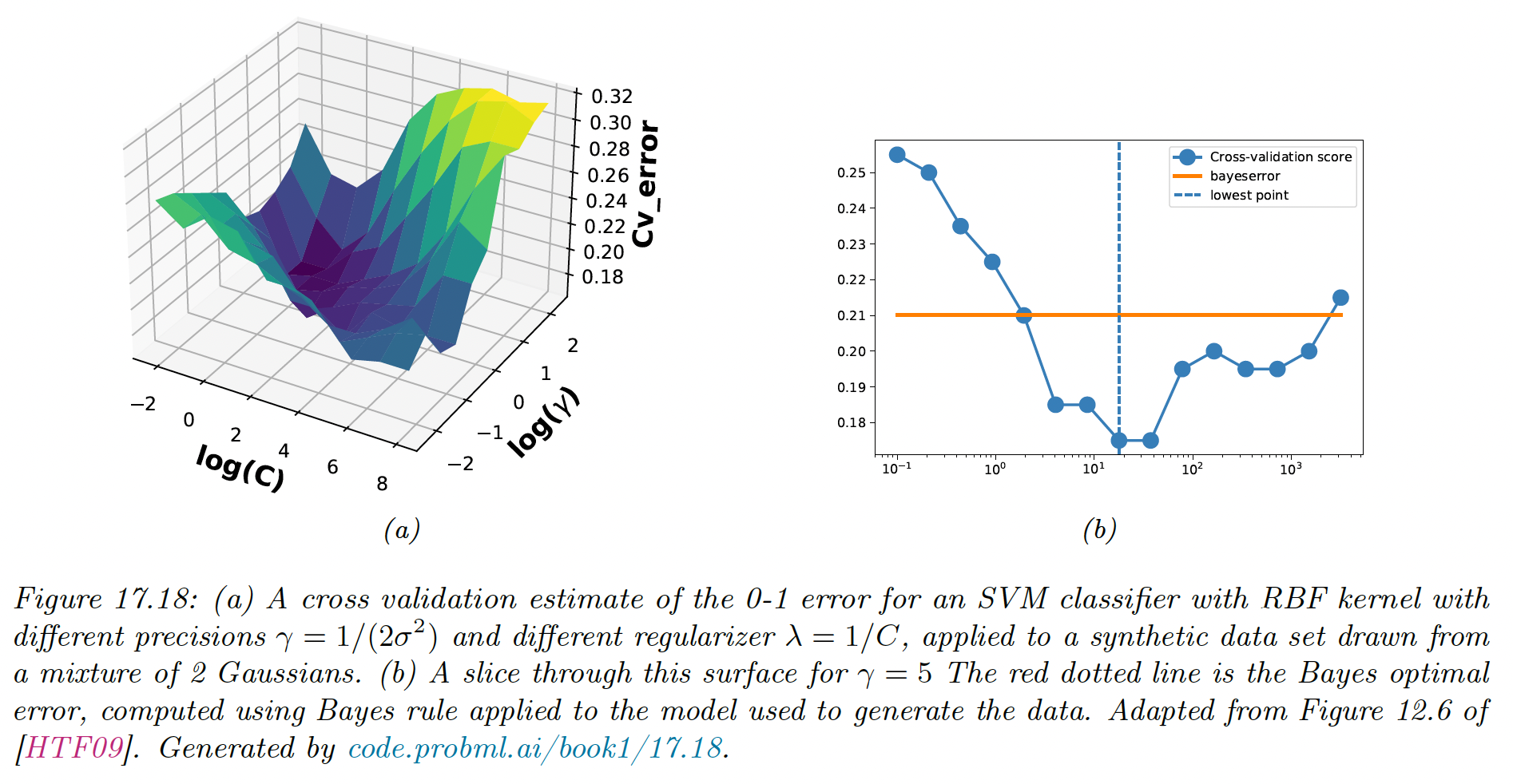
To choose efficiently, we can develop a path following algorithm similar to lars.
The idea is to start with a small so that the margin is wide and all points are inside it. By increasing , points will move from inside the margin to outside, and their value change from 1 to 0 as they cease to be support vectors. When is maximal, there are no support vectors left.
17.3.9 Kernel ridge regression
The ridge regression equation is:
Using the matrix inversion lemma, we can rewrite the ridge estimate as follows:
Let’s now define the dual variables:
We can rewrite the primal variables as:
So, the solution vector is just a weighted sum of the N training vectors.
We plug this at test time to get the predictive mean:
where we used the kernel trick, with the dual parameter becoming:
In other words:
where .
This is called ridge kernel regression. The issue with this approach is that the solution vector is not sparse, so predictions at test time will take time.
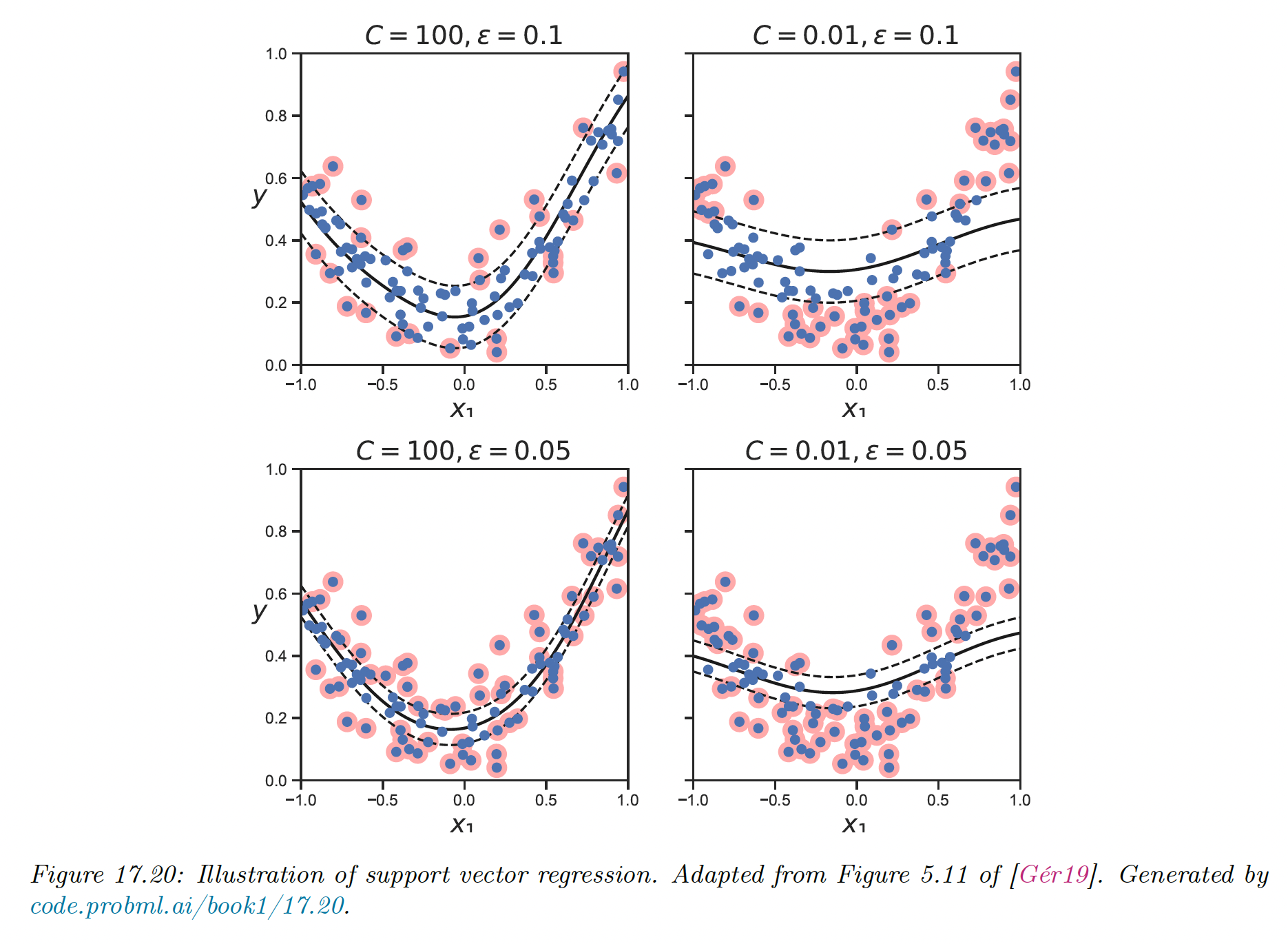
17.3.10 SVMs for regression
Consider the following -regularized ERM problem:
where .
If we use the quadratic loss, we recover ridge regression. If we then apply the kernel trick, we recover kernel ridge regression.
By changing the loss function, we can make the optimal set of basis coefficient sparse. In particular, consider the variant of the Huber loss function, the epsilon insensitive loss function:
This means any point lying in the -tube is not penalized.
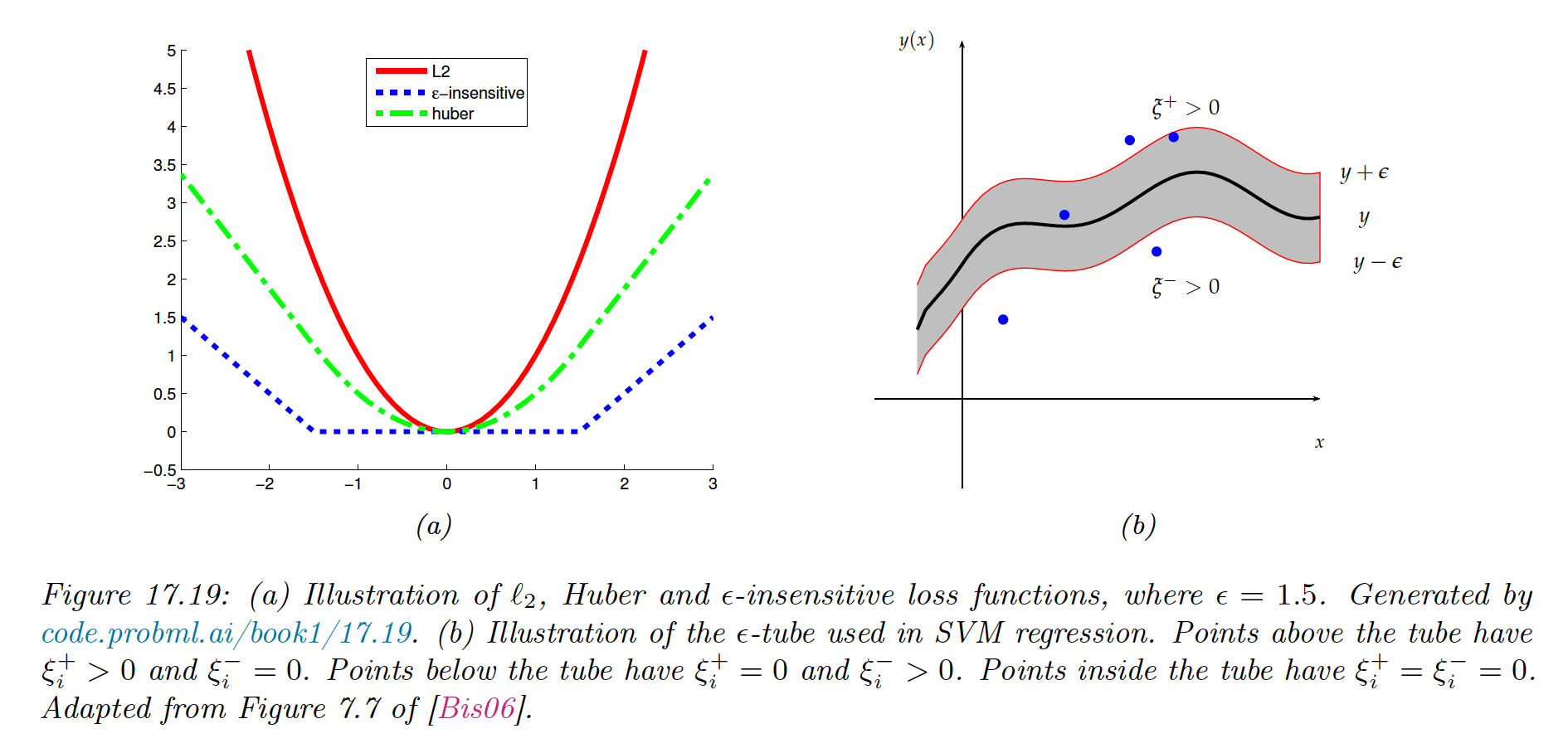
The corresponding loss function can be written:
where is a regularization constraint.
The objective is convex without constraint but not differentiable, because of the absolute value in the loss term. As for the lasso, there is several algorithm we could use.
One popular approach is to formulate the problem as a constraint optimization one. We introduce slack variables to represent the degree to which each point lies outside the tube:
We can rewrite the objective as:
This is a quadratic function of and must be minimized subject to the above constraint, as well as positive constraint on and .
This is a standard quadratic problem in variables. By forming the Lagrangian and optimizing as we did above, one can show that the optimal solution is:
where are the dual variables.
This time the vector is sparse, because the loss doesn’t care about errors smaller than The degree of sparsity is controlled by and
The for which are the sparse vectors, lying on or outside the tube. They are the only examples we need to keep since:
The overall technique is called SVM regression.