10.2 Binary Logistic Regression
Binary logistic regression corresponds to the following model:
where are the weights and bias. In other words:
and we call the log odds:
10.2.1 Linear classifiers
If the loss for misclassifying each class is the same, the class is given by:
with:
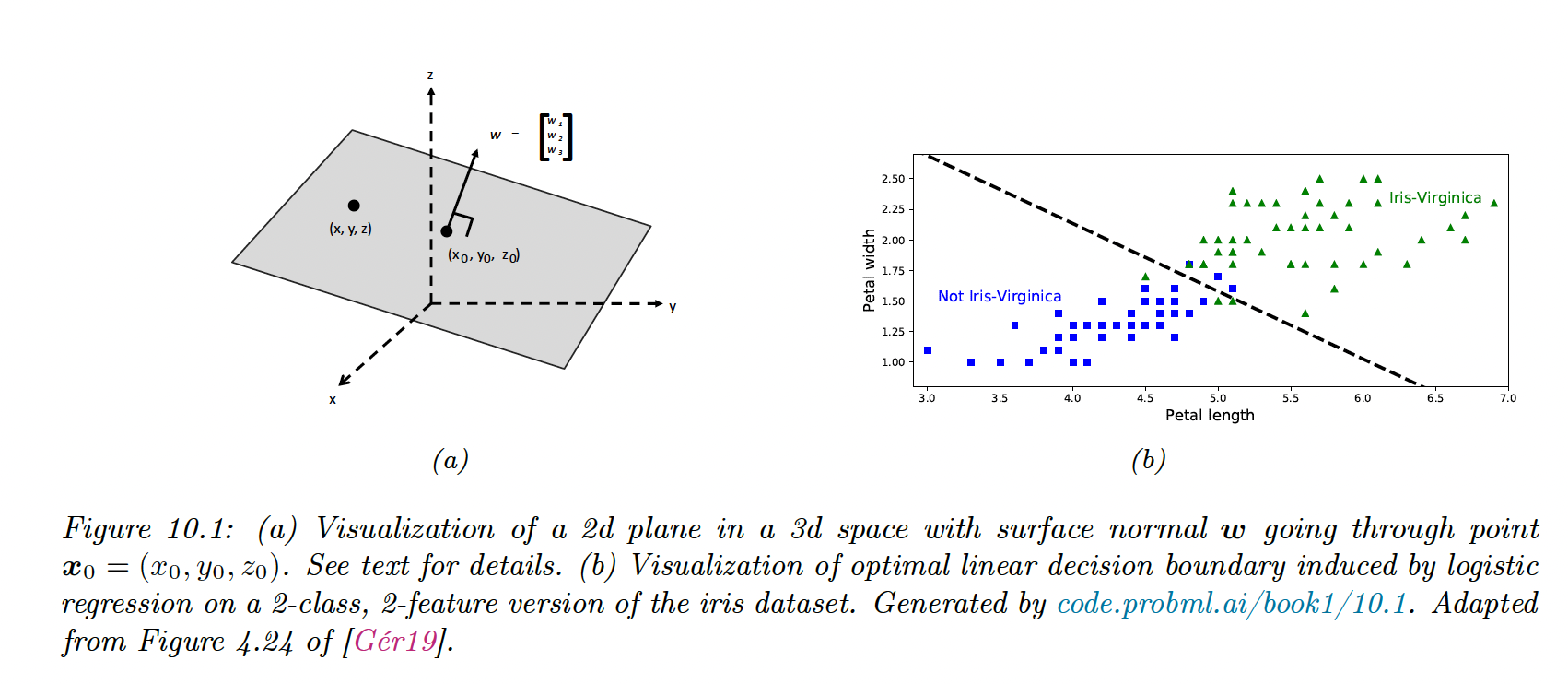
For and on the plan and the normal at , we have:
With
This defines the decision boundary between both classes.
10.2.2 Nonlinear classifiers
We can often make a problem linearly separable by preprocessing the input.
Let:
Then:
which is the decision boundary of a circle.
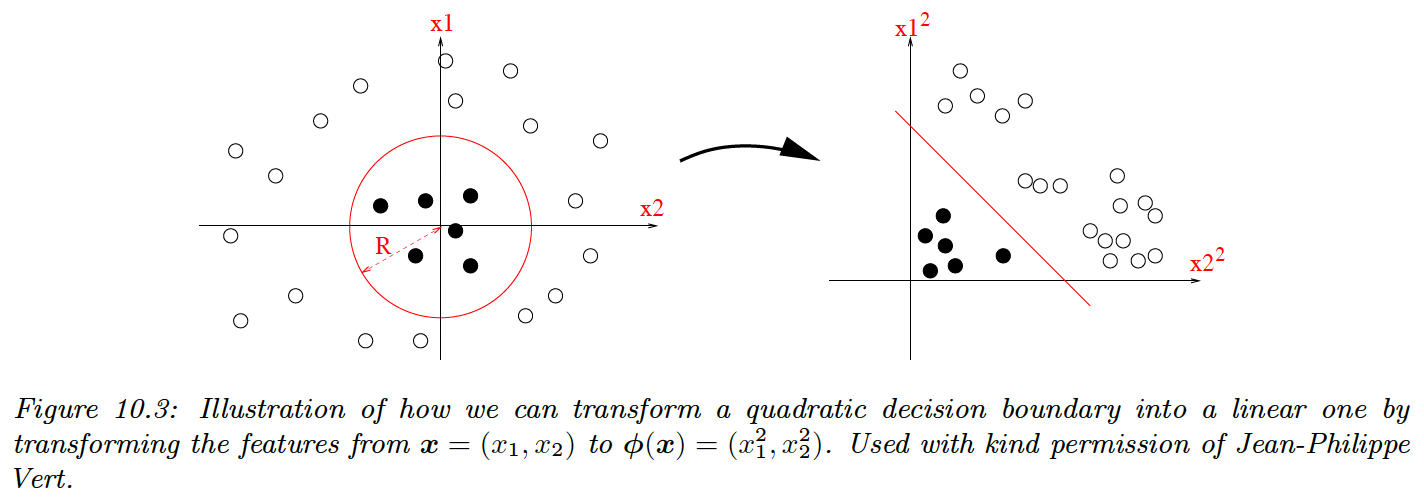
The resulting function is still linear, which simplifies the learning process, and we gain power by learning the parameters of . We can also use polynomial expansion up to the degree , the model becomes more complex and risk overfitting.
10.2.3 Maximum Likelihood Estimation
10.2.3.1 Objective function
where is the probability of class 1
10.2.3.3 Deriving the gradient
Then, we compute:
We plug it back into the previous equation:
10.2.3.4 Deriving the Hessian
Gradient-based optimizers will find a stationary point where , either a global or local optimum.
To be sure the optimum is global we must show that the objective is convex, by showing that the Hessian is semi-positive definite:
With
We see that is positive definite since for all non-zero vector we have:
This follows since for all , because of the sigmoid function.
Consequently, the NLL is strictly convex, however in practice, values of close to 0 and 1 might cause the Hessian to be singular. We can avoid this by using regularization.
10.2.4 Stochastic gradient descent
We can use SGD to solve the equation:
where the loss here is the NLL.
If we use a mini-batch of size 1, we have:
Since we know the objective is convex we know this will converge to the global optimum, provided we decay the learning rate appropriately.
10.2.5 Perceptron Algorithm
A perceptron is a binary classifier:
This can be seen as a modified logistic regression, where the sigmoid is replaced by a Heaviside function. Since the Heaviside is not differentiable, we can’t use gradient-based optimization to fit the model.
Rosenblatt proposed a perceptron learning algorithm, where we only make updates for wrong predictions (we replaced soft probabilities with hard labels):
- If and , the update is
- If and , the update is
The advantage of Perceptron is that we don’t need to compute probabilities, which is useful when the label space is vast.
The disadvantage is that this method will only converge if the data is linearly separable, whereas SGD for minimizing the NLL will always converge to the globally optimal MLE.
In section 13.2, we will generalize perceptrons to nonlinear functions, enhancing their usefulness.
10.2.6 Iteratively weighted least square
Being a first-order method, SGD can be slow, especially when some directions point steeply downhill, while others have a shallow gradient.
In this situation, it can be much faster to use second-order methods that take the curvature of the space into account. We focus on the full batch setting (with small) since it is harder to make second-order methods work in the stochastic setting.
The hessian is assumed to be positive-definite to ensure the update is well-defined.
If the hessian is exact, the learning rate can be set to 1:
with:
and:
Since is diagonal, we can rewrite:
The optimal weight is a minimizer of:

Fisher scoring is the same as IRLS except we replace the Hessian with its expectation i.e. we use the Fisher information matrix. Since the Fisher information matrix is independent of the data, it can be precomputed. This can be faster for problems with many parameters.
10.2.7 MAP estimation
Logistic regression can overfit when the number of parameters is high compared to the number of samples. To get this wiggly behavior, the weight values are large (up to +/-50 compared to 0.5 when K=1).
One way to reduce overfitting is to prevent weights from being so large, is performing MAP estimation using a zero mean Gaussian prior:
The new objectives and gradient takes the form:
10.2.8 Standardization
Using the previous isotropic prior assumes that all weights are of the same magnitudes, which assumes features are of the same magnitudes as well.
To enforce that hypothesis, we can use standardization:
An alternative is min-max scaling, ensuring that all inputs lie within the interval .