4.4 Other estimation methods
4.4.1 The methods of moment (MOM)
MOM is a simpler approach than computing MLE. Solve number of equations ( is the number of parameters).
- The theoretical moments are given by
- The empirical moments are given by
We solve for every k.
Example with the univariate Gaussian:
(since )
so:
So in this case, this is similar to MLE.
Example with the uniform distribution:
Inverting these equations to get and , we see that these estimators sometimes give incorrect results.
To compute the MLE, we sort the data values. The likelihood is:
Then, if we set
This is minimized by and , as one would expect.
4.4.2 Online (recursive) estimation
When data arrives sequentially we perform online learning.
Let our estimate (e.g. MLE) given . To ensure our algorithms takes a constant time per update, our solution is in the form:
Example for the mean of Gaussian:
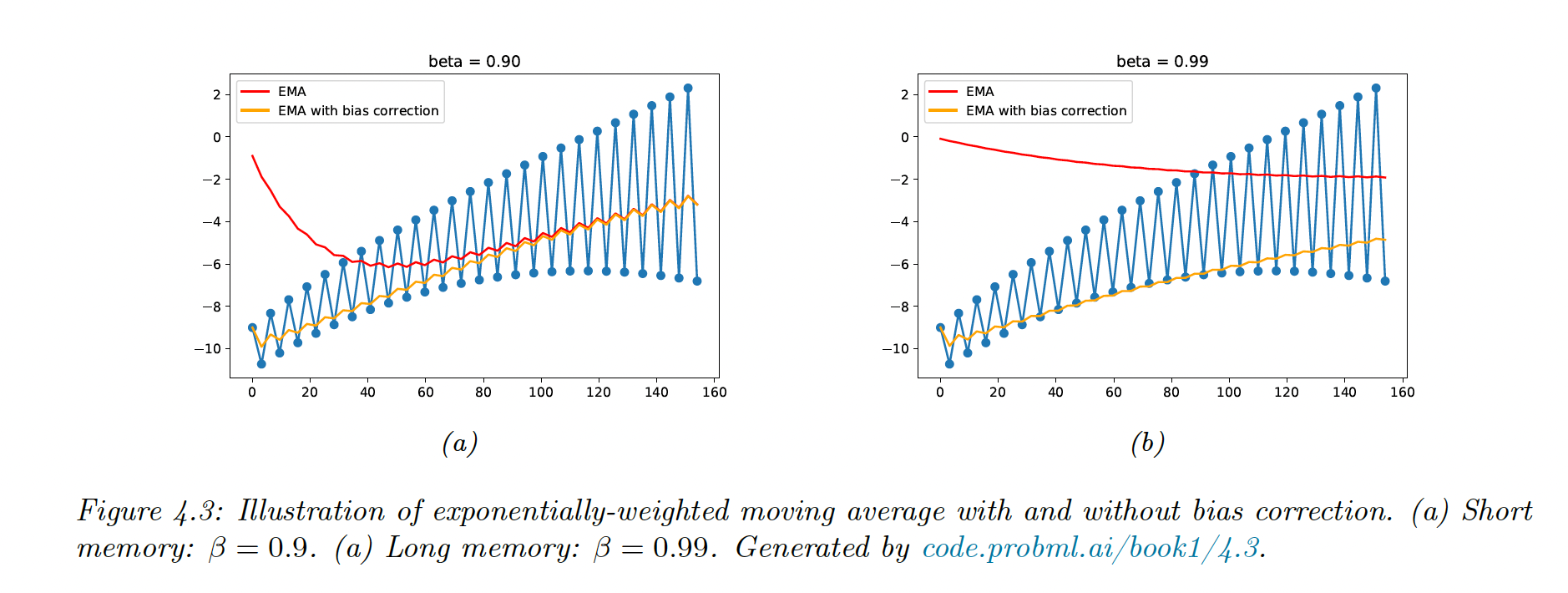
This is a moving average, the size of the correction diminish over time. However if the distribution is changing, we might want to give more weight to recent data points.
This is solved by exponentially-weighted moving average (EWMA)
with
The contribution of a data point in k steps is .
Since the initial estimate starts from there is an initial bias, corrected by scaling as