5.5 Frequentist hypothesis testing
The Bayes factor is expensive to compute since it requires integrating over all parametrization of model and . It’s also sensitive to the choice of prior.
5.5.1 Likelihood ratio test
If we use 0-1 loss, and assume that , then the optimal decision rule is to accept if:
Gaussian means
If we have two Gaussian distributions with and and known shared variance , the likelihood ratio test is:
Thus the test only depends on the observed data on the sufficient statistic . From the figure below, we see that we accept if :
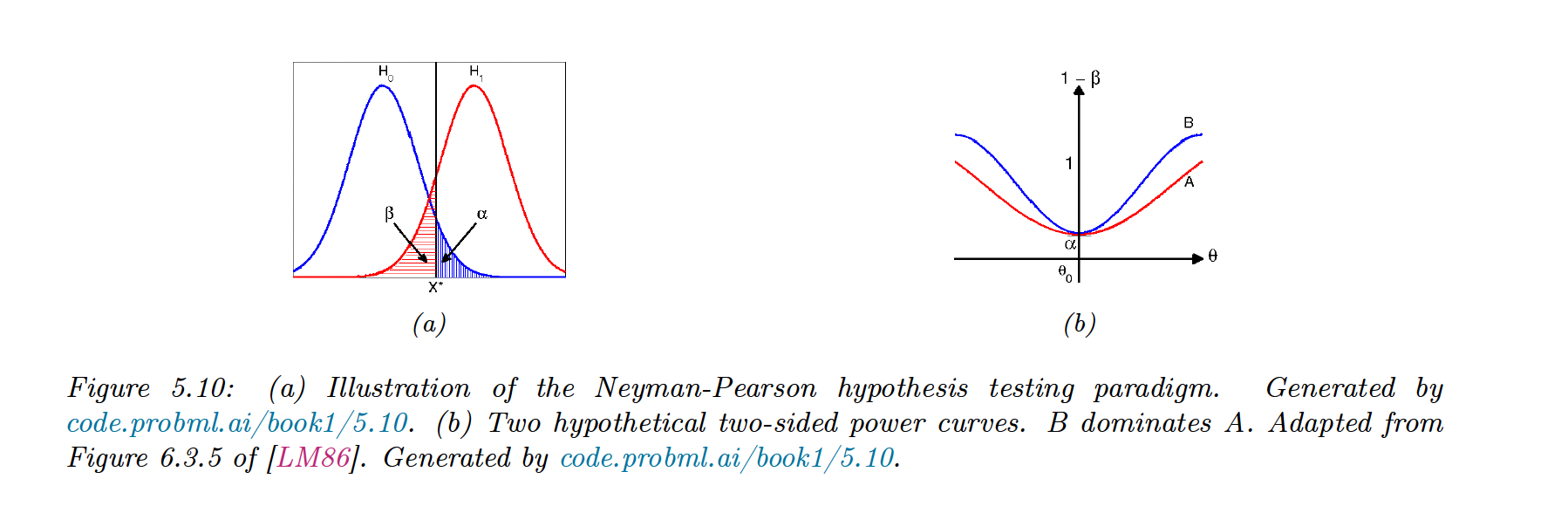
Simple vs compound parameters
In our simple hypothesis test above, parameters were either specified () or shared ().
A compound hypothesis doesn’t specify all parameters, and we should integrate out these unknown parameters like in the Bayesian hypothesis testing:
As an approximation, we can maximize them out, giving the maximum likelihood ratio.
5.5.2 Null hypothesis significance testing (NHST)
Instead of assuming the 0-1 loss, we design a decision rule with a false positive (error type I) probability of , called the significance of the test.
In our Gaussian example:
Hence:
with the upper -quantile of the standard Normal.
Let’s be the false negative error (error type II) probability:
The power of a test is , it is the probability of rejecting when is true
The least power occurs when the two Gaussian overlap:
When , for the same type I error, dominates .
5.5.3 p-values
Rather than arbitrarily declaring a result significant or not, we compute its p-value:
If we accept hypothesis where , then 95% of the time we will correctly reject . However, it doesn’t mean that is true with probability 0.95.
That quantity is given by the Bayesian posterior
5.5.4 p-values considered harmful
The frequent and invalid reasoning about p-value is:
“If is true, then this test statistic would probably not occur. This statistic did occur, therefore is false“.
This gives us: “If this person is American, he is probably not a member of congress. He is a member of Congress. Therefore he is probably not American”
This is induction: reasoning backward from observed data to probable causes, using statistics regularity and not logical definitions. Logic usually works with deduction: .
To perform induction, we need to compute the probability of :
when the prior is uniform with and the likelihood ratio .
If “being an American” is and “being a member of Congress” is , then is low, and is zero, thus the probability of is 1, which follows intuition.
The NHST ignores and also , hence the wrong results. This is why p-values can be much different from .

Which is far greater that the 5% probability people often associate with a p-values of
5.5.5 Why isn’t everyone a Bayesian?
The frequentist theory yields counter-intuitive results because it violates the likelihood principle, saying that inference should be made based on prior knowledge, not on some unseen future data.
Bradley Efron wrote Why isn’t everyone a Bayesian (opens in a new tab), stating that if the 19th century was Bayesian and the 20th frequentist, the 21th could be Bayesian again.
Some journals like The American Statistician have already banned or warn against p-values and NHST.
Computation has traditionally been a major road block for Bayesian, which is less of an issue nowadays with fast algorithms and powerful computers.
Also, the Bayesian modeling assumptions can be restraining, but this is true as well for the Frequentist since sampling distribution relies on some hypothesis about data generation.
We can check models empirically using cross-validation, calibration and Bayesian model checking.