15.6 Efficient transformers
Regular transformers takes in time and space complexity, for a sequence of length , which makes them impracticable for long sequences.
To bypass this issue, various efficient variants have been proposed.
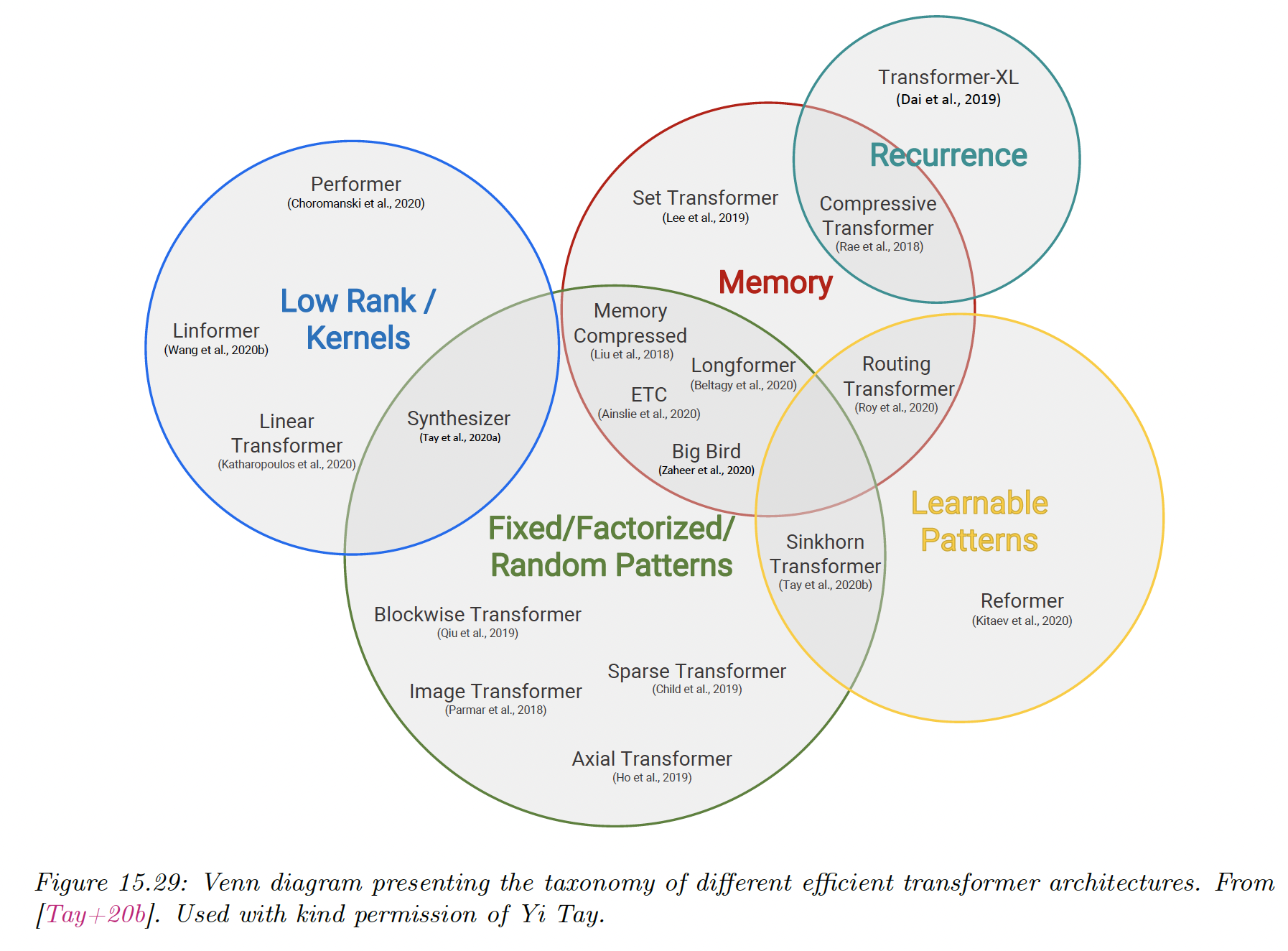
15.6.1 Fixed non-learnable localized attention patterns
The simplest modification of the attention mechanism is to restrain it to a fixed non-learnable localized window.
We chunk a sentence into blocks of size , and attention is performed only in each blocks. This gives a complexity of .
If this can give a substantial computational improvement.
Other approaches leverage strided/dilated windows, or hybrid patterns, where several fixed attention patterns are combined together.
15.6.2 Learnable sparse attention patterns
A natural extension of the above is to use learnable attention patterns, with the attention still restricted to pairs of token within a single partition. We distinguish the hashing and clustering approaches.
In the hashing approach, all tokens are hashed and the partitions correspond to the hashing-buckets. This is how the Reformer uses locality sensitive hashing (LSH), with a complexity of where is the dimension of tokens’ embeddings.
This approach requires to set of queries to be identical to the set of keys, and the number of hashes used for partitioning can be a large constant.
In the clustering approach, tokens are clustered using standard algorithms like K-Means. This is known as the clustering transformer. As in the block-case, if equal sized blocks are used, the complexity of the attention module is reduced to .
In practice, we choose , yet imposing the clusters to be similar in size is difficult.
15.6.3 Memory and recurrence methods
In some approaches, a side memory module can be used to access several tokens simultaneously. This method has the form of a global memory algorithm.
Another approach is to connect different local blocks via recurrence. This is used by Transformer-XL methods.
15.6.4 Low-rank and kernel methods
The attention matrix can be directly approximated by a low rank matrix, so that:
where with .
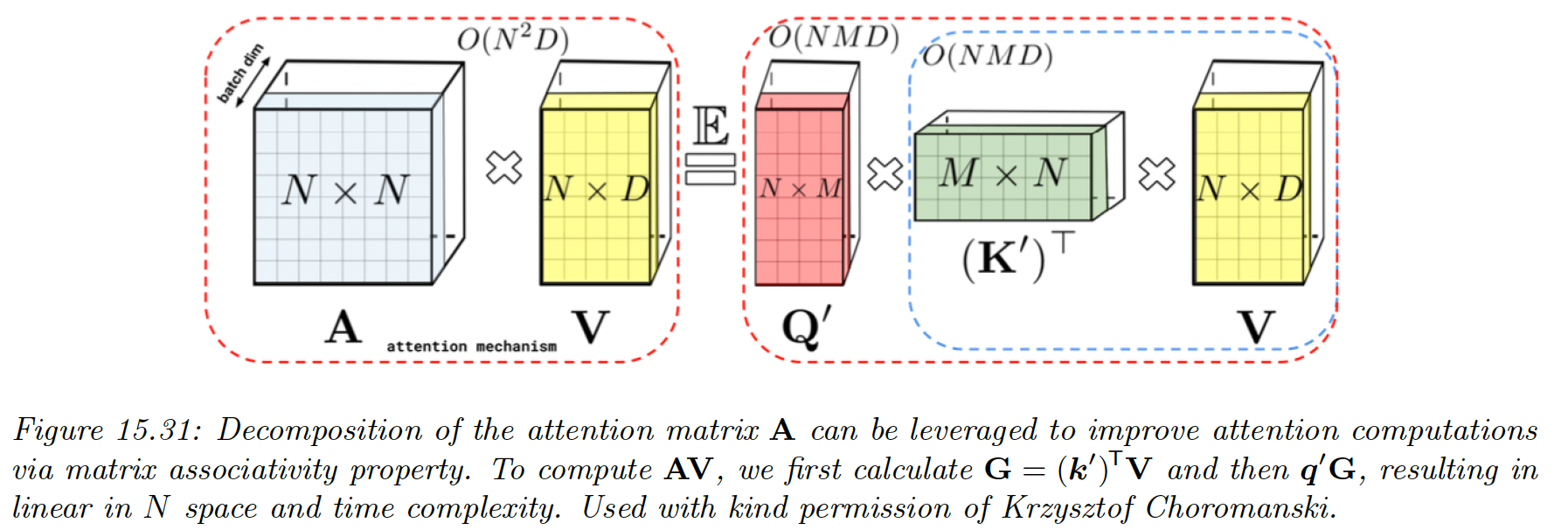
We can then exploit this structure to compute in time. Unfortunately, for softmax attention, is not low rank.
In Linformer (opens in a new tab), they transform the keys and values via random Gaussian projection. Then, they approximate the softmax attention in this lower dimensional space using the Johnson-Lindenstrauss Transform.
In **Performer (opens in a new tab),** they show that the attention matrix can be computed using a (positive definite) kernel function:
The first term is equal to , where:
and the two other terms are independent scaling factors.
To gain a computational advantage, we can show that the Gaussian kernel can be written as the expectation of a set of random features:
where is a random feature vector derived from , either from trigonometric or exponential functions (the latter ensure positivity of all features, which gives better results).
Therefore we can write:
where:
And we can write the full attention matrix as:
where have rows encoding random features corresponding to queries and keys. We can get better results by ensuring these random features are orthogonal.
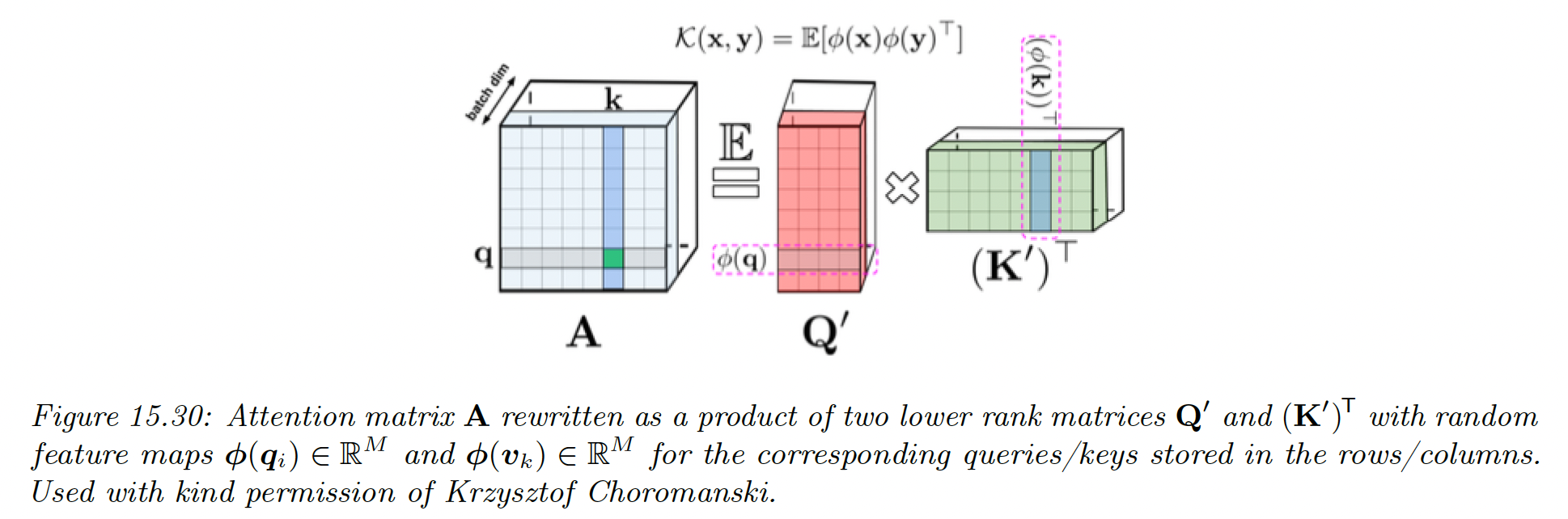
We can create an approximation of by sampling a single vector of the random features and , using a small value .
We can then approximate the entire attention operation with:
This is an unbiased estimate of the softmax attention operator.