14.4 Other forms of convolution
14.4.1 Dilated convolution
By using striding and stacking many layers of convolution together, we enlarge the receptive field of each neuron.
To cover the entire image with filters, we would need either many layers or a large kernel size with many parameters, which would be slow to compute.
Dilated convolution increases the receptive field without increasing the number of parameters:
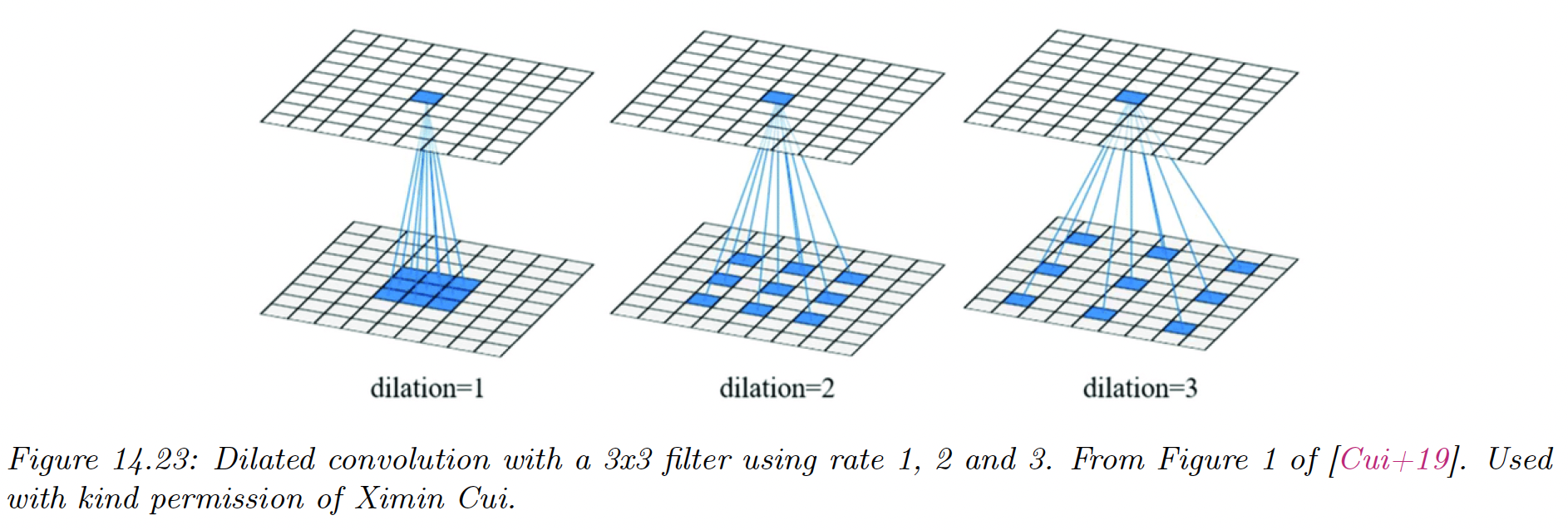
in comparison, regular convolution uses
14.4.2 Transposed convolution
Transposed convolution to the opposite of convolution, producing a larger output from a smaller input.
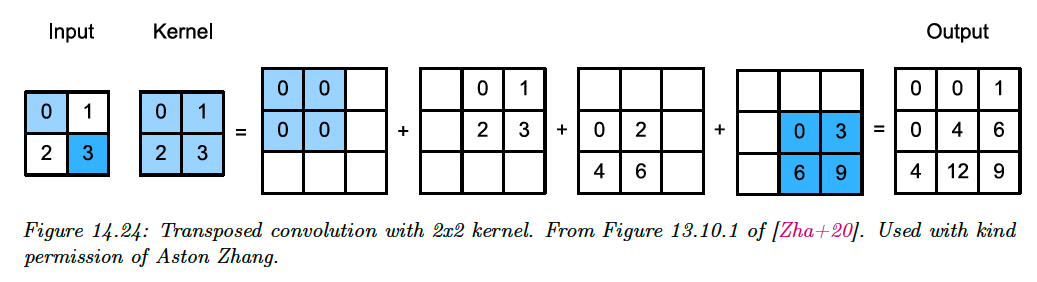
14.4.3 Depthwise separable convolution
Standard convolution uses a filter of size , requiring a lot of data to learn and a lot of time to compute with.
Depthwise separable convolution simplifies this operation by first applying 2d weight convolution to each input channel, then performing 1x1 convolution across channels:
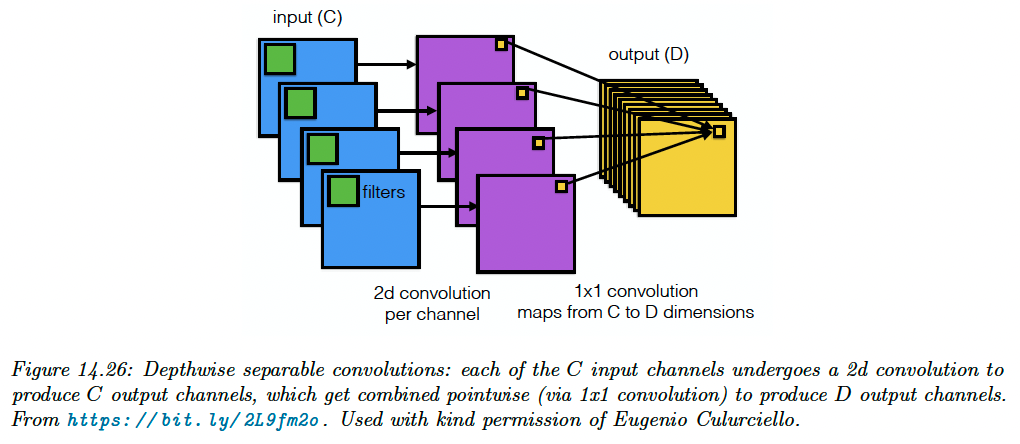
Compared to regular convolution, a 12x12x3 input with a 5x5x3x256 filter will be performed using:
- A 5x5x1x1 filter across space to get an 8x8x3 output
- A 1x1x3x256 filter across channels to get an 8x8x256 output
So, the output has the same size as before, with many fewer parameters.
For this reason, separable convolution is often used in lightweight CNN like MobileNet and other edge devices.