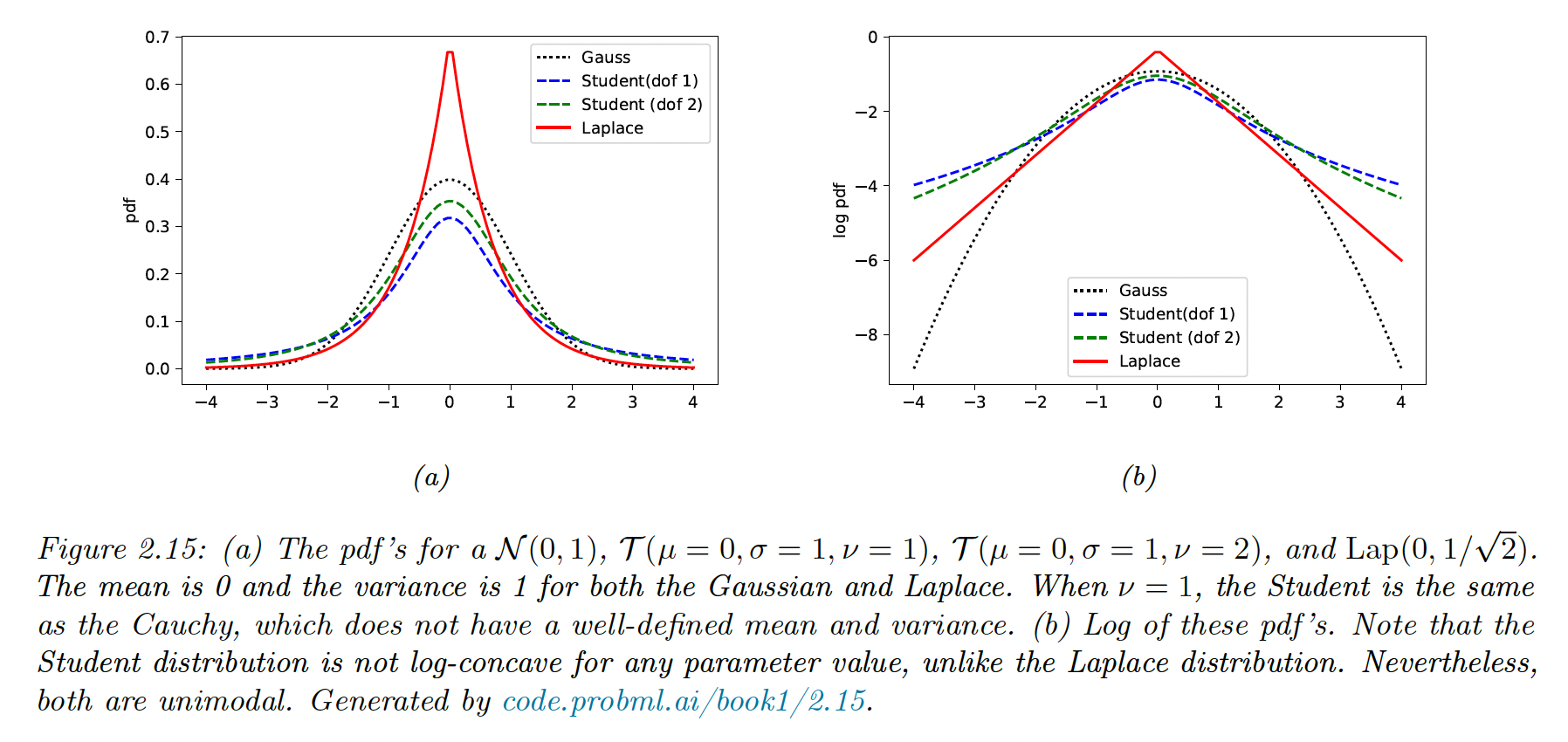
11.4 Lasso regression
In ridge regression, we assumed a Gaussian prior on the parameters, which is often a good choice since it leads to smaller parameters and limits overfitting.
However, sometimes we want the parameters to be exactly 0, i.e. we want to be sparse so that we minimize the norm:
This is useful because it can perform feature selection, as , if , the feature is ignored.
The same idea can be applied to non-linear models (like DNN) and encourage the first layer weight to be sparse.
11.4.1 MAP estimation using a Laplace prior ( regularization)
We now focus on MAP estimation using the Laplace prior:
where:
Laplace put more weight on 0 than Gaussian, for the same scale.
To perform MAP estimation of a linear regression model with this prior, we minimize the objective:
This method is called lasso “least absolute shrinkage and selection operator” or regularization.
Note we could also use the q-norm:
For , we can get even sparser solutions but the problem becomes non-convex. Thus, the norm is the tightest convex relaxation of the norm.
11.4.2 Why does the yields sparse solutions?
The lasso objective is a non-smooth objective that can be expressed with the Lagrangian:
where is an upper bound to the weight. A tight bound corresponds to a high .
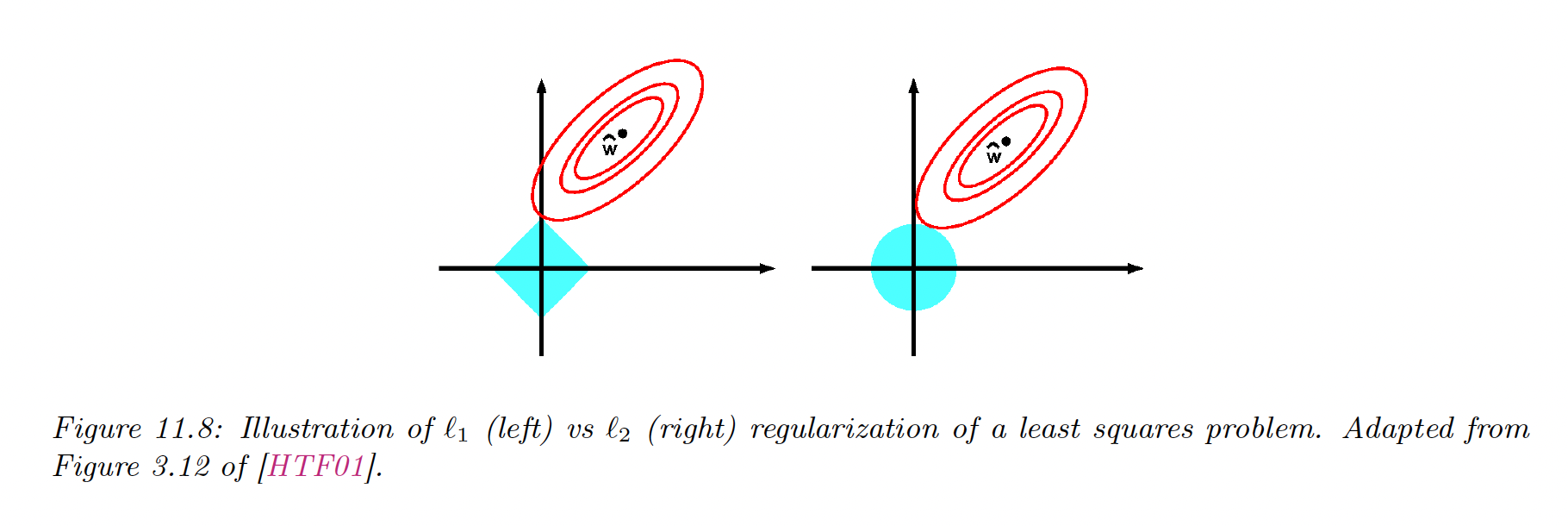
From the optimization theory, we know that the optimal solution lies at the intersection of the constraint surface and the lowest level of the objective function.
When we relax the constraint , we grow the constraint surface until reaching the objective. The dice is more likely to hit the objective function on the corner rather than on the side, especially in high dimensions. The corners correspond to the sparse solution, lying on the coordinate axes.
Meanwhile, there are no corners on the ball, it can intersect the objective function everywhere; there is no preference for sparsity.
11.4.3 Hard vs soft thresholding
One can show that the gradient for the smooth part is:
with:
where is without the component .
Setting the gradient to zero gives the optimal update for feature while keeping the other constant:
with the residuals error obtained by using all features but .
Let’s add the penalty term. Unfortunately, is not differentiable whenever . We can still compute the subgradient at this point.
Depending on the value of , the solution to can occur at 3 different values of as follows:
- If , the feature is strongly negatively correlated with the residual, then the subgradient is zero at
- If , the feature is weakly correlated with the residual, then the subgradient is zero at
- If , the feature is strongly correlated with the residual, the subgradient is zero at
In summary:
where:
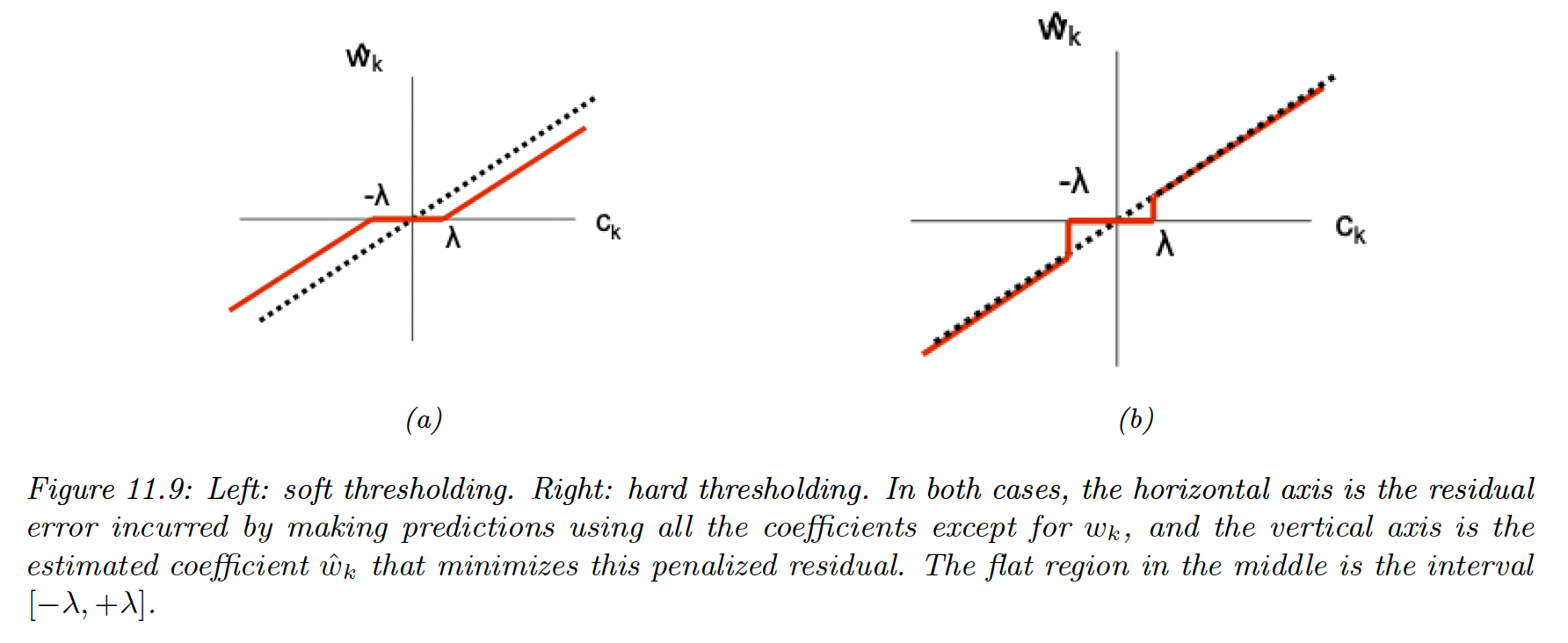
The slope of the soft-thresholding shrunk line doesn’t match the diagonal (the OLS), meaning that event big coefficients are shrunk to zero.
Consequently, Lasso is a biased estimator. A simple solution known as debiasing is to first estimate which elements are non-zero using lasso, then re-estimate the chosen coefficient using least squares.
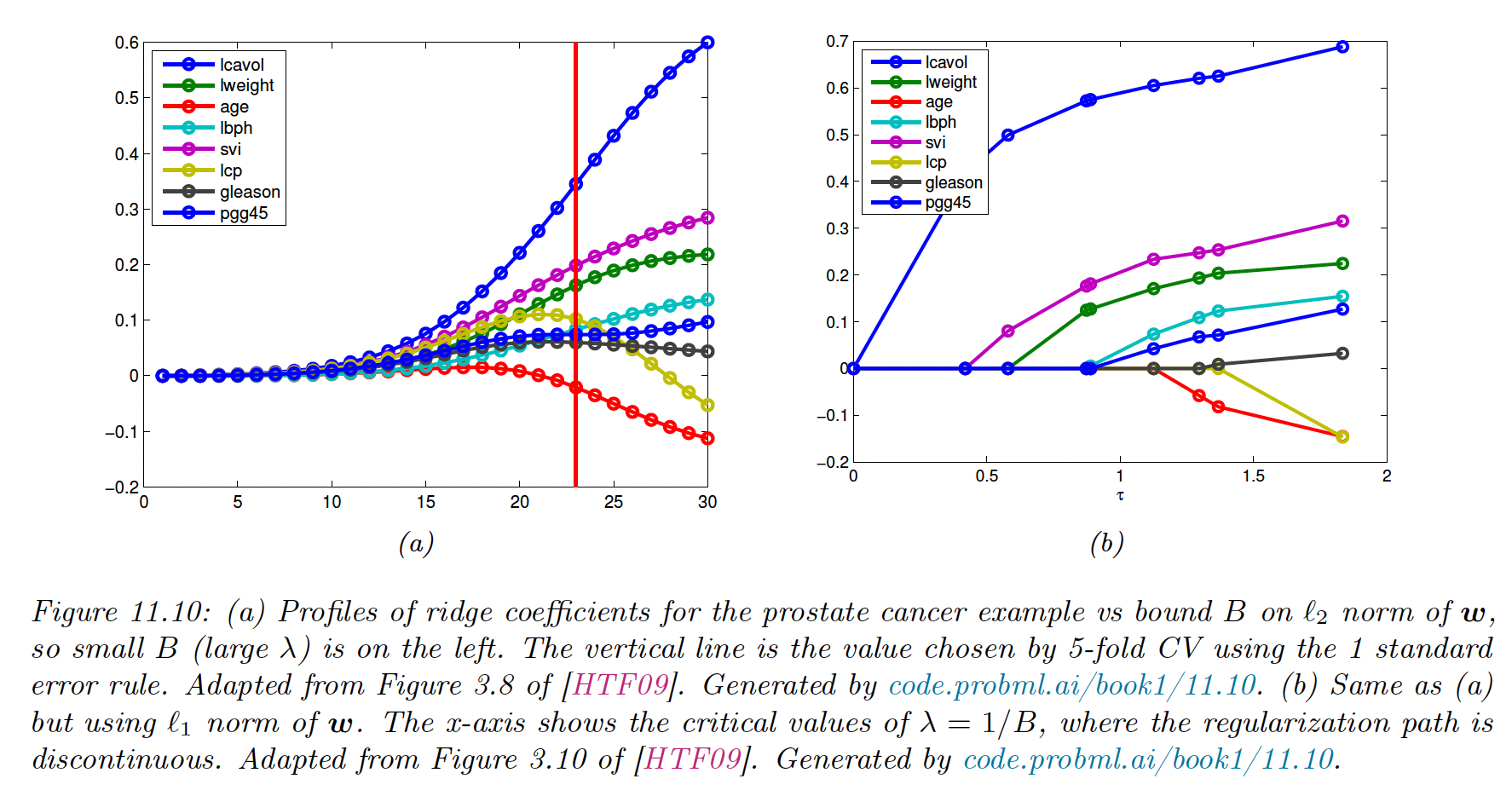
11.4.4 Regularization path
If , we get the OLS, which is dense. As we increase it, we reach where .
This value is obtained when the gradient of the NLL cancels out the gradient of the penalty:
As we increase , the solution vector get sparser, although not necessarily monotonically. We plot the regularization path:
11.4.6 Variable selection consistency
regularization is often used to perform feature selection. A method that can recover the true set of meaningful features when is called model selection consistent.
Let’s create:
- a sparse signal , consisting of 160 randomly placed spikes
- a random design matrix
- a noisy observation , with
with
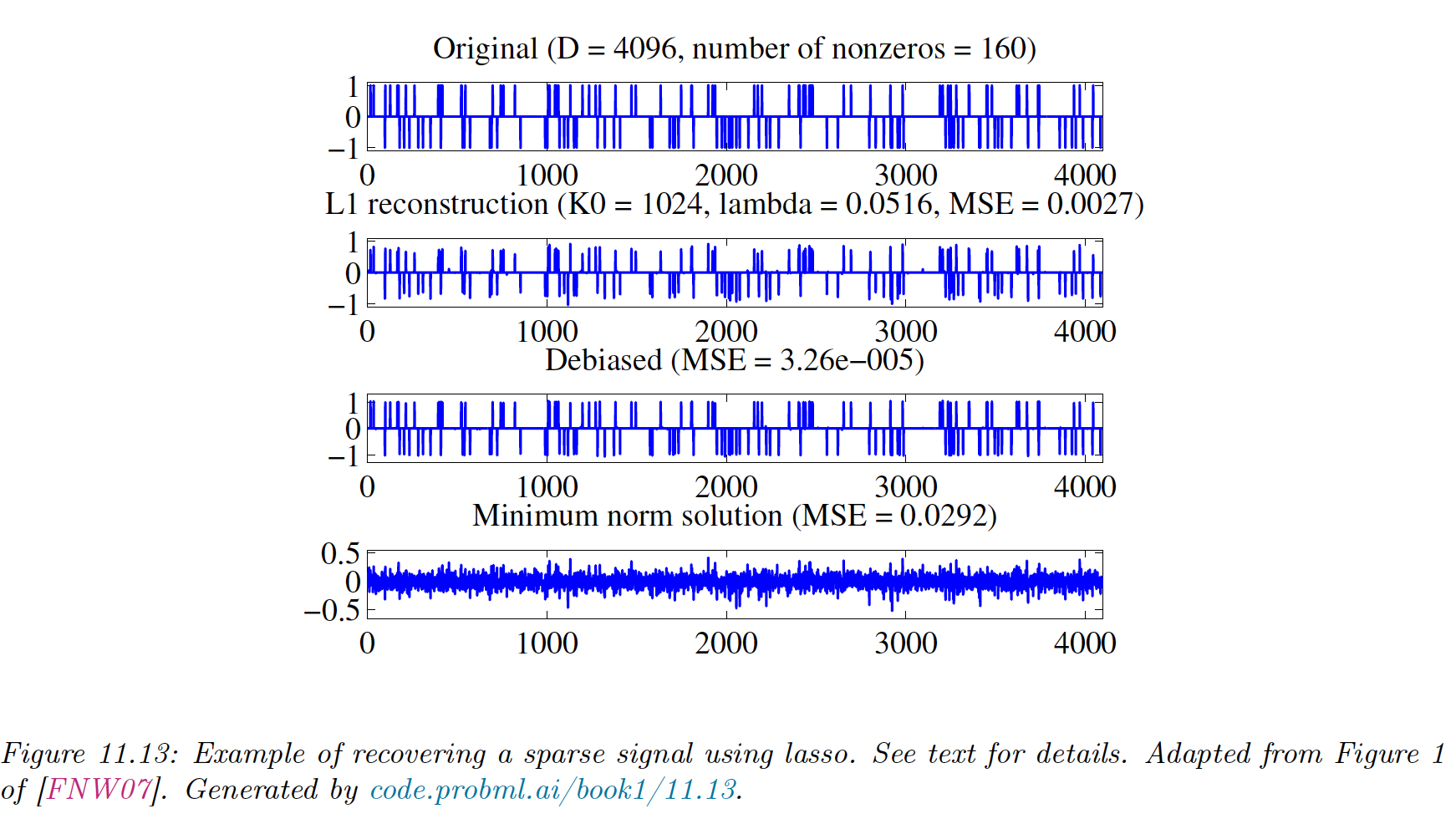
The second row is the estimate using . We see that it finds all coefficients , but they are too small due to shrinkage.
The third row uses the debiasing technique and recovers the right coefficient values.
By contrast, the last row represents the signal recovered by the OLS, which is dense.
To pick the optimal value of and perform the feature selection, we use cross-validation. It is important to note that CV will lead to good prediction accuracy, which is not necessarily the same as recovering the true model.
This is because Lasso performs selection and shrinkage i.e. the chosen coefficients are brought closer to , so the CV will pick a value of that is not too large. This will result in a less sparse model with irrelevant variables.
However, various extensions to the basic method have been designed that are model selection consistent. See Statistical Learning with Sparsity (2015) (opens in a new tab)
11.4.7 Group lasso
In standard regularization, we assume a 1:1 correspondence between a parameter and its variable. But in more complex settings, there may be many parameters associated with a single variable, so that each variable has its weight vector and the overall weight vector has a block structure .
To exclude the variable , we have to force the entire block to be : this is group sparsity.
11.4.7.1 Applications
- Linear regression with categorical inputs, where we use a one-hot-encoding vector of length
- Multinomial logistic regression: The ’th variable will be associated with different weight (one per class)
- Multi-task learning, similarly each feature is associated with different weighs (one per output task)
- Neural networks: The ’th neuron will have multiple inputs, so we set all incoming weights to zero to turn it off. Group sparsity can help us learn the neural net structure.
11.4.8.1 Penalizing the two-norm
To encourage group sparsity, we partition the parameter vector into groups, then we minimize:
where is the two-norm of the group weight vector. If the NLL is least-squares, this method is the group lasso. Note that if we had the squared of the two norms, the model would be equivalent to ridge regression.
By using the square root, we are penalizing the radius of a ball containing the group weights: the only way for the radius to be small is if all elements are small too.
Another way to see why the two-norm enforces group sparsity is to consider the gradient of the objective. If we only have one group of two parameters:
- If is small, the gradient will be close to 1 and the will be shrunk to zero
- If is large, then if is small the gradient will be close to and will not get updated much.
11.4.8.2 Penalizing the infinity norm
A variant of this technique replaces the two-norm with the infinity norm:
This will also result in group sparsity, since if the largest element of the group is forced to zero, all the others will be zero.
We have a true signal , with , divided into 64 groups of size 64.
We randomly pick 8 groups and assigned them to non-zero values.
We generate a random design matrice and compute like before.
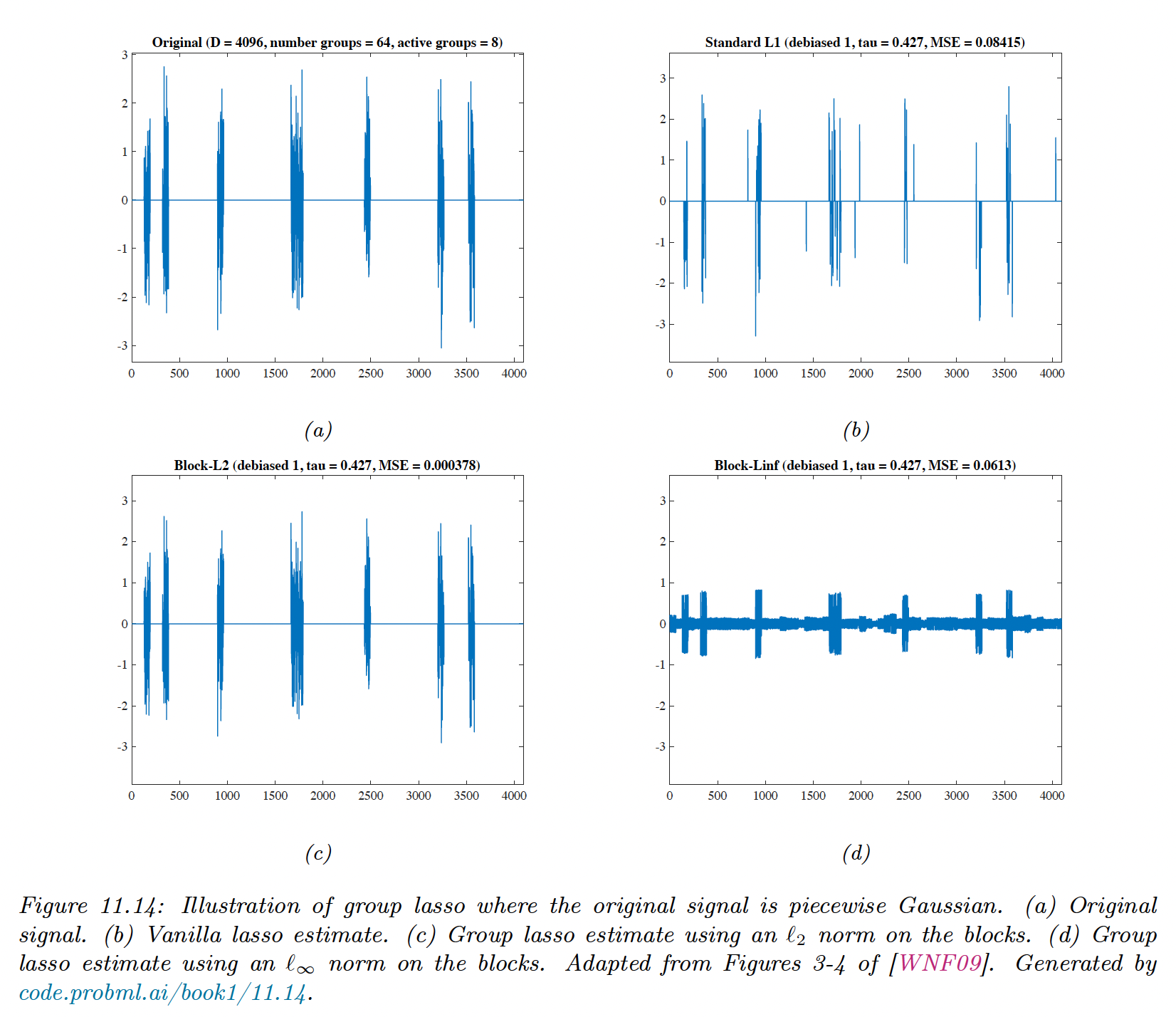
We see that the group lasso (c) does a much better job than vanilla lasso (b). With the norm, elements of the same groups have similar magnitude.
11.4.8 Elastic net (ridge and lasso combined)
In group lasso, we need to specify the structure ahead of time. For some problems, we don’t know the group structure, and yet we would still like highly correlated coefficients to be treated as an implicit group.
Elastic net can achieve this, named after being “like a stretchable fishing net that retains all the big fish”. It has the following objective:
This is strictly convex (assuming , so there is a unique global minimum, even if is not full rank.
It can be shown that any strictly convex penalty on will exhibit a group effect, and coefficients of highly correlated variables will be the same.
If two features are identically equal, so , one can show that their estimate .
By contrast with Lasso, we might have , and and vice versa. Resulting in less stable estimates.
Also, when , lasso can only select up to non-zero coefficients, while elastic net doesn’t have such limits, thus exploring more subsets of variables.
11.4.9 Optimization algorithms
Below, we expand on the method used to solve the lasso problem and other -regularized convex objectives.
11.4.9.1 Coordinate descent
Sometimes, it’s easier to optimize all variables independently. We can solve for the th coefficient while keeping all others constant.
We can either loop through all variables, select them at random, or update the steepest gradient. This approach has been generalized to GLM with the glmnet library.

11.4.9.2 Projected gradient descent
We convert the non-differentiable penalty into a smooth regularizer. We use the split variable trick
where and
Thus we get the smooth but constrained optimization problem:
In the case of Gaussian likelihood, the NLL is the least square loss, and the objective becomes a quadratic program (see section 8.5.4).
One way to solve this is to use projected gradient descent (see section 8.6.1). We can enforce the constraint by projecting onto the positive orthant, using . This operation is denoted .
The projected gradient update takes the form:
where is the unit vector of all ones.
11.4.9.3 Proximal gradient descent
Proximal gradient descent can be used to optimize smooth function with non-smooth penalty, like the .
In section 8.6.2, we showed that the proximal gradient for the penalty corresponds to the soft thresholding. Thus the update is:
Where the soft threshold is applied element-wise. This is called the iterative soft threshold algorithm (ITSA). If we combine it we Nesterov momentum, we get the fast ISTA or FISTA method, which is widely used to fit sparse linear models.
11.4.9.4 LARS
The Least Angle Regression and Shrinkage (LARS) generates a set of solutions for different , starting with an empty set up to a full regularization path.
The idea is that we can quickly compute from if , this is known as warm starting.
If we only want a single value , it can be more efficient to start from down to . This is known as the continuation method or homotopy.
LARS starts with a large that only selects the feature that is the most correlated to . Then, is decreased until finding a feature with a correlation of the same magnitude as the first, but with the residual, defined as:
where is the active set of features at step .
Remarkably, we can find the value of analytically, by using a geometric argument (hence “least angle”). This allows the algorithm to quickly jump where the next point of the regularization path where the active set changes.
This repeats until all variables are added.