4.6 Bayesian statistics
Inference is modeling uncertainty about parameters using a probability distribution (instead of a point estimate). In Bayesian statistics we use the posterior distribution.
Once we have computed the posterior over , we compute the posterior predictive distribution by marginalizing out . In the supervised setting:
This is Bayes model averaging (BMA), since we use an infinite amount set of models, weighted by how likely their parameters are.
4.6.1 Conjugate prior
A prior is conjugate for a likelihood function if the posterior . The family is closed under bayesian updating.
For simplicity, we consider a model without covariates.
4.6.2 Beta-binomial model
4.6.2.1 Bernoulli likelihood
We toss a coin times to estimate the head probability . We want to compute .
Under the iid hypothesis:
4.6.2.2 Binomial likelihood
Instead of observing a sequence of coin toss, we can count the number of heads using a binomial likelihood
Since these likelihood are proportional, we will use the same inference about for both models.
4.6.2.3 Prior
The Beta distribution is the conjugate prior to Bernoulli or Binomial likelihood.
4.6.2.4 Posterior
If we multiply the Bernoulli likelihood with the Beta prior, we obtained the following posterior:
Here the hyper-parameters of the prior play an similar role to the sufficient statistics . We call pseudo counts and observed counts.
4.6.2.5 Example
If we set , it would means that we have already observed 2 heads and 2 tails before we see the actual data. This is a weak preference for the value of (small update in figure (a) below).
If we set , the prior become . The prior is uninformative, so there is no update.
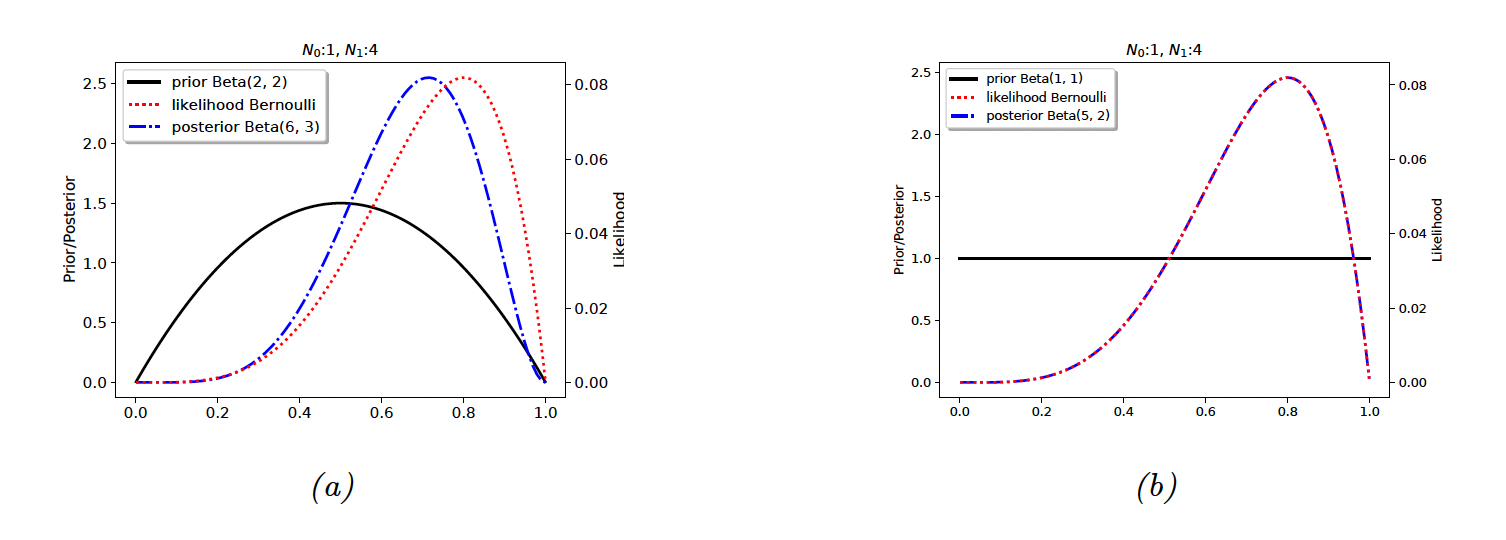
4.2.2.6 Posterior mode (MAP estimate)
Similarly to the MAP estimate already we saw in the regularization section, we have
If we use , we find back the add-one smoothing.
If we use , we have
4.6.2.7 Posterior mean
The posterior mean is a more robust estimation than the posterior mode since it integrates over the whole space (instead of a single point).
If , the posterior mean is:
with the strength of the posterior.
The posterior mean is a convex combination of the prior mean, and the MLE:
4.6.2.8 Posterior variance
The variance of a Beta posterior is given by:
Thus, the standard error of our estimate (aka the posterior variance) is:
4.6.2.9 Posterior predictive
For the Bernoulli distribution, the posterior predictive distribution has the form:
For the Binomial distribution, the posterior predictive distribution has the form of the Beta-Binomial distribution:
We plot in figure (a) below the posterior predictive distribution for , with a uniform prior .
(Remember that and )
We plot in figure (b) the plugin approximation, where is directly injected into the likelihood:
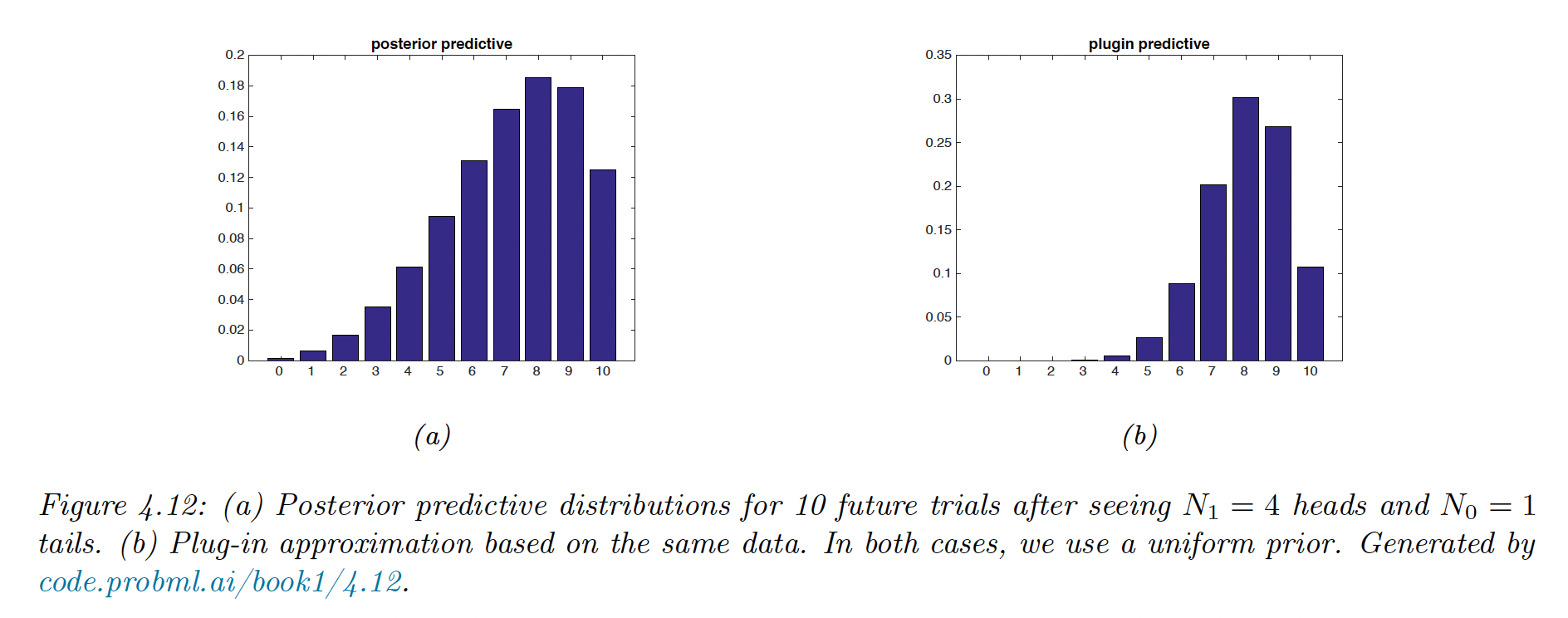
The long tail of the Bayesian approach is less prone to overfitting and Black Swan paradoxes. In both case, the prior is uniform, so this Bayesian property is due to the integration over unknown parameters.
4.6.2.10 Marginal likelihood
The marginal likelihood for a model is defined as:
Since it is constant in , it is not useful for parameter inference, but can help for model or hyperparameters selection (aka Empirical Bayes)
The marginal likelihood for the Beta Binomial is:
so
The marginal likelihood of the Beta Bernoulli is the same as above without the term.
4.6.2.11 Mixture of conjugate priors
Our current prior is rather restrictive. If we want to represent a coin that may be fair but also be equally biased towards head. We can use a Mixture of beta distributions:
We introduce meaning that comes from mixture , so the mixture prior is:
We can show that the posterior can also be written as a mixture of conjugate distributions:
where the posterior mixing weights are:
We can compute this quantity using the equation (40) of the marginal likelihood. If we observe heads and tails, the posterior is:
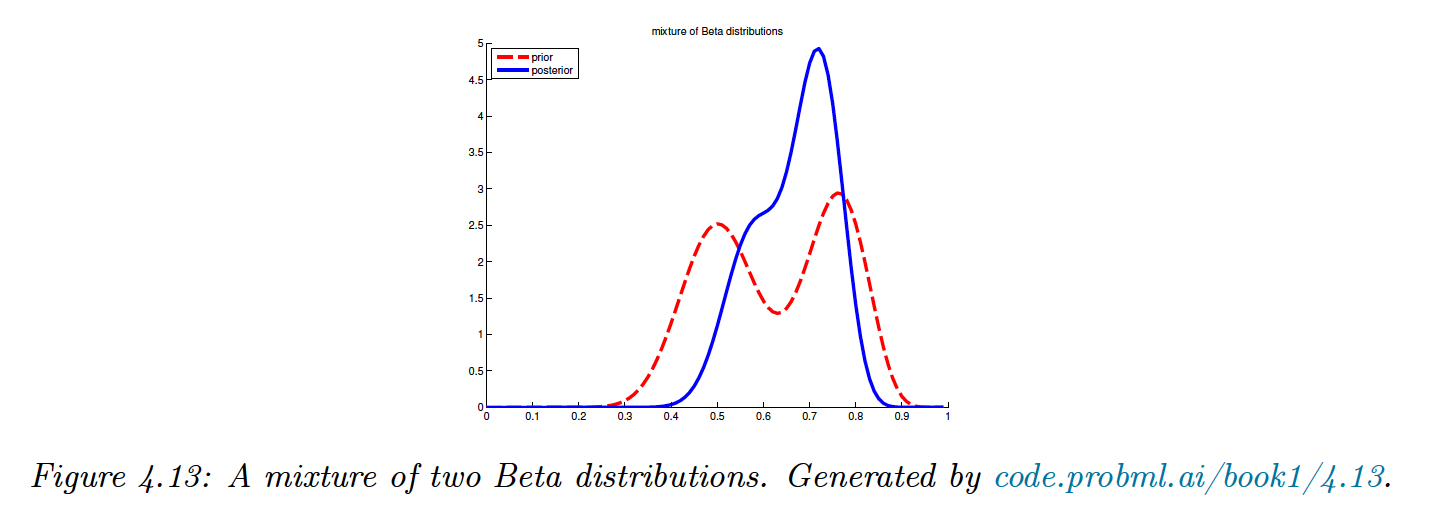
We can compute the probability that the coin is biased towards head:
4.6.3 The Dirichlet-multinomial model
We generalize the results from binary variable to categories (e.g. dice).
4.6.3.1 Likelihood
Let be a discrete random variable drawn from categorical distribution. The likelihood has the form:
4.6.3.2 Prior
The conjugate prior is a Dirichlet distribution, which is a multivariate of a beta distribution. It has support over the probability simplex:
The pdf of Dirichlet:
with the multivariate Beta function:
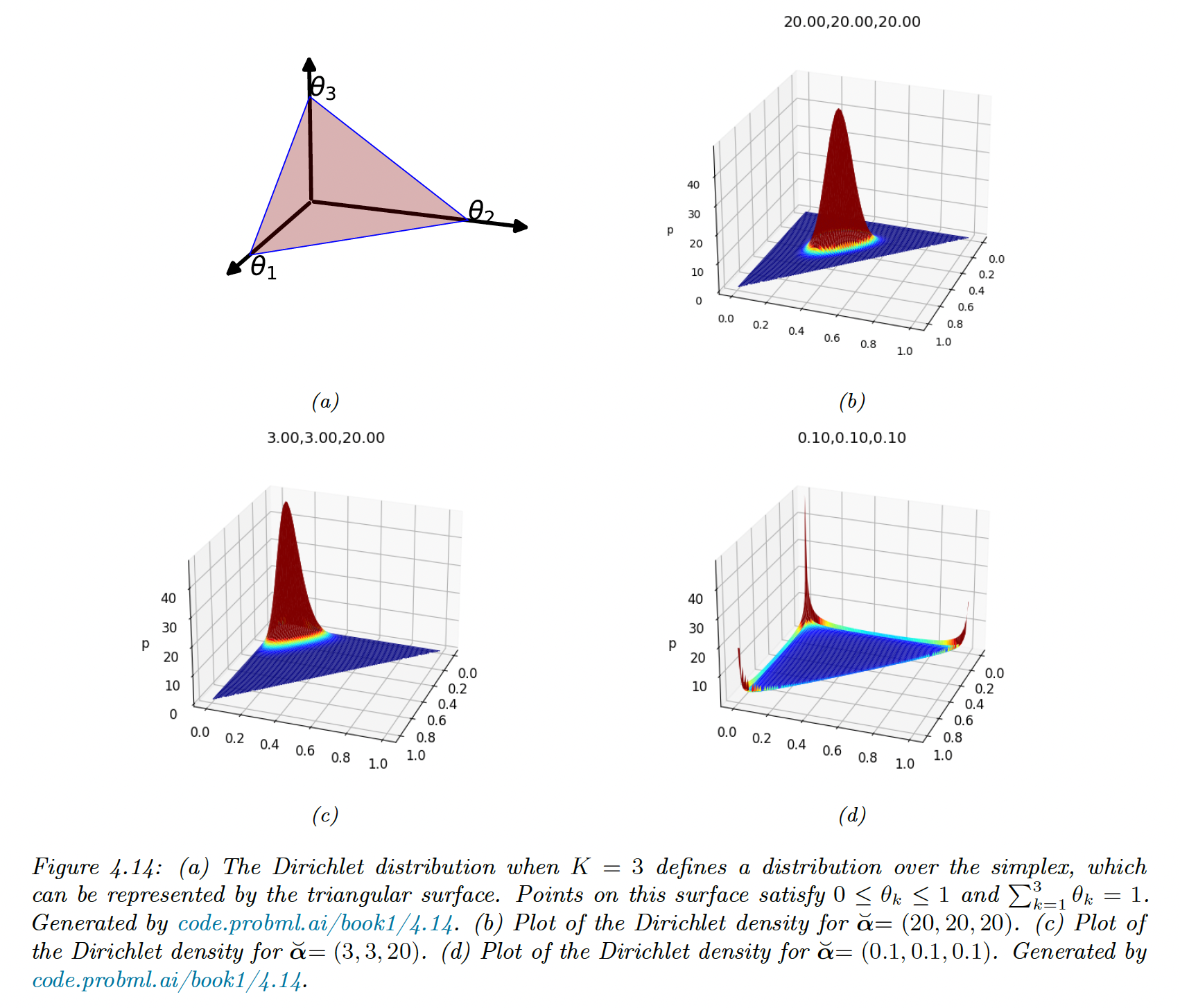
4.6.3.3 Posterior
The posterior is:
The posterior mean is:
The posterior mode (which corresponds to the MAP) is:
If , corresponding to a uniform prior, the MAP becomes the MLE:
4.6.3.4 Posterior predictive
The posterior predictive distribution is given by:
For a batch of data to predict (instead of a single point), it becomes
Where the denominator and the numerator are marginal likelihoods on the training and training + future test data.
4.6.3.5 Marginal likelihood
The marginal likelihood of the Dirichlet-categorical are given by:
4.6.4 Gaussian-Gaussian model
We derive the posterior for the parameters for a Gaussian distribution, assuming that the variance is known for simplicity.
4.6.4.1 Univariate case
We can show that the conjugate prior is also Gaussian. We then apply the Bayes rule for Gaussian, with the observed precision and the prior precision . The posterior is:
The posterior mean is a convex combination of the empirical mean and the prior mean.
To gain more intuition, after seeing point, our posterior mean is:
The second equation is the prior mean adjusted towards the data y.
The third equation is the data adjusted towards the prior mean, called a shrinkage estimate.
For a Gaussian estimate the posterior mean and posterior mode are the same, thus we can use the above equations to perform MAP estimation.
If we set an uninformative prior and approximate the observed variance by
then the posterior variance of our mean estimate is:
We see that uncertainty in reduces at the rate .
Because 95% of the Gaussian distribution is contained within 2 standard deviations of the mean, the 95% credible interval for is:
4.6.4.2 Multivariate case
For -dimensional data, the likelihood has the form:
Thus we replace the set of observations with their mean and scale down the covariance.
We obtain the same expression for the posterior of the mean than in the univariate case.
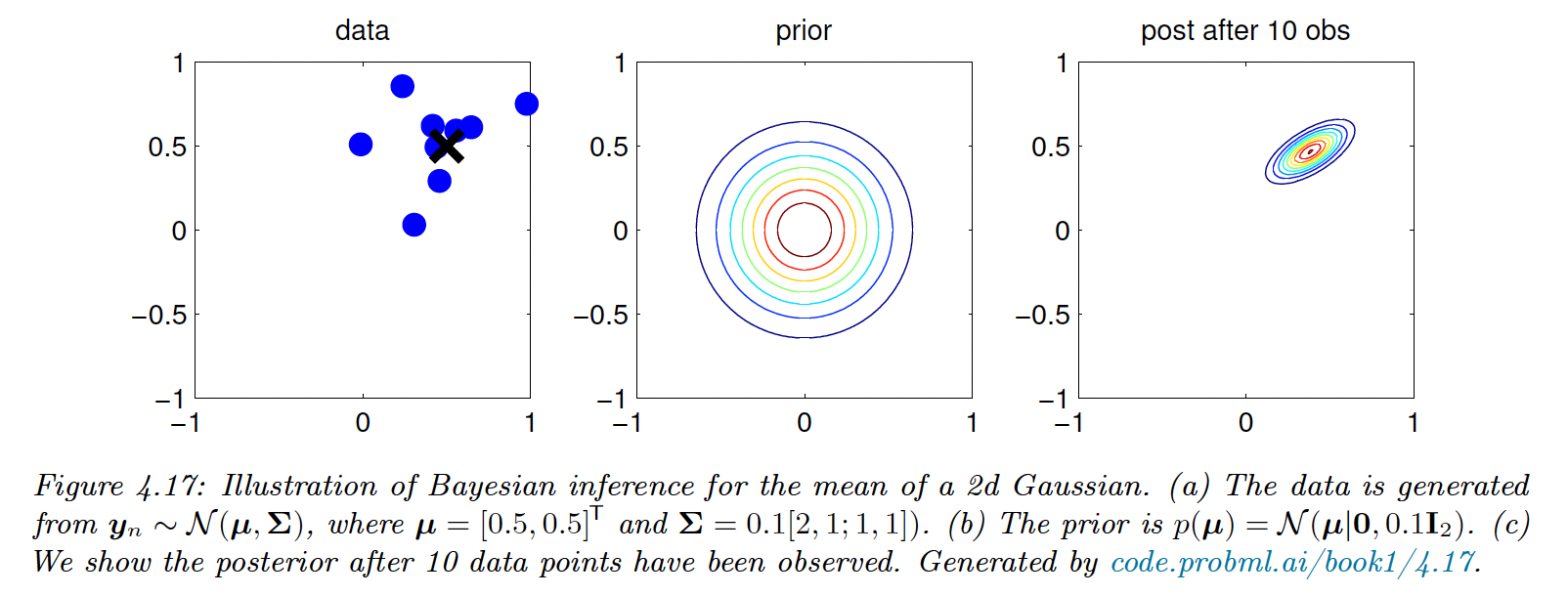
4.6.5 Beyond conjugate priors
For most models, there is no prior in the exponential family that conjugates to the likelihood. We briefly discuss various other kinds of prior.
4.6.5.1 Non informative prior
When we have little to no domain specific knowledge, we prefer “let the data speak for itself” (we get closer to the frequentist statistics).
We can for example use a flat prior , which can be viewed as an infinitely wide Gaussian.
4.6.5.2 Hierarchical prior
The parameters of the prior are called hyper-parameters . If there are unknown, we can put a prior on them: this defines a hierarchical Bayesian model.
If we set a non informative prior on , the joint distribution has the form:
We aim at learning by treating the parameters as data points. This is useful when we want to estimate multiple related parameters from different subpopulations.
4.6.5.3 Empirical prior
The joint distribution of the hierarchical prior can be challenging to compute.
Instead, we make a point wise estimation of the hyper-parameters by maximizing the marginal likelihood:
We then compute the conditional posterior in the usual way.
This violates the principle that the prior should be chosen independently of the data, but we can view it as a computationally cheap approximation of the hierarchical prior.
The more integral one performs, the “more Bayesian” one becomes:

Note that ML-II is less likely to overfit than ML since there are often fewer hyper-parameters than parameters .
4.6.6 Credible intervals
The posterior distribution is hard to represent in high dimension. We can summarize it via a point estimate (posterior mean or mode) and compute the associated credible interval (which is different from the frequentist confidence interval).
The Credible Interval for is:
If the posterior has a known functional form, we can compute its inverse cdf to find the interval: and .
In general, finding the inverse cdf is hard, so instead we rank samples from the posterior distribution and select our target percentiles.
Sometimes, points that are outside the interval have higher density probability than inner points.
We use the highest posterior density (HPD) to counter this, by finding the threshold :
and then defines the HPD as:
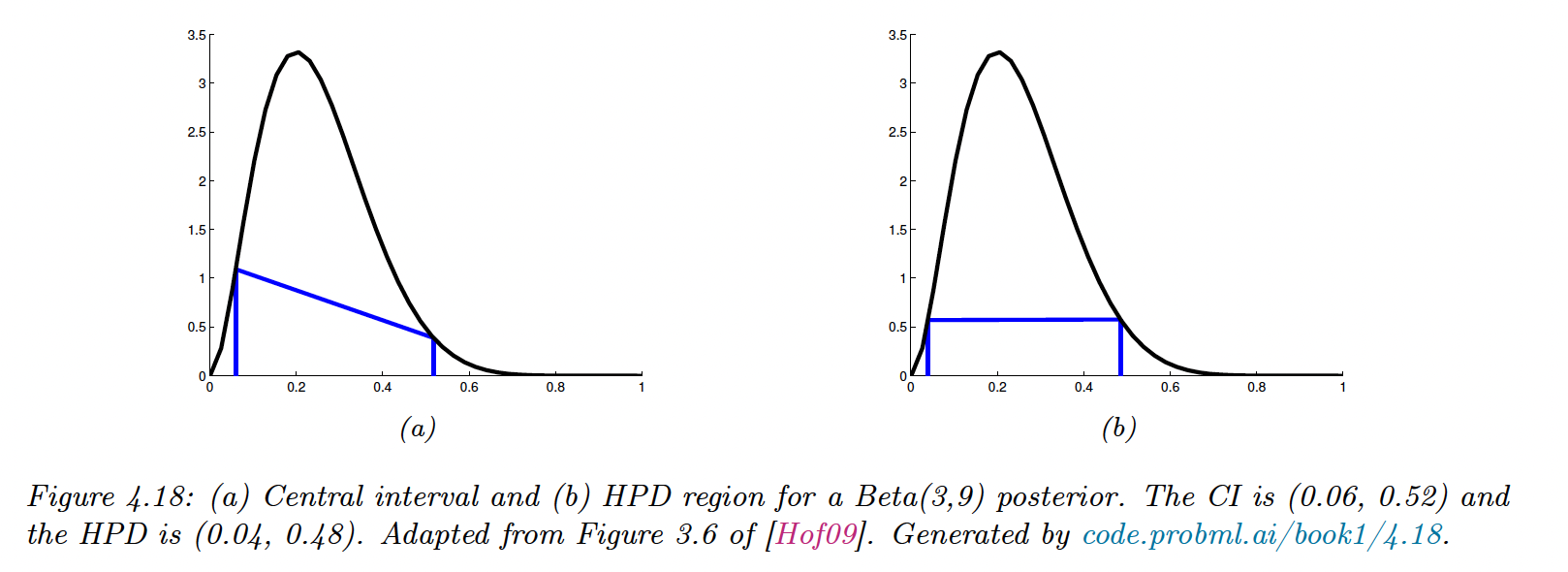
4.6.7 Bayesian machine learning
So far, we have focused on unconditional models of the form .
In supervised machine learning, we focus on conditional models of the form .
Our posterior becomes where . This approach is called Bayesian machine learning.
4.6.7.1 Plugin approximation
Once we have computed the posterior over the , we can compute the posterior predictive distribution over given :
Computing this integral is often intractable. Instead, we approximate that there is a single best model , such as the MLE.
Using the plugin approximation, the predictive distribution is now:
This is the standard machine learning approach of fitting a model then making prediction.
However, as this approximation can overfit, we average over a few plausible parameters values (instead of the fully Bayesian approach above). Here are 2 examples:
4.6.7.2 Example: scalar input, binary output
To perform binary classification, we can use a logistic regression of the form:
In other words:
We find the MLE for this 1d logistic regression and use the plugin approximation to get the posterior predictive
The decision boundary is defined as:
We capture the uncertainty by approximating the posterior .
Given this, we can approximate the mean and the 95% credible interval of the posterior predictive distribution using a Monte Carlo approximation:
where is a posterior sample.
We can also compute a distribution over the decision boundary:
where
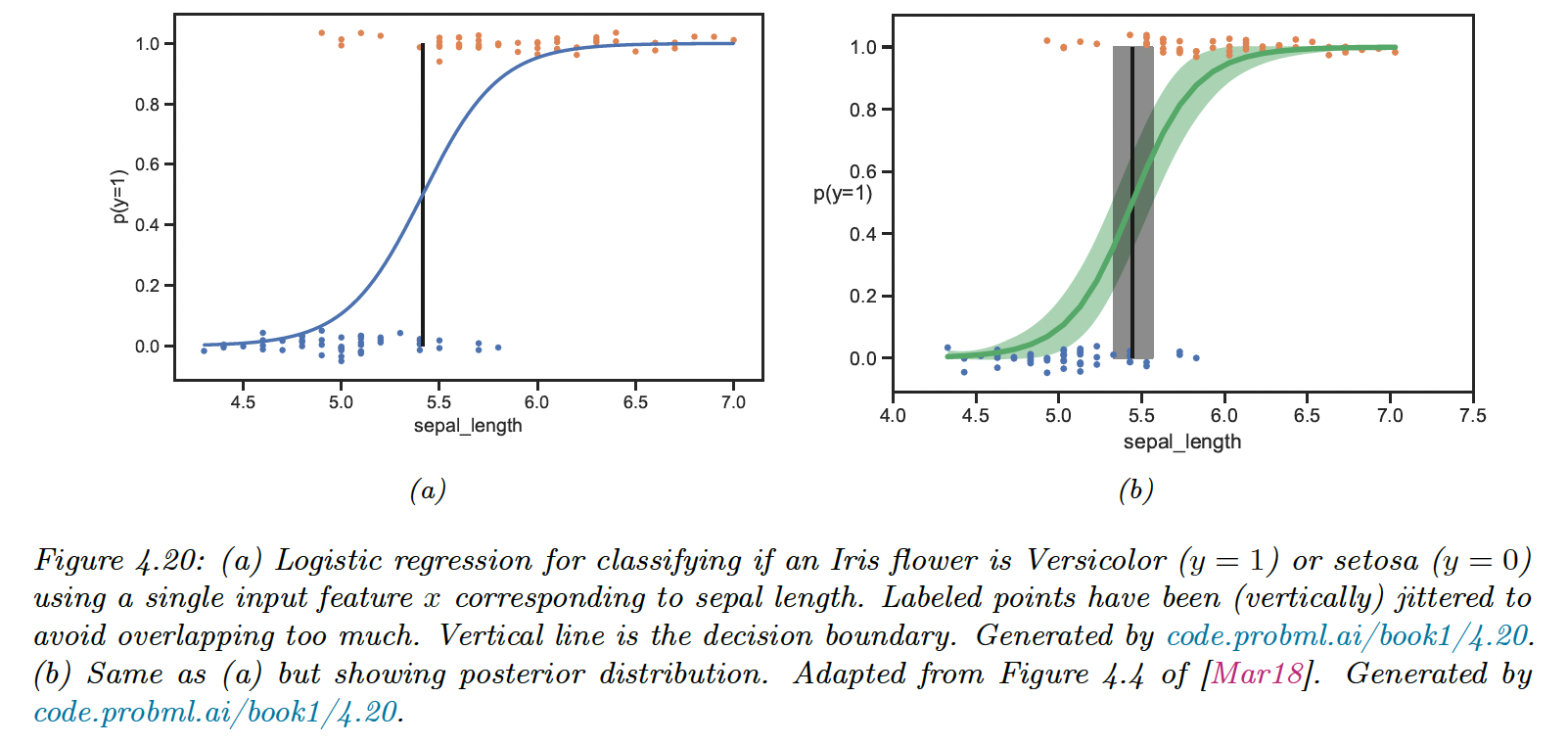
4.6.7.3 Exemple: binary input, scalar output
We now predict the delivery time for a package from company A () or company B
().
Our model is:
The parameters are so we can fit this model using MLE.
However, the issue with the plug-in approximation is that in the case of one single point of observation, we don’t capture uncertainty, our MLE for standard deviations are .
Instead, the Bayesian approach using the Bayes rule for Gaussian allows to compute the posterior variance and the credible interval.
4.6.8 Computational issues
Usually, performing the Bayesian update is intractable except for simple cases like conjugate models or latent variables with few possible values.
We perform approximate posterior inference for a Beta-Bernoulli model:
with consisting in 10 heads and 1 tails, with a uniform prior.
4.6.8.1 Grid approximation
The simplest approach is to partition in a finite set and approximate the posterior by brute-force enumeration:
This captures the skewness of our posterior, but the number of grid points scales exponentially in high dimension.
4.6.8.2 Quadratic (Laplace) approximation
We approximate the posterior using a multivariate Gaussian as follow:
where is the normalization constant and is called an energy function.
Performing a Taylor series around the mode (i.e. the lowest energy state), we get:
where is the gradient at the mode and the Hessian. Since is the mode, the gradient is zero.
Hence:
The last line follows from the normalization constant of the MVN.
This is easy to apply, since after computing the MAP estimate, we just need to compute the Hessian at the mode (in high dimensional space, we use a diagonal approximation).
However we see that the Laplace approximation fits poorly, because the posterior is skewed whereas Gaussian is symmetric.
Additionally, the parameter of interest lies in the constraint interval whereas the Gaussian assumes an unconstrained space . This can be solved later by a change of variable .
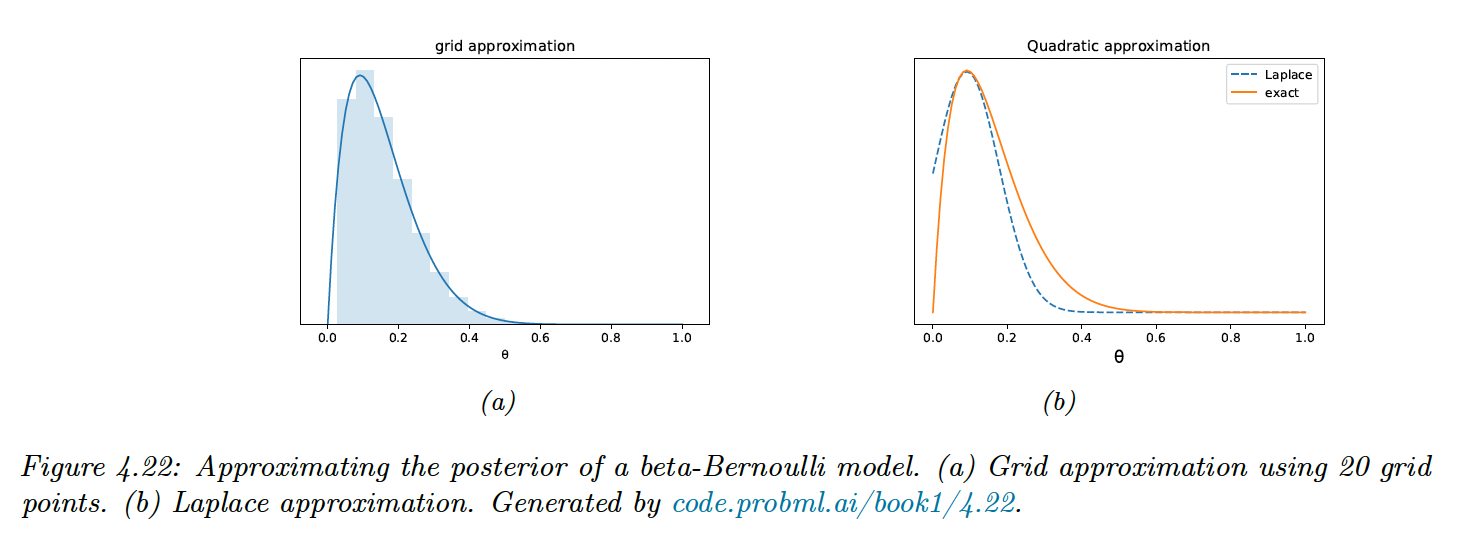
4.6.8.3 Variational inference (VI)
VI is another optimization base posterior approximation. It aims at minimizing some discrepancy between our posterior distribution and a distribution from some tractable family (like MVN):
If is the KL divergence, we can derivate the evidence lower bound (ELBO) of the marginal likelihood. Maximizing the ELBO improves the posterior approximation.
4.6.8.4 Markov Chain Monte Carlo (MCMC)
Although VI is fast, it can give a biased approximation since it is restricted to a specific function form .
Monte Carlo is a more flexible, non-parametric approach:
The key issue is to create posterior samples without having to evaluate the normalization constant
MCMC —and Hamiltonian Monte Carlo (HMC)— speeds up this method by augmenting this algorithm with gradient based information derived from .