7.4 Eigenvalue decomposition (EVD)
7.4.1 Basics
For a square matrix , is an eigenvalue of if:
with eigenvector.
Intuitively, multiplying by results in a vector in the same direction that , scaled by
Since is also an eigenvector of , we consider eigenvectors to be normalized with length 1.
The equation above gives us:
Therefore, this has a non-zero solution iff has a non-empty nullspace, which is only the case if this matrix is singular:
Properties:
- The rank of is equal to its number of non-zero eigenvalues
- If is non-singular, is an eigenvalue of with corresponding eigenvectors:
- The eigenvalues of a triangular matrix are just its diagonal entries.
7.4.2 Diagonalization
We can write all eigenvectors equations simultaneously:
with and
If the eigenvectors are linearly independent, then is invertible and:
A matrix that can be written in this form is called diagonalizable.
7.4.3 Eigenvalues of symmetric matrices
When is real and symmetric, it can be shown that its eigenvalues are real and its eigenvectors are orthonormal:
So in matrix notation: , hence is an orthogonal matrix.
We can represent as:
Thus multiplying by any symmetrical matrix can be viewed as multiplying by a rotation matrix , a scaling matrix and inverse rotation with .
Since , is easily invertible:
7.4.4 Geometry of quadratic forms
is positive definite iff :
is called a quadratic form.
In 2d, we have:

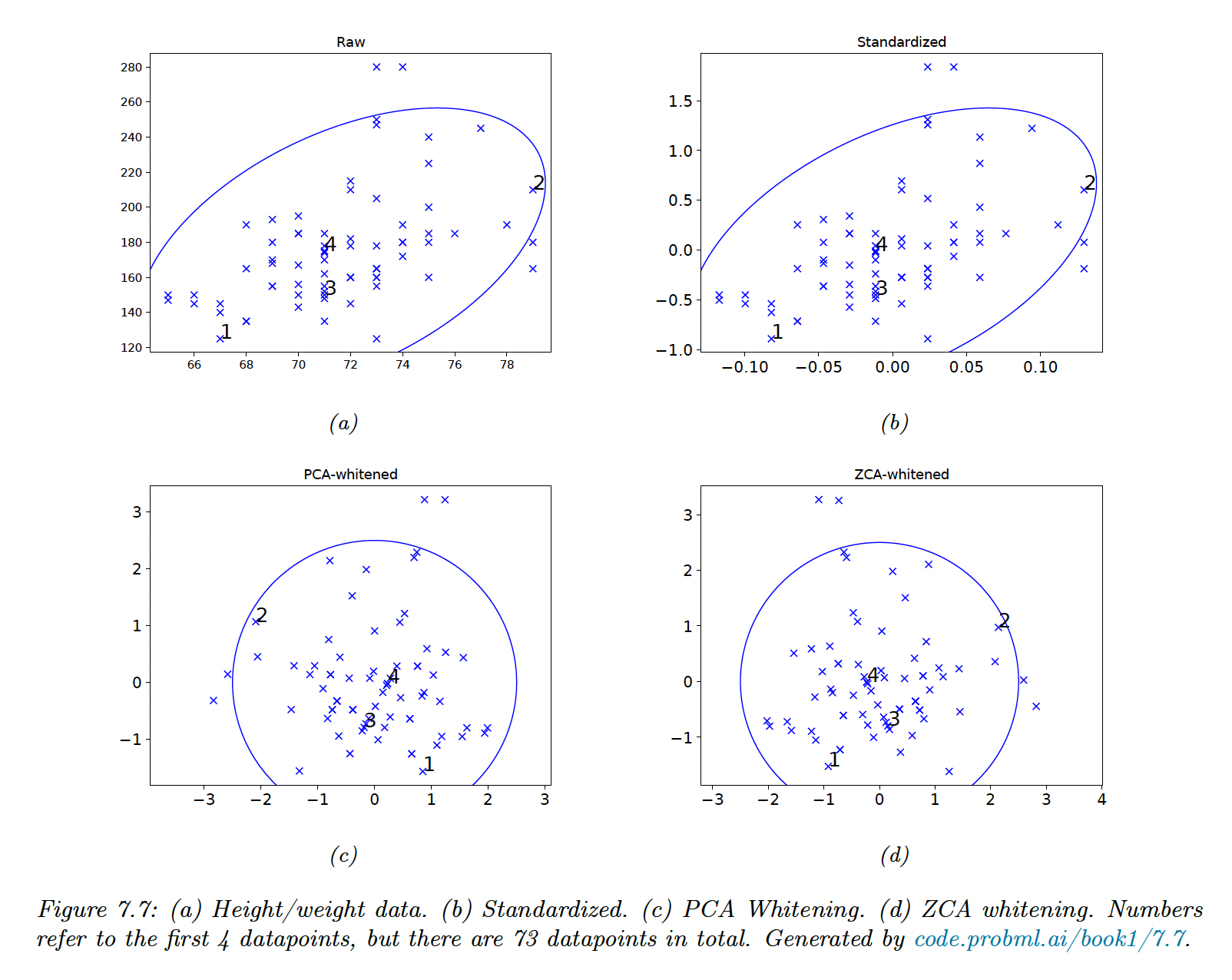
7.4.5 Standardizing and whitening data
We can standardize so that each column has a mean of 0 and a variance of 1. To remove the correlations between the columns, we need to whiten the data.
Let be the empirical covariance matrix and its diagonalization.
We can define the PCA whitening matrix as:
Let , we can check that:
The whitening matrix is not unique, since any rotation will maintain the whitening property .
For example, with
with, the SVD decomposition of .
This is called the Mahalanobis whitening or ZCA (zero-phase component analysis). The advantage of ZCA over PCA is that the resulting matrix is closer to the original matrix —in the least square sense.
When applied to images, the ZCA vectors still look like images.
7.4.6 Power method
This method is useful to compute the distribution of massive transition matrices (like Google PageRank).
Let be a matrix with orthonormal eigenvectors and eigenvalues
Let be an arbitrary vector in the range of , such that .
We have:
So by multiplying with and renormalizing at each iteration:
So:
To compute , we define the Reyleight coefficient:
Therefore in our case:
7.4.7 Deflation
Suppose we have computed using the power method, we now compute the subsequent .
We project out the components from :
This is called matrix deflation. We can now run the power method on to find , the largest eigenvalue on the subspace orthogonal to .
Deflation can be used to implement PCA, by computing the first eigenvectors of a covariance matrix.
7.4.8 Eigenvectors optimize quadratic forms
Consider the following constrained optimization problem:
for a symmetric matrix .
A standard way to solve a constrained optimization problem is by forming the Lagrangian:
Therefore:
So the problem is reduced to , and the only solutions to maximize given are the eigenvectors of .