20.5 Word embeddings
Words are categorical random variable, so their one-hot representation is sparse.
The issue with this representation is that semantically similar words can have very different vector representation. “man” and “woman” will have the same Hamming distance of 1 than “man” and “banana”.
The standard way to solve this is to use word embeddings. Instead of using sparse vectors , we can use a denser low dimensional representation , for the th word in the th document. This can significantly help with sparsity.
We define semantic similarity by saying that similar words occur in similar contexts. This is known as the distributional hypothesis, summarized by “a word is characterized by the company it keeps”.
20.5.1 Latent semantic analysis / indexing
We discuss a simply way to learn word embeddings based on a SVD of a term-frequency count-matrix.
20.5.1.1 Latent semantic indexing (LSI)
Let be the frequency of “term” occurs in “context” .
The definition of “term” is application specific, often considered to be the words by simplicity. We may remove infrequent or very frequent words during preprocessing.
The definition of “context“ is also application specific. We often consider a set of document or corpus. is then called the term-document frequency matrix.
Sometimes we apply TF-IDF transformation to the count, as discussed in section 1.5.4.2.
Let be the count matrix and the rank approximation the minimizes the following loss:
One can show that the minimizer of this loss is given by the rank truncated SVD approximation .
This means we can represent each as a bilinear product:
We define to be the embedding for word , and the embedding for context .
We can use these embeddings for document retrieval. The idea is to compute embeddings for the query words, and compare this to the document embeddings . This is known as latent semantic embedding (LSI).
More precisely, suppose the query is a bag of words , represented by the vector:
Then, we rank document by the cosine similarity between the query vector and the document:
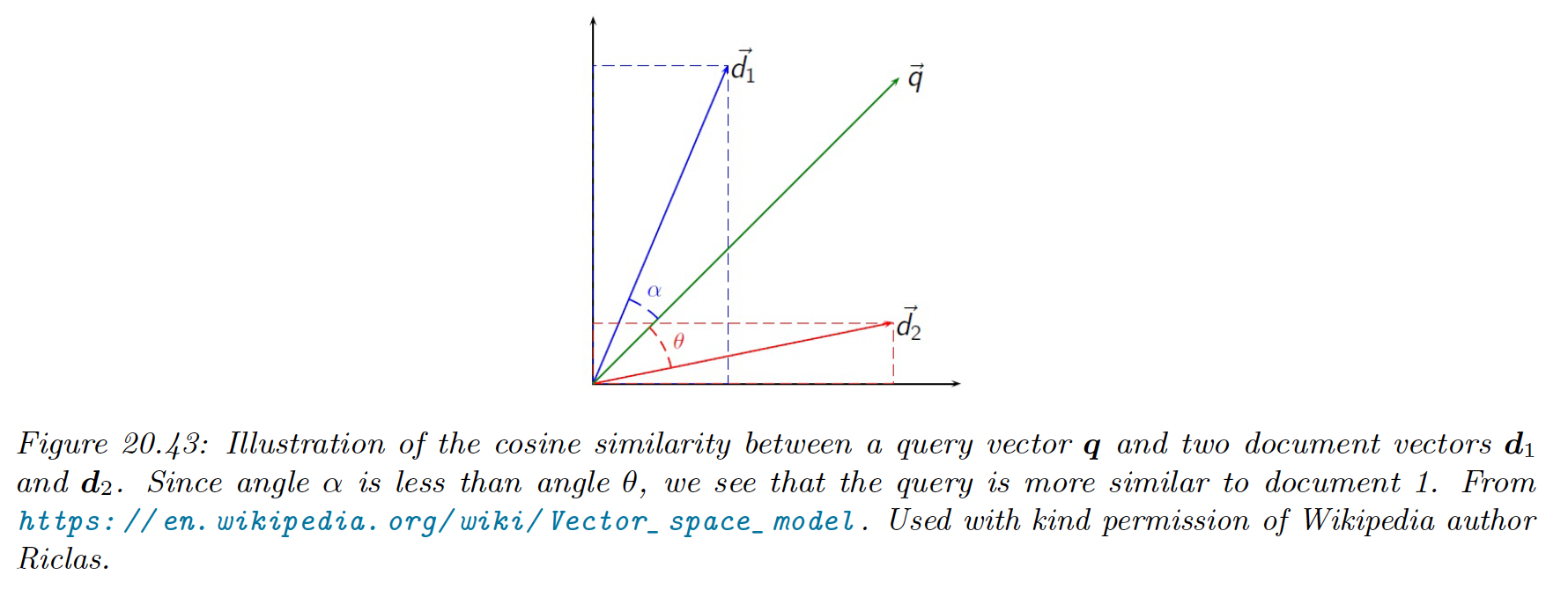
Note that if the vectors are unit norm, cosine similarity is the same as inner product. It is also equal to squared euclidean distance, up to a change of sign and an additive constant.
20.5.1.2 Latent semantic analysis (LSA)
Now suppose we define context more generally to be some local neighborhood of words where is the window size.
Thus is how many times the word occurs in a neighborhood of type . We have the same formula as previously, and this is known as latent semantic analysis (LSA).
For example, we compute on the British National Corpus, and retrieve the nearest neighbors ranked by cosine similarity. If the query word is “dog”, and we use or , the nearest neighbors are:

The 2-word context window is more sensitive to syntax, while the 30-word window is more sensitive to semantics. The “optimal” value of depends on the application
20.5.1.3 Pointwise mutual information (PMI)
In practice, LSA (and similar methods) give better results if we replace the raw counts by the pointwise mutual information (PMI).
If word is strongly associated to document , we have .
If the PMI is negative it means that and co-occurs less that if they were independent. However, such negative correlation can be unreliable, so it is common to use the positive PMI:
It has been showed that the SVD applied to the PPMI matrix result in word embeddings that perform well on various tasks related to word meaning.
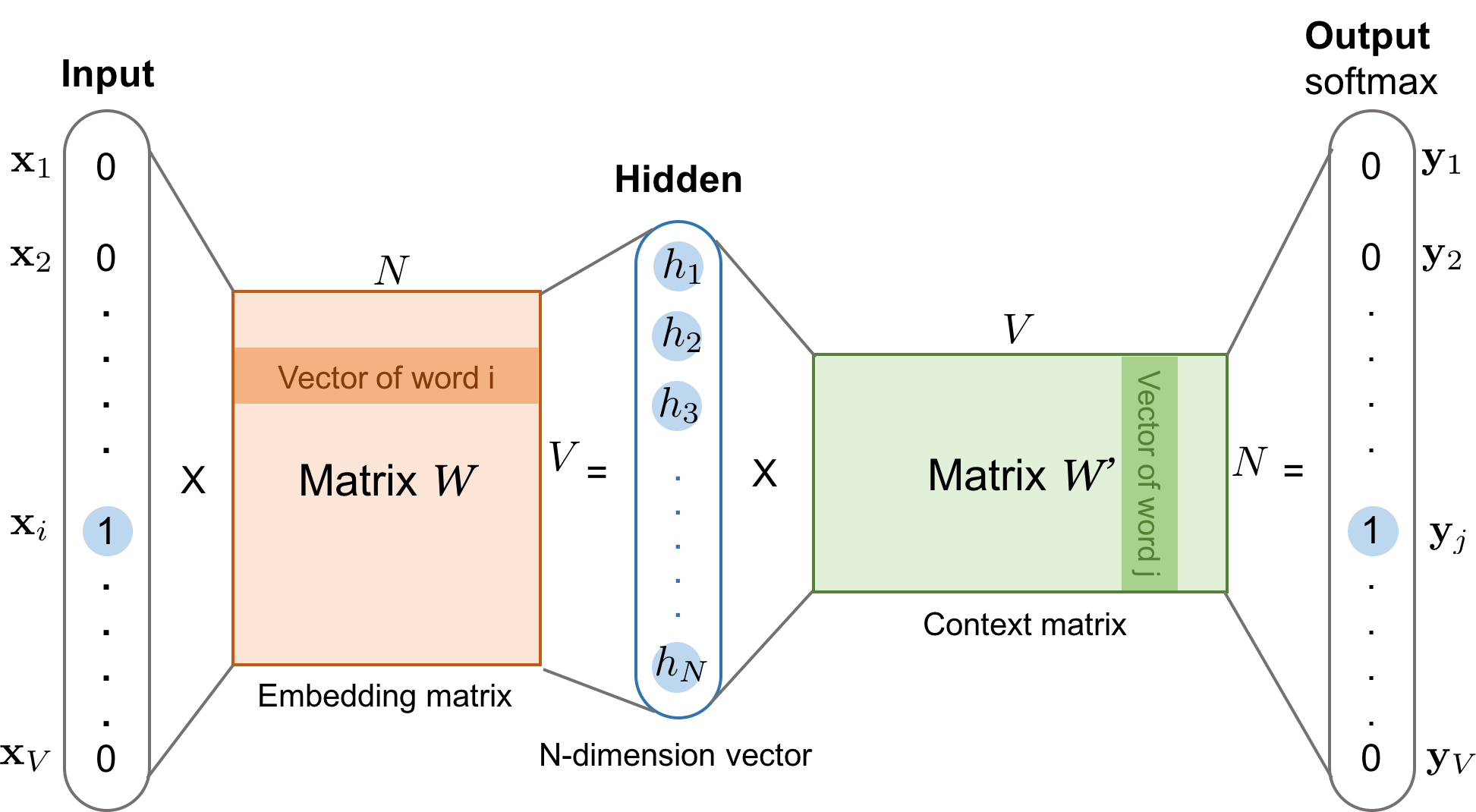
20.5.2 Word2vec
The popular word2vec model is a shallow neural net for predicting a word given its context. In section 20.5.5 we will discuss it connection with the SVD of the PMI matrix.
There are two versions of word2vec: continuous bag of words (CBOW) and skipgram.
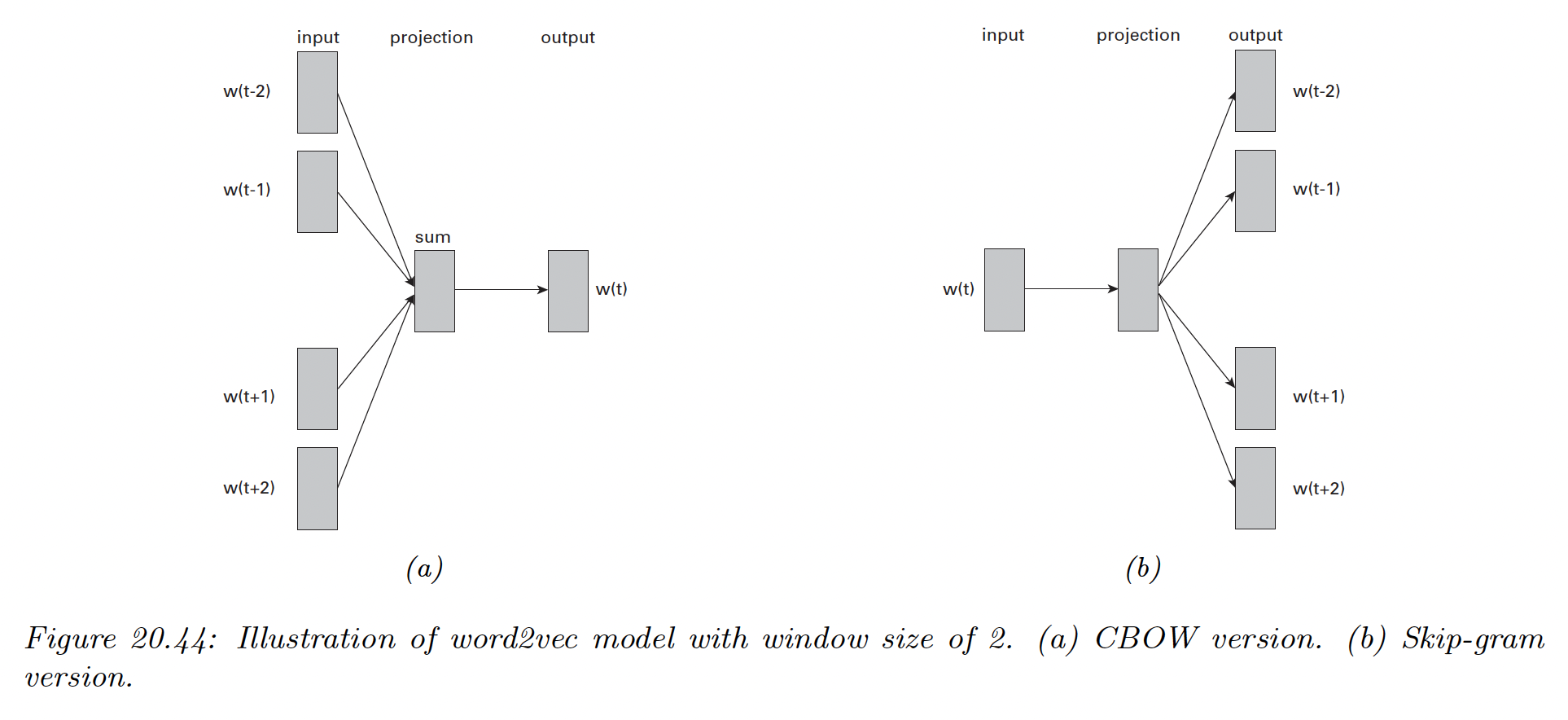
20.5.2.1 Word2vec CBOW model
In the CBOW model, the log likelihood of a sequence is:
where is the vector for word at location , is the context size, the vocabulary and
is the average of word vectors in the window around word .
Thus, we will try to predict each word given its context. The model is called CBOW because it uses a bag of words assumption for the context, and represent each word by its embedding.
20.5.2.2 Word2vec Skip-gram model
A variant of CBOW is to predict the context (surrounding words) given a word:
We define the log probability of some other context word given the central word :
See the derivation of the loss to obtain the gradient (opens in a new tab).
20.5.2.3 Negative sampling
Computing the conditional probability of each word in the previous equation is expensive, because it needs to normalize over all possible words in . This makes computing the gradient slow for the CBOW and skip-gram models.
A fast approximation has been proposed, called skip-gram with negative sampling (SGNS).
The basic idea is to create a set of context words for each central word and label the one that actually occurs as positive and the rest as negative.
The negative words are called noise words and can be sampled from a reweighted unigram distribution , which has the effect of redistributing probability mass from common to rare words.
The conditional probability is now approximated by:
where are noise words, and is the event that the word pair actually occurs in the data.
The binary probabilities are given by:
To train the model, we can then compute the log probability of the data and optimize the embedding vectors and for each word using SGD.
See this implementation (opens in a new tab).
20.5.3 GloVE
A popular alternative to Skipgram is GloVe (global vectors for word representation). This methods use a simpler objective, faster to optimize.
Recall that in the skipgram model, the predicted conditional probability of word occuring in the context window of central word is:
Let the number of time the word occurs in any context of the word (note that this is symmetric, ).
Then we can rewrite the loss as:
If we define to be the empirical probability of word occuring in the context window of central word , we can rewrite the skipgram loss as a cross entropy loss:
The issue with this objective is that computing is expensive due to the normalization term over all words.
In GloVe, we work with unnormalized probabilities:
where are bias term to capture marginal probabilities.
In addition, we minimize the square loss, , which is more robust to errors in estimating small probabilities than log loss.
Finally, we down-weight rare words, which carry noise, by:
with .
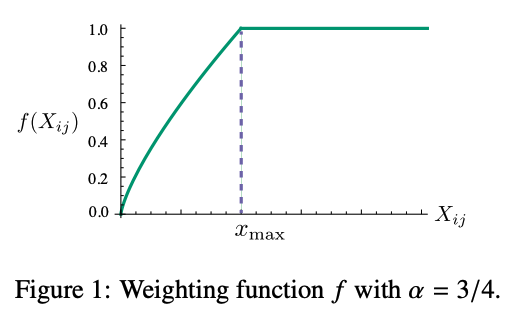
This gives the final GloVe objective:
We can precompute offline, and then optimize the above objective using SGD.
After training, we define the embedding of word to be the average of and
Empirically, GloVe gives similar results to skipgram, but is faster to train.
20.5.4 Word analogies
One of the remarkable properties of word embeddings produced by word2vec or GloVe is that the learned vector space capture relational semantics in terms of vector addition.
Suppose we take the words . How do we find ?
Let be the vector representing the concept of “converting the gender from male to female”. Intuitively, we can find the word by computing , and then finding the closest word in the vocabulary to .
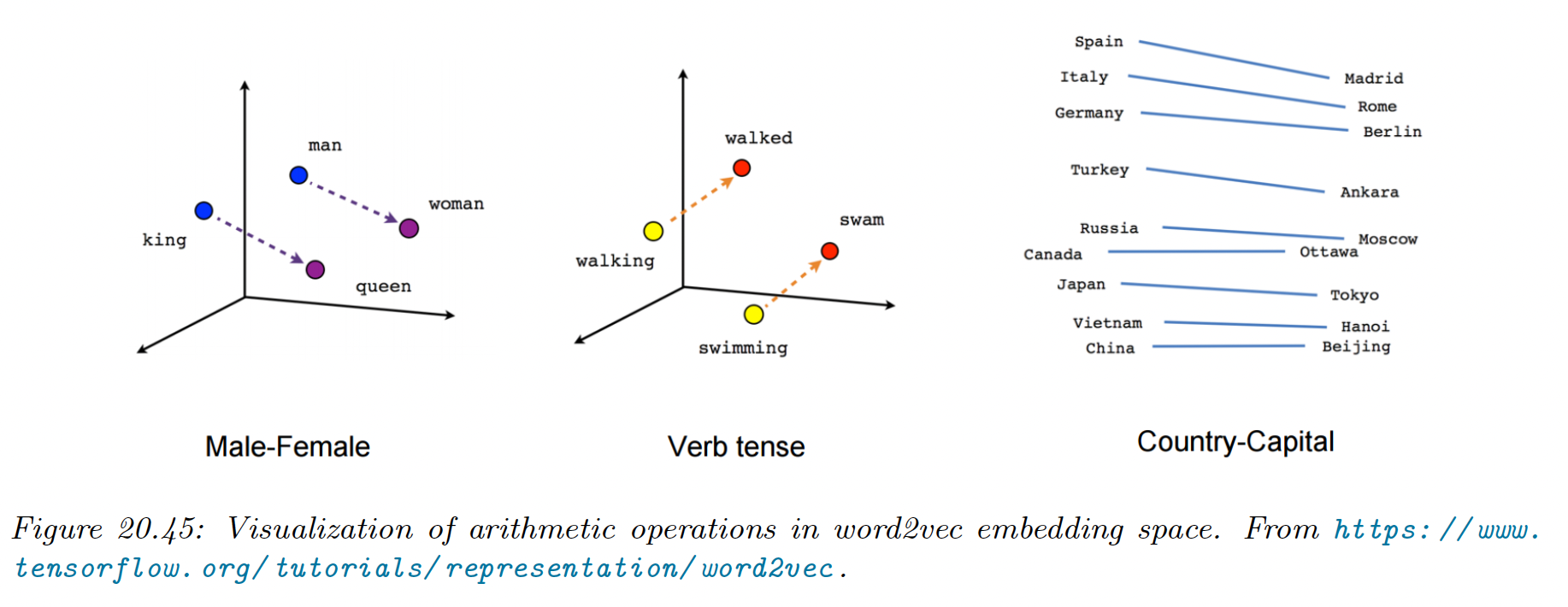
It has been conjectured that holds iff for every word in the vocabulary, we have:
This follows the Rand-Walk modeling assumption.
20.5.5 Rand-Walk model of word embeddings
Word embeddings significantly improve the performance of various kinds of NLP models compared to using one-hot encodings. We explain why in this section.
Consider a sequence of words , we assume each word is generated by a latent context using the following bilinear language model:
where is the mebedding for word , and is the partition function.
Let us further assume the prior for the word embedding is an isotropic Gaussian, and that the latent topic undergoes a slow Gaussian random walk.
Under this model, one can show that is approximately equal to a fixed constant, , independent of the context. This is known as the self-normalizing property of log-linear model.
Furthermore, one can show that the pointwise mutual information of predictions from the model is given by:
We can therefore fit the Rand-Walk model by matching the model’s predicted values for PMI with the empirical values, i.e. we minimize:
where is the number of times and occur next to each other.
This objective can be seen as frequency-weighted version of the SVD loss in LSI (section 2.5.1.1 above).
Some additional approximations can be used to show that the NLL for the Rand-Walk model is equivalent to the CBOW and SGNS word2vec objectives. We can also derive the objective for GloVe from this approach.
20.5.6 Contextual word embeddings
In the sentences “I ate an apple” and “I bought a new phone from Apple”, the meaning of the word “apple” is different in both cases, but a fixed word embedding, of the type we saw in this section, wouldn’t be able to capture this.
In section 15.7 we discuss contextual word embeddings, where the embedding of a word is a function of all the words in its context (usually a sentence). This can give much improved results, and is currently the standard approach to representing natural language data, as a pre-processing step before doing transfer learning.