4.5 Regularization
The main issue with MLE and ERM is that they pick parameters by minimizing the loss on the training set, which can result in overfitting.
With enough parameters, a model can match any empirical distribution. However, in most cases the empirical distribution is not the same as the true distribution. Regularization add a penalty term to the NLL.
by taking the log loss and the log prior for penalty term.
This is equivalent to minimizing the MAP:
4.5.1 MAP for Bernoulli distribution
If we observe just one head, . We add a penalty to to discourage extreme values.
With , and , we encourage values of near to the mean
With the same method as the MLE, we find:
By setting , we resolve the zero-count problem.
Regularization combines empirical data and prior knowledge.
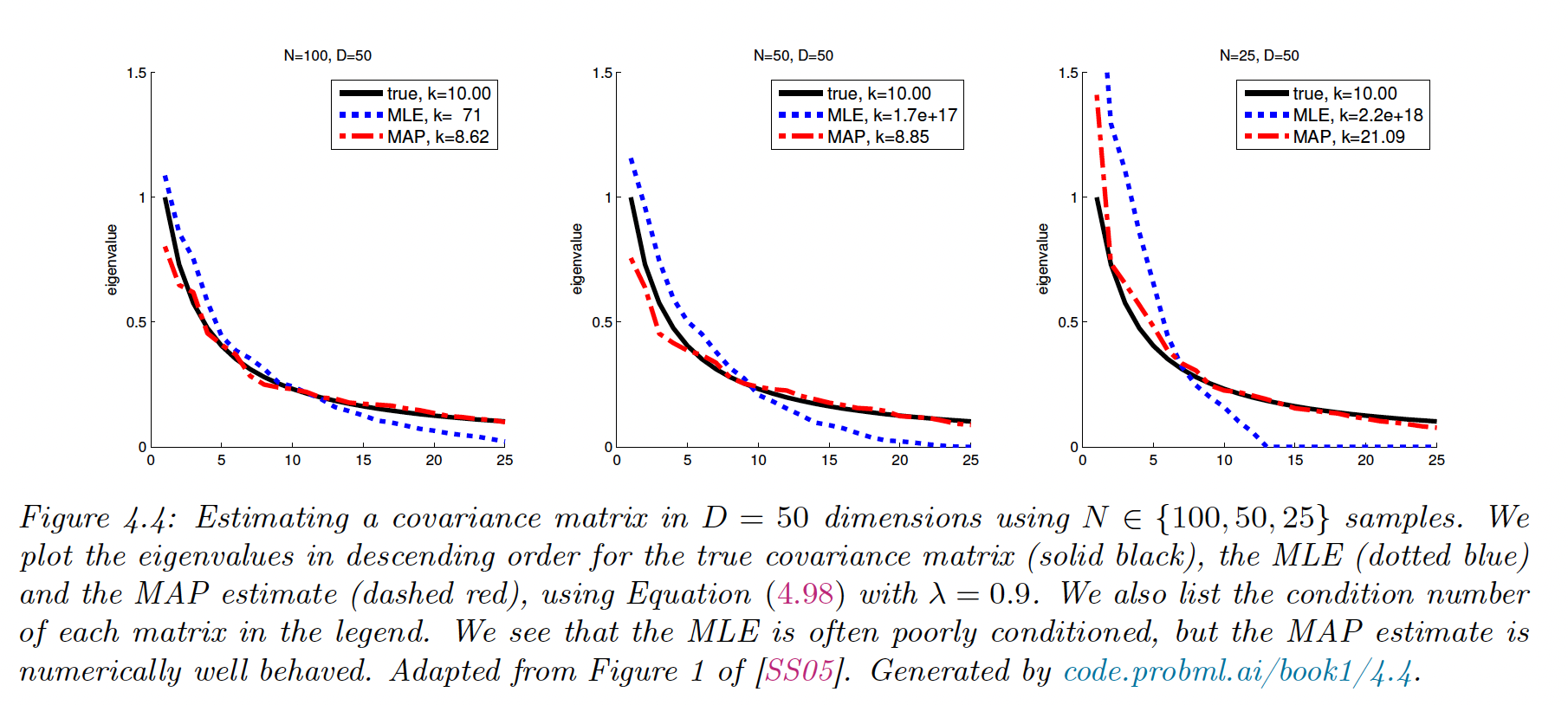
4.5.2 MAP for MVN
We showed that the MLE for covariance of a MVN is . In high dimensions, the scatter matrix can easily become singular. One solution is to perform MAP estimation.
A convenient prior to use for is the Wishart distribution (generalization of the Gamma distribution). The resulting MAP is:
where controls the amount of regularization.
If we set :
Off-diagonal elements are shrunk toward 0. can be chosen via cross-validation of via close form (implemented in scikit-learn LedoitWolf (opens in a new tab)).
The benefits of the MAP is to better behaved than MLE, with eigenvalues of the estimate closer to that of the true covariance matrix (the eigenvectors however are unaffected).
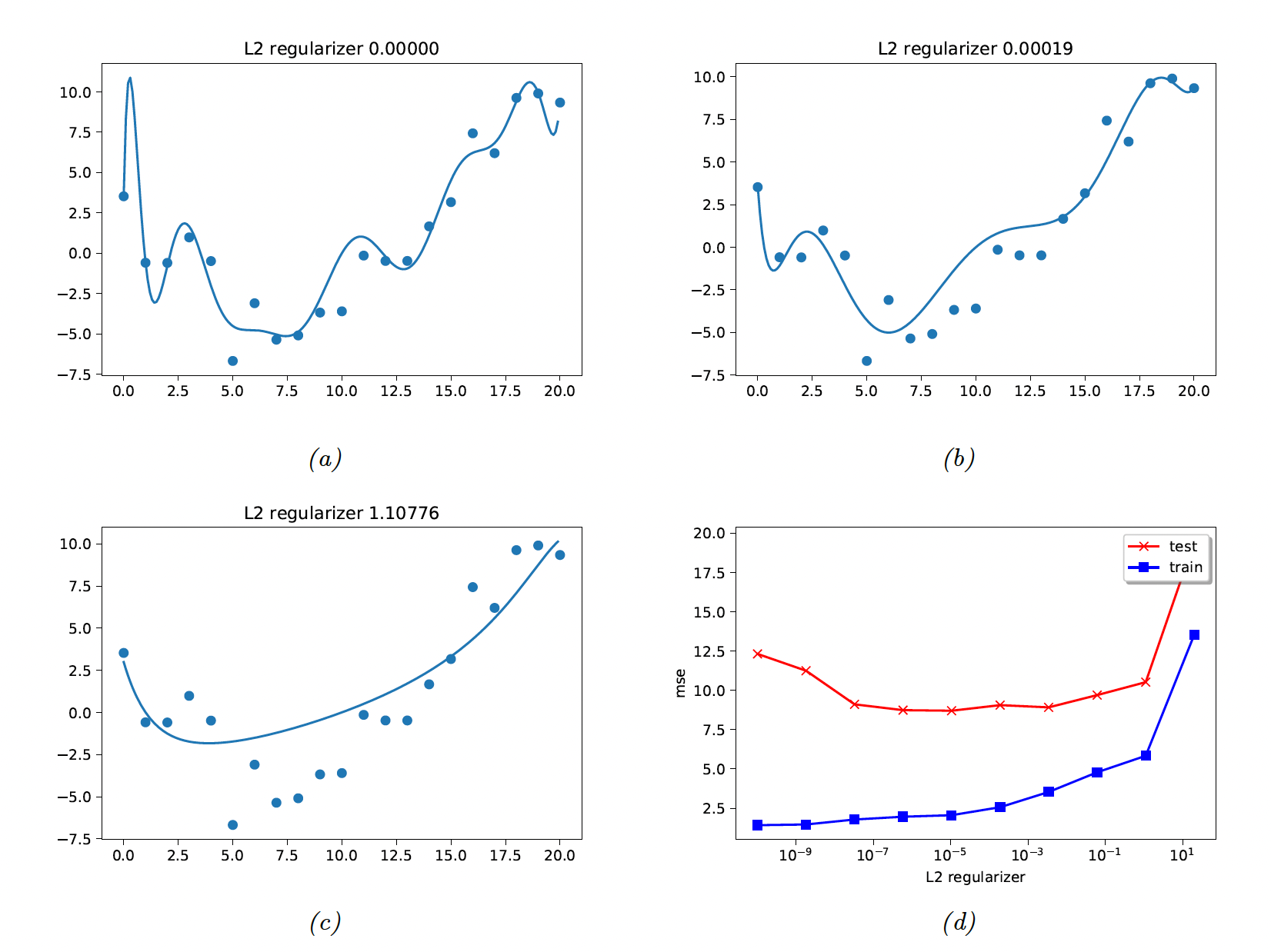
4.5.3 Weight decay
We saw that reducing the degree of the polynomial help the regression task. A more general solution is to add regularization to the regression coefficients.
where a higher means more pressure toward low coefficients and thus less flexibility for the model. This is ridge regression.
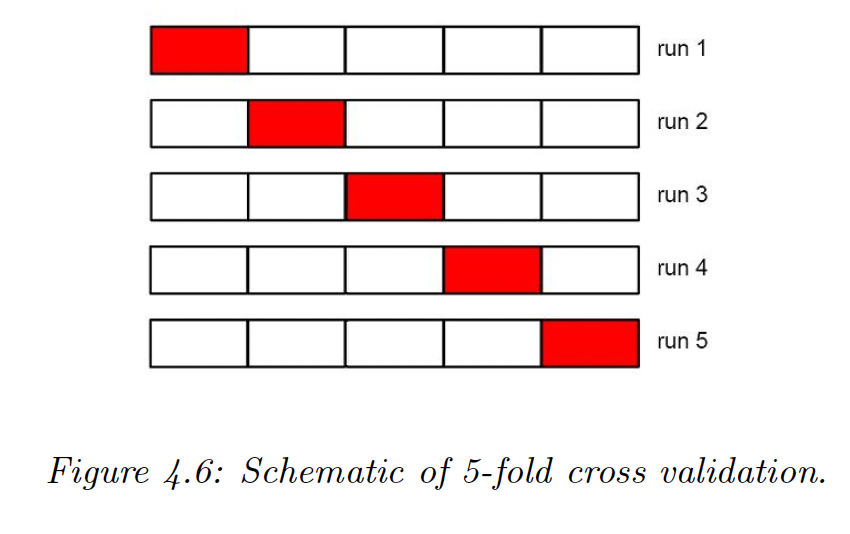
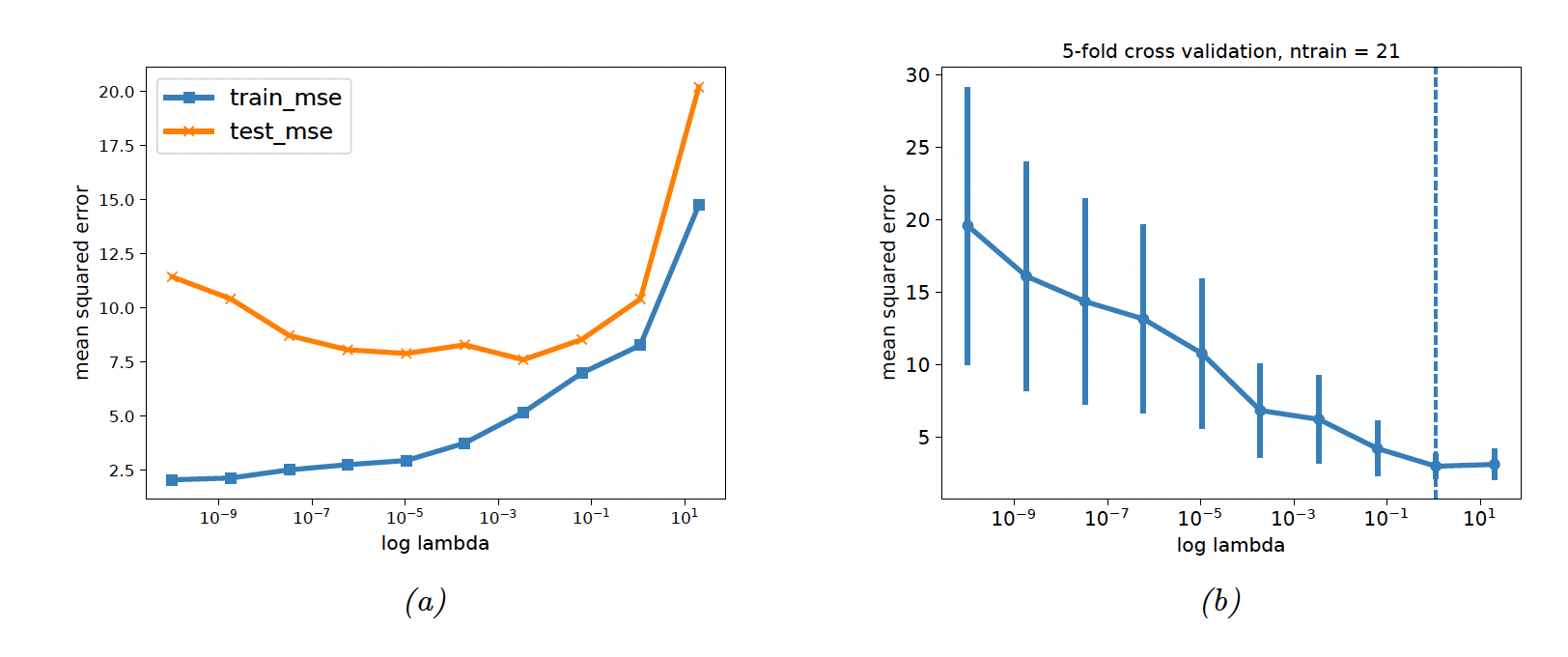
4.5.4 Picking 𝝺 by cross validation
We split the training data into folds and iteratively fit on all fold except one, used for validation.
We have
So
Finally
The standard error of our estimate is:
where
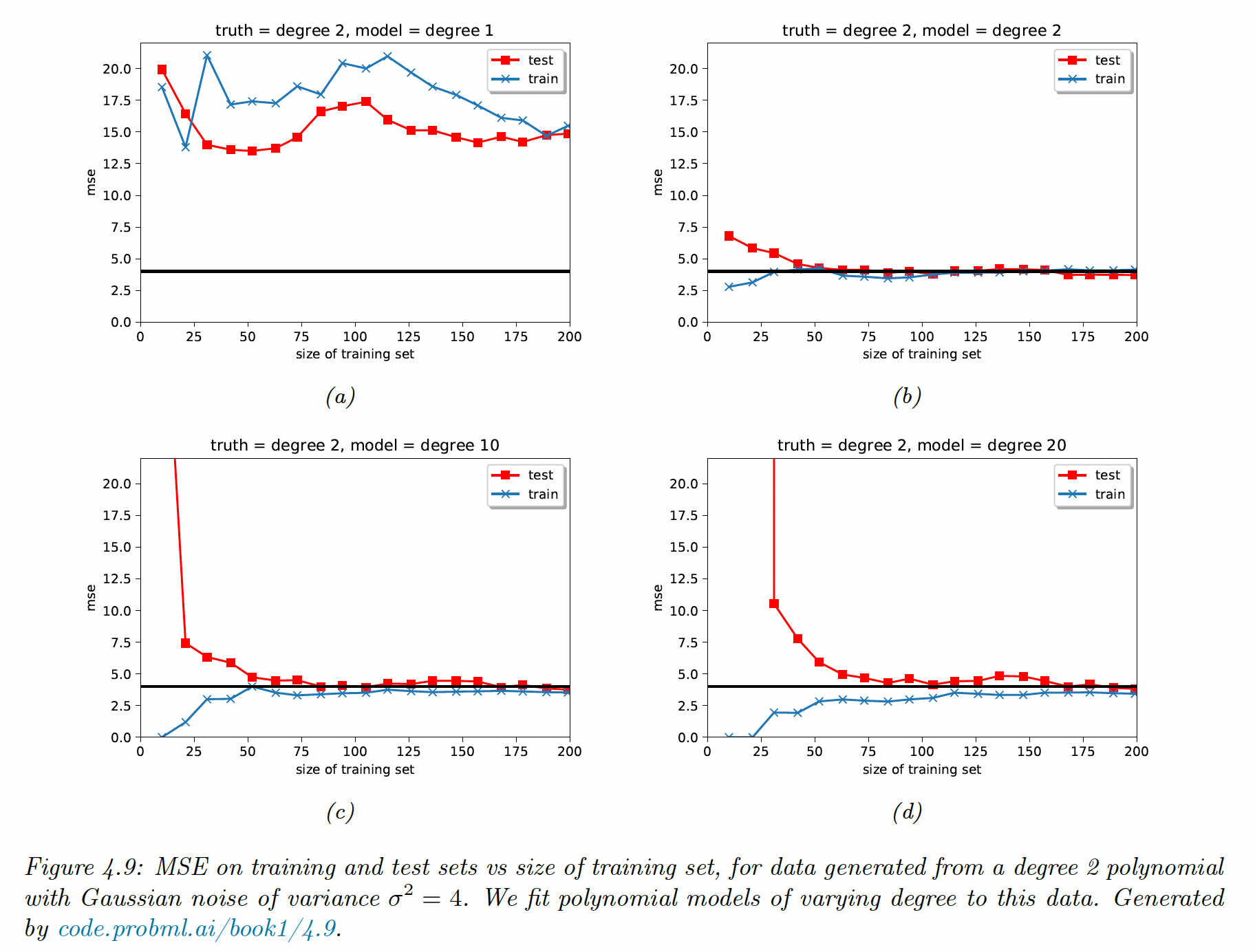
4.5.7 Using more data
When a model is too simplistic, it fails to improve as the data grow. A overly complex model will end up converging toward the right solution if enough data is provided.