19.3 Semi-supervised learning
Large labeled dataset for supervised learning is often expensive. In automatic speech recognition, modern datasets contain thousand of hours of recording, and annotating the words spoken is slower than realtime.
To make matters worst, in some applications, data must be labeled by an expert (such as in medical applications) which can further increase cost.
Semi-supervised learning can alleviate the need of labeled data by leveraging unlabeled data. Its general goal is to learn the high level structure of the unlabeled data distribution, and only rely on labeled data to learn the fine-grained details of a given task.
In addition to samples from the joint distribution of data , semi-supervised learning also assumes to have access to the marginal distribution of , namely .

Further, we also assume to have many more unlabeled data than labeled data, since, in the example of ASR, recording people talking is cheap.
Semi supervised learning is therefore a good fit in the scenario where a large amount of unlabeled data has been collected and we prefer to avoid labeling all of it.
19.3.1 Self-training and pseudo-labeling
The basic idea of self-training is to infer predictions on unlabeled data, and then use these predictions as labels for subsequent training.
Self-training has endured as an approach to semi-supervised learning because of its simplicity and general applicability, and it has recently been called pseudo-labeling, by opposition to the ground truth labels used in supervised learning.
Algorithmically, self-training follows of the following two procedures.
In the first offline approach:
- Pseudo labels are predicted for the entire unlabeled dataset
- The model is retrained (possibly from scratch) on the combination of the labeled and pseudo-labeled datasets.
- Repeat to 1.
In the second online approach:
- Pseudo labels are continuously predicted on randomly chosen batches of the unlabeled data
- The model is immediately retrained on this batch of pseudo labels
- Repeat to 1.
Both approaches are popular in practice; the offline one has been shown to be particularly successful when leveraging giant collections of unlabeled data, whereas the online is often used as a step of more complex semi-supervised learning methods.
The offline approach can result in training models on stale pseudo-labels since they are only updated each time the model converged, but the online approach can be more computationally expensive since it involves constantly “relabeling” unlabeled data.
However, self-training can suffer from confirmation bias: if the model generates incorrect predictions for the unlabeled data and then is re-trained on them, it can become progressively worse at the intended classification task.
We can mitigate confirmation bias by using a “selection metric” to only retain correct pseudo-labels. For example, assuming that model outputs probability for each class, we can retain pseudo-labels whose largest class probability is above some threshold.
If the model’s class probability estimate are well calibrated, then this selection metric rule will only retain labels are highly likely to be correct.
19.3.2 Entropy minimization
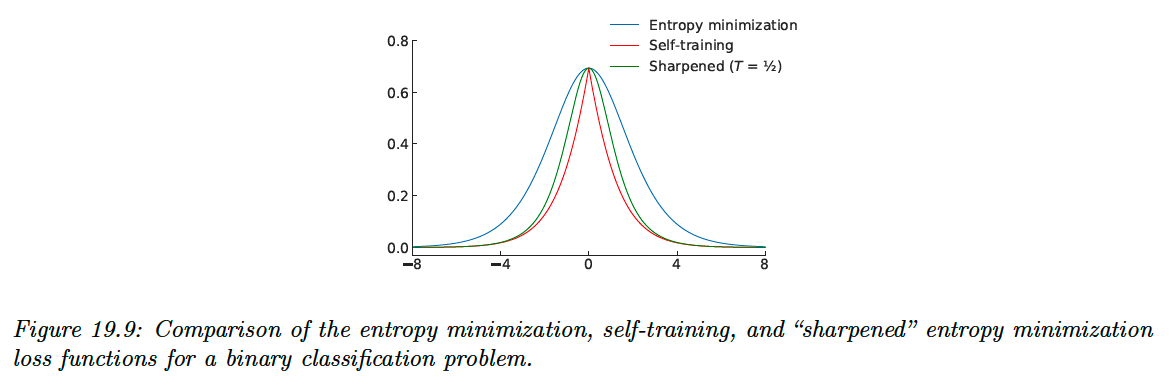
Self-training has the implicit effect of encouraging the model to output low-entropy (i.e. high confidence) predictions. This effect is most apparent in the online setting with a cross-entropy loss, where the model minimizes the following loss function on the unlabeled data:
This function is minimized when the model assigns all its probability to a single class , i.e. and .
A closely-related semi-supervised learning method is entropy minimization, which minimizes the loss:
Note that this function is also minimized when the model assigns all of its class probability to a single class.
We can make the entropy-minimization loss equivalent to the online self-training loss by replacing the first term with a “one-hot” vector that assign a probability of 1 for the class with the highest probability.
In other words, online self-training minimizes the cross-entropy loss between the model’s output and the “hard” target , whereas entropy minimization uses the “soft” target .
One way to trade-off between these two extremes is to adjust the “temperature” of the target distribution by raising each probability to and renormalizing. This is the basis of the mixmatch method.
At , this is equivalent to entropy minimization, as , it becomes hard online self-training.
19.3.2.1 The cluster assumption
Why is entropy minimization a good idea? A basic assumption of many semi-supervised learning method is that the decision boundary between class should fall in a low-density region of the data manifold.
This assumes that the data corresponding to different classes are clustered together. A good decision boundary, therefore, should not pass through clusters, it should separate them.
Semi-supervised learning method that make the “cluster assumption” can be thought of using unlabeled data to estimate the shape of the data manifold and moving the decision boundary away from it.
Entropy minimization is one such method, since for smooth decision boundaries, entropy will be minimized when the decision boundary is place in low-density regions of the input space.

19.3.2.2 Input-output mutual information
An alternative justification for the entropy minimization objective was proposed by Bridle, Heading and MacKay, where they shown that it naturally arises from maximizing the mutual information between the data and the label:
Note that the first integral is equivalent to taking an expectation over , and the second integral is equivalent to summing over all possible values of the class . We get:
Since we have initially sought to maximize the mutual information, we can convert it to a loss function to minimize by negating it:
The first term is exactly the entropy minimization objective in expectation.
The second term specifies that we should maximize the entropy of the average class prediction over our training set. This encourages the model to predict each possible class with equal probability, which is only appropriate when we don’t have imbalanced class.
19.3.3 Co-training
Co-training is also similar to self-training, but makes an additional assumption that there are two complementary views (i.e. independent sets of features) of the data.
After training two models separately on each view, unlabeled data is classified by each model to obtain candidate pseudo-labels. If a particular pseudo-label receives a low-entropy prediction (high confidence) from one model and high-entropy from the other, then that example is added to the training set for the high-entropy model.
Then, the process is repeated with the new, larger training datasets.
Retaining pseudo-labels when one of the models is confident ideally builds up the training sets with correctly-labeled data.
Co-training makes the strong assumption that there are two informative-but-independent views of the data, which may not be true for many problems.
The Tri-Training algorithm circumvents this issue by instead using three models that are first trained on independently-sampled (with replacement) subsets of the labeled data. Ideally, this leads to models that don’t always agree on their predictions.
Then, pseudo-labels are predicted by the three models. If two models agree on the pseudo-label of a given example, it is added to the training set for the third model.
This can be seen as a selection metric, because it only retains pseudo-labels where two (differently initialized) models agree on the correct label.
The models are the re-trained on the combination of the labeled data and the new pseudo-labels, and the whole process is repeated iteratively.
19.3.4 Label propagation on graphs
If two points are similar, we can expect them to share the same label. This is known as the manifold assumption.
Label propagation is a semi-supervised technique that leverages the manifold assumption to assign labels to unlabeled data.
It first constructs a graph where the examples are the nodes and the edges are the similarity between points. The node labels are known for labeled example but are unknown for unlabeled example.
Label propagation then propagates the known labels across edges of the graph in such a way that there is minimal disagreement in the labels of a given node’s neighbors.
This provides label guesses for the unlabeled data, which can then be used in the usual way for the supervised training of a model.
More specifically, the basic label propagation algorithm (opens in a new tab) proceed as follows.
Let denote a non-negative edge weight between and that provides a measure of similarity for the two (labeled or unlabeled) examples.
Assuming we have labeled and unlabeled examples, define the transaction matrix as having entries:
represent the probability of propagating a label from node to node .
Further, define the label matrix , where is the number of possible classes. The th row of represents the class probability distribution for example (the initialization of for unlabeled examples is not important).
Then, repeat until convergence of :
- Propagate:
- Row-normalize:
- Clamp the label data: replace the rows corresponding of labeled data by their one-hot representation.
The algorithm iteratively uses the similarity of datapoints to propagate labels onto the unlabeled data, in a weighted average way.
It can be shown this procedure converges to a single fixed point, whose computation cost mainly involve inverting the matrix of unlabeled-to-unlabeled transition probabilities.
The overall approach can be seen as a form of transductive learning since it is learning to predict the labels of a fixed unlabeled dataset, rather than learning a model that generalizes.
However, by training a model on the induced labeling, we can perform inductive learning in the usual way.
The success of label propagation depends heavily on the notion of similarity used to construct the weights between datapoints.
For simple data, measuring the Euclidean distance may be sufficient, but not for more complex and high dimensional data, where it could fail to capture the likelihood that two examples belong to the same class.
These weights can also be set arbitrarily according to problem-specific knowledge.
19.3.5 Consistency regularization
Consistency regularization leverages the idea that perturbing a given dataset (or the model itself) shouldn’t cause the model’s output to change dramatically.
Since measuring consistency this way only uses the model’s output, it is readily applicable to unlabeled data, and therefore can be used to create appropriate loss functions for semi-supervised learning. This idea was first proposed with the paper “learning with pseudo-ensembles”.
In its most general form, both the model and the transformations applied to the input can be stochastic. For example, in computer vision problems we may transform the input by using data augmentation like randomly rotating or adding noise to the image, and the network may include stochastic components like dropout or weight noise.
A common and simple form of consistency regularization first samples , where is the distribution induced by the stochastic input transformations.
We minimize the combined loss function over of batch of labeled data and unlabeled data:
In practice, the first term of the regularizer is treated as fixed, i.e. gradients are not propagated through it.
Many design choices impact the success of this semi-supervised learning approach.
i) First, if the parameter is too large, then the model way not give enough weight to learning the supervised task and will instead start to reinforce its own bad predictions (as with confirmation bias in self-training).
Since the model is often poor at the start of training, it is common practice to initialize to zero and increase its value over the course of training.
ii) A second important consideration is the choice of the random transformations . These transformations should be designed so that they don’t change the label of , and are domain specific.
The use of data augmentation requires expert knowledge to determine what kinds of transformations are label preserving and appropriate for a given problem.
An alternative technique is virtual adversarial training (VAT), that transforms the input using analytically-found perturbation designed to maximally change the model’s output.
VAT computes:
The approximation is done by sampling from a multivariate Gaussian distribution, initializing and then setting:
where is a small constant.
VAT then sets:
Then proceed to consistency regularization, where is a scalar hyperparameter that sets the L2 norm of the perturbation applied to the input.
iii) Consistency regularization can also profoundly affect the geometry properties of the training objective, and the trajectory of the SGD.
For example, the Euclidean distances between weights at different training epochs are significantly larger for objectives that use consistency regularization.
It has been shown that a variance of stochastic weight averaging (SWA) can achieve state-of-the-art performance on semi-supervised learning tasks by exploiting the geometric properties of consistency regularization.
iv) Finally, we only have to consider the choice of the regularizer function measuring the difference between the network’s output with and without perturbation.
The loss above use the squared L2 distance (aka the Brier score), and it is also common to use the LK divergence, in analogy with the cross-entropy loss (i.e. KL divergence between the ground-truth label and prediction) used for labeled examples.
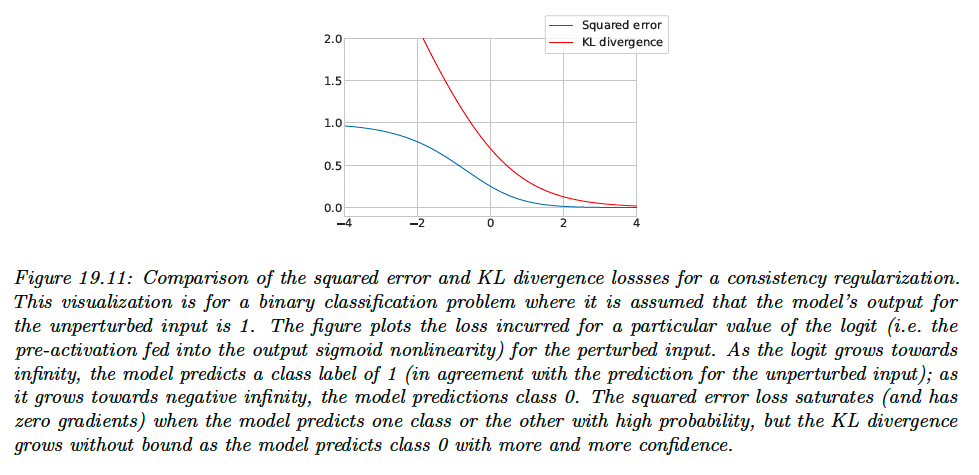
The gradient of the squared-error loss approaches zero as the model’s prediction with and without perturbation differ more and more, assuming the model uses a softmax nonlinearity on its logit output.
Using the squared-error loss therefore has a possible advantage that the model is not updated when its predictions are very unstable.
However, the KL divergence has the same scale as the cross-entropy loss used for labeled data, which makes for more intuitive tuning of .
19.3.6 Deep generative models
Generative models provide a natural way of making use of the unlabeled data through learning a model of the marginal distribution by minimizing:
Various approaches have leveraged generative models for semi-supervised by developing ways to use to help produce a better supervised model.
19.3.6.1 Variational autoencoders
VAE defines a probabilistic model of the joint distribution of data and latent variables . Data is assumed to be generated by first sampling and then sampling .
For learning, the VAE uses an encoder to approximate the posterior and decoder to approximate the likelihood. The encoder and decoder are typically neural nets, and their parameters can be jointly training by maximizing the evidence lower bound (ELBO) of data.
The marginal distribution of latent variables is often chosen to be a simple distribution like a diagonal-covariance Gaussian. is typically lower-dimensional than , constructed via nonlinear transformations and its dimensions are independent.
Therefore, the latent variables can provide a learned representation where data may be more easily separable.
In this paper (opens in a new tab), they call this approach M1 and show that the latent variables can be used to train stronger models when labels are scarce.
They also propose an alternative approach to leveraging VAEs called M2, which has the form:
where is a latent variable, is the latent prior (typically we fix and , the label prior, and is the likelihood, such as Gaussian, with parameters computed by , a neural net.
The main innovation of this approach is to assume that data is generated according to both a latent class variable as well as the continuous latent variable .
i) To compute the likelihood of the labeled data, , we need to marginalize over , by using an inference network of the form:
We then use the following variational lower bound:
As is standard for VAEs, the main difference being that we observe both and .
ii) To compute the likelihood of the unlabeled data, , we need to marginalize over and , with an inference network of the form:
Note that acts like a discriminative classifier, that imputes the missing labels. We then use the following variational lower bound:
Note that the discriminative classifier is only used to compute the log likelihood of the unlabeled data and is undesirable.
We get the overall objective function:
where controls the relative weight of generative and discriminative learning.
The probabilistic model used in M2 is just one of the many ways to decompose the dependencies between the observed data, the class labels and the continuous latent variables.
There also many other ways other than variational inference to perform approximate inference.
Overall the main advantage of the generative approach is that we can incorporate domain knowledge, e.g. the missing data mechanism, since the absence of a label may be informative about the underlying data.
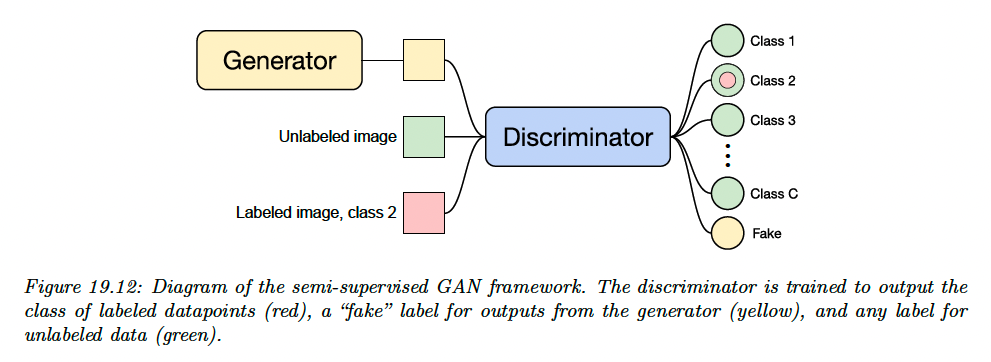
19.3.6.2 Generative adversarial networks (GANs)
GANs are a popular class of generative models that learn an implicit model of the data distribution.
They consist of:
- a generator network which maps samples from a latent distribution to the data space
- a critic network, which attempts to distinguish between the outputs of the generator and the samples from the true data distribution
The generator is trained to generate samples that the critic classifies as “real”.
Since GANs don’t produce a latent representation of a given example and don’t learn an explicit model of the data distribution, we can’t used the same approaches used for VAEs.
Instead, semi-supervised learning with GANs is typically done by modifying the critic so that it outputs either a class label or “fake”, instead of classifying “real” vs “fake”.
For labeled data, the critic is trained to output the appropriate class label, and for unlabeled real data, it is trained to raise the probability of any class labels.
Let denote the critic with outputs corresponding to classes plus a “fake” class, and let denote the generator which takes as input samples from the prior distribution .
We use a standard cross-entropy GAN loss as originally proposed in the GAN paper. The critic’s loss is:
This tries to maximize the probability of the correct class for the labeled examples, to minimize the probability of the fake class for the unlabeled examples and to maximize the probability of the fake class for generated examples.
The generator loss is:
19.3.6.3 Normalizing flows
Normalizing flows are a tractable way to define deep generative models. They define an invertible mapping , from the data space to the latent space.
The density in data space can be written starting from the density in the latent space using the change of variable formula:
We can extend this to semi-supervised learning. For class labels , we specify the latent distribution conditioned on a label as:
The marginal distribution of is then a Gaussian mixture.
The likelihood for labeled data is then:
And the likelihood for the unlabeled data is:
For semi-supervised learning we can then maximize the joint likelihood of the labeled and unlabeled data:
over the parameters of the bijective function , which learns a density model for a Bayes classifier.
Given a test point , the model predictive distribution is:
where we have assumed .
We can make predictions for a test point with the Bayes decision rule:
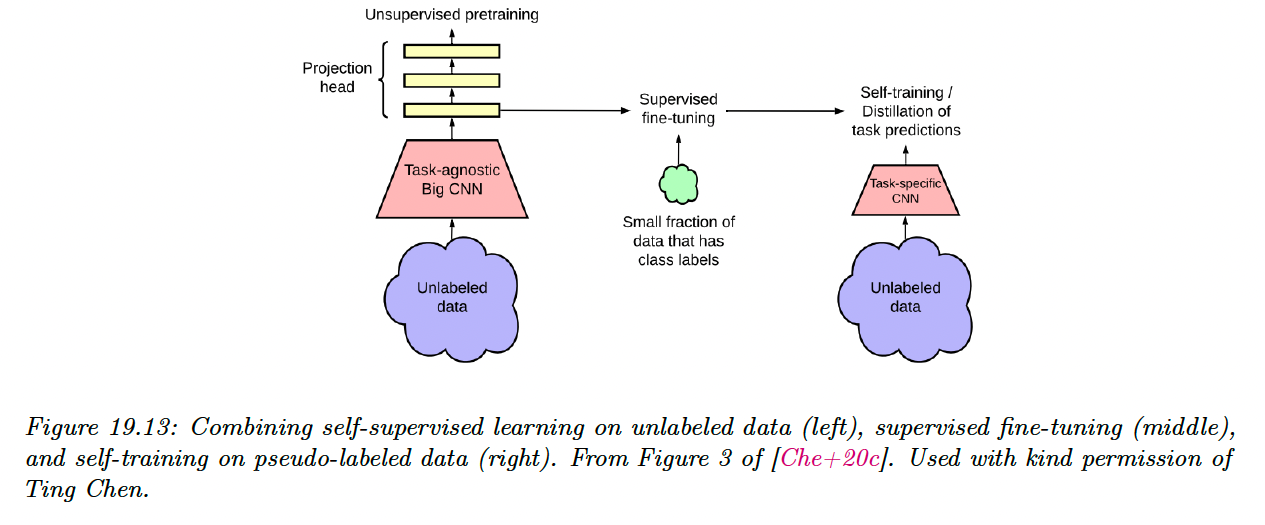
19.3.7 Combining self-supervised and semi-supervised learning
We can combine self-supervised and semi-supervised learning.
For example, we can:
- Use SimCLR to perform self-supervised representation learning on the unlabeled data
- Fine-tune this representation on a small labeled dataset (as in transfer learning)
- Apply the trained model back to the original unlabeled dataset, and distill the predictions from this teacher model into a student model .
This last approach is known as knowledge distillation, and consists in training one model on the predictions of another.
That is, after fine-tuning , we can train by minimizing:
where is a temperature parameter applied to the softmax output, which is used to perform label smoothing.
If has the same form as , this is known as self-training (as discussed section in 19.3.1).
However, the student is often a smaller than the teacher (for example, might be a high capacity model, and is a lightweight version that runs on a phone).