13.4 Training neural networks
We now discuss how to fit DNNs to data. The standard approach is to use MLE, by minimizing the NLL:
In principle, we can use the backprop algorithm and compute the gradient of this loss and pass it to an optimizer. Adam (section 8.4.6.3) is a popular choice, due to its ability to scale to large datasets (by virtue of being of SGD-type) and converges fairly quickly (by virtue of using diagonal preconditioning and momentum).
However, in practice, this may not work well. In addition to practical issues, there are theoretical limitations. In particular, the loss of DNNs is not convex, so we will generally not find the global optimum.
Nevertheless, SGD can often find surprisingly good solutions.
13.4.1 Tuning the learning rate
It is essential to tune the learning rate, to ensure convergence to a good solution (see section 8.4.3).
13.4.2 Vanishing and exploding gradient
When training very deep networks, the gradient tends to become very small (vanishing) or very large (exploding), because the signal is passed through a series of layers that either amplify it or diminish it.
Consider the gradient of layer :
If is constant across layers, the contribution of the gradient from the final layer, , to layer will be . Thus the behavior of the system depends on the eigenvectors of .
Although is a real-valued matrix, it is not symmetric, so its eigenvalues and eigenvectors can be complex-valued, with the imaginary components corresponding to oscillatory behavior.
Let be the spectral radius of (the largest absolute eigenvalues). If , the gradient can explode, if the gradient can vanish.
We can counter the exploding problem with gradient clipping, in which we cap the value of the magnitude of the gradient to if it becomes too large:
However, the vanishing problem is more difficult to solve. There are various solutions:
- Modify the activation functions (see next section)
- Modify the architecture so that the updates are additive rather than multiplicative (residual networks)
- Modify the architecture to standardize the activation at each layer, so that the distribution of activations over the dataset remains constant during training (batch norm).
- Carefully choose the initial values of the parameters
13.4.3 Non-saturating activation functions
As already mentioned in section 13.2.3, the sigmoid activation function and function saturates for small and large values of activations, vanishing gradient.
For the sigmoid of a linear layer, we have:
Hence, if the activation is close to 0 or 1, the gradient is close to 0.
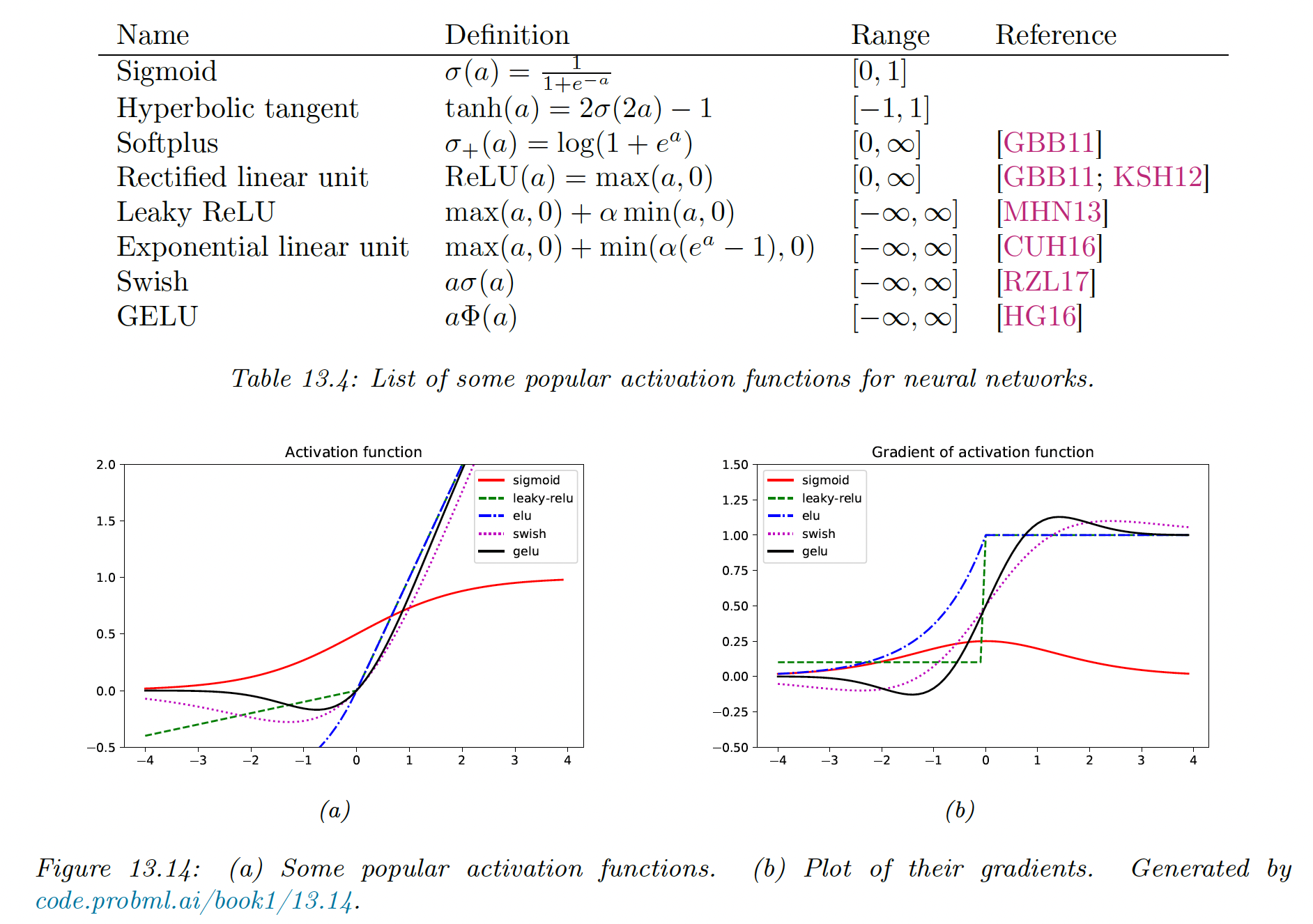
13.4.3.1 ReLU
The rectified linear unit is defined as:
Its gradient is:
Therefore, with a linear layer, we have:
Hence the gradient will not vanish, as long as is positive.
However, if some of the weights are initialized with large negative values, then some activations will go to zero and their gradient too. The algorithm will never be able to escape this situation, so some hidden units will stay permanently off. This is called the “dead-ReLU” problem.
13.4.3.2 Non-saturating ReLU
The leaky ReLU has been proposed to solve the dead-ReLU issue:
with , which allows some signal to be passed back to earlier layers, even when the input is negative.
If we allow the parameter to be learned, this is called parametric ReLU.
Another popular choice is ELU (exponential linear unit):
This has the advantage of being a smooth function.
A slight variant of ELU is known as SELU (self-normalizing ELU):
Surprisingly, it has been proven that by setting and carefully, the activation function ensures that the output of each layer is standardized (providing the input is also standardized), even without the use of techniques such as batch norm.
13.4.3.3 Other choices
Switch or SiLU (sigmoid rectified unit) appears to work well for image classification benchmarks and is defined as:
Another popular choice is GELU (Gaussian Error Linear Unit):
where is the cdf of the standard normal distribution:
We see that this is not a convex or monotonic function, unlike most activation functions.
We can think of GELU as a “soft” RELU since it replaces the step function with the Gaussian cdf.
See PyTorch's non-linear activations module (opens in a new tab) for an exhaustive list.
13.4.4 Residual connections
One solution to the vanishing problem is to use residual networks or ResNet. This is a feedforward model in which each layer has the form of a residual block:
where is a standard shallow non-linear mapping (e.g. linear-activation-linear).
Residual connections are often used conjointly with CNNs, but can also be used in MLPs.
A model with residual connections has the same number of parameters as without it but is easier to train. The reason is that gradient can flow directly from the output to the earlier layers.
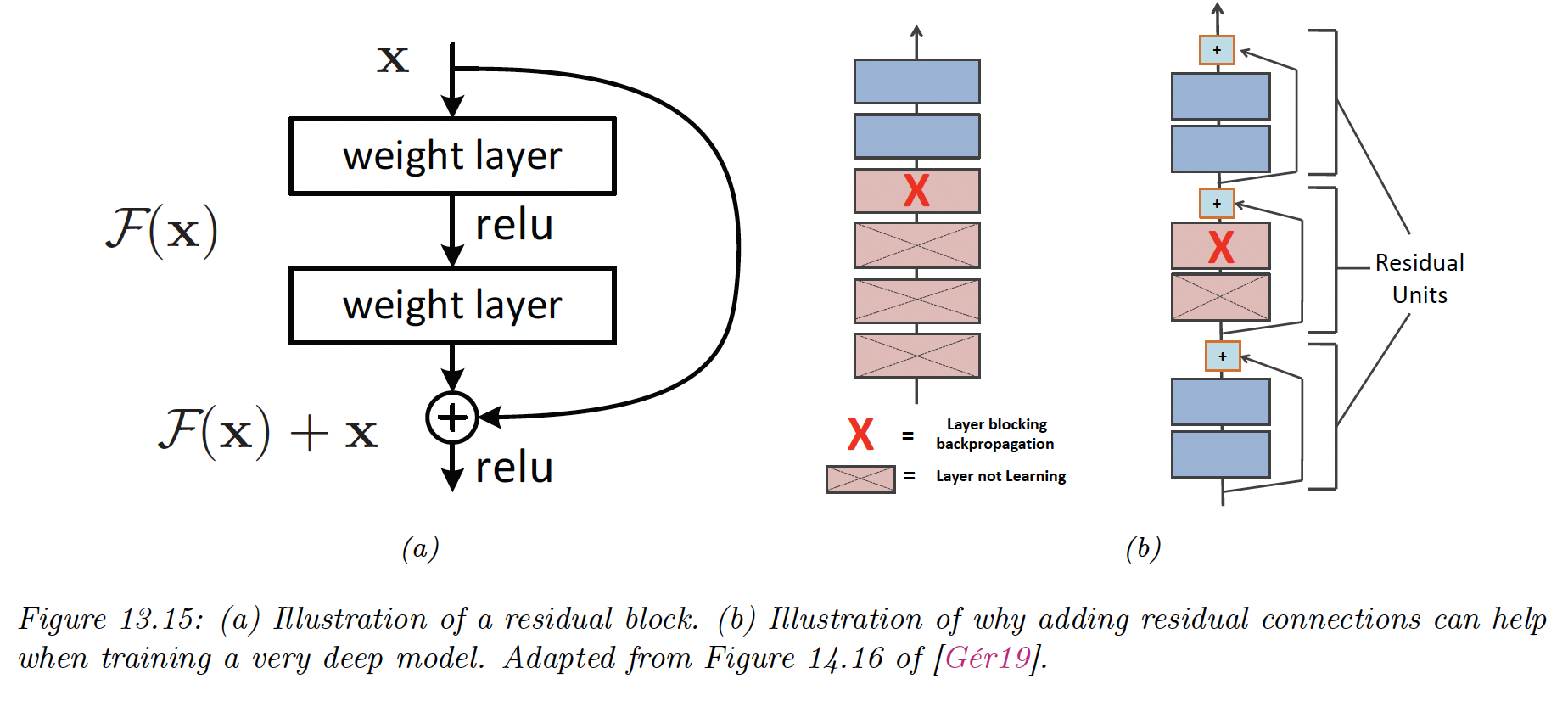
To see this, note that the activation at the output layer can be derived as:
We can therefore compute the gradient of the loss wrt the parameters of the th layer as follows:
We see that the gradient at layer depends directly on the gradient at layer , independently from the network depth.
13.4.5 Parameter initialization
Since the objective function of DNNs is non-convex, the initial values of parameters can play a big role in the final solution, as well as how easy the function is to train (i.e. how well signal can flow backward and forward in the model).
13.4.5.1 Heuristic initialization scheme
It has been shown that sampling parameters from a standard normal distribution with fixed variance can lead to exploding activation or gradient.
To see why, consider a linear unit where , , :
To keep the variance from blowing up, we need to ensure during forward pass, where is the fan-in (input connections).
When doing the backward pass, we need , where is the fan-out.
To satisfy both requirements we set:
or equivalently:
This is known as Xavier initialization (use it for linear, tanh, logistic and softmax activation function).
In the special case of , we use , this is LeCun initialization (use it for SELU).
Finally, is Hue initialization (use it for ReLU and variants).
13.4.5.2 Data-driven initialization
We can adopt a data-driven approach to parameter initialization, like layer-sequential unit-variance (LSUV), working as follow:
- Initialize the weights (fully connected or convolutional) using orthonormal matrices, by drawing then using QR or SVD decomposition.
- For each layer , compute the variance of activation across a minibatch
- Rescale the weights as
This can be viewed as orthonormal initialization combined with batch normalization applied on the first mini-batch. This is faster than full-batch normalization and can work just as well.
13.4.6 Parallel training
Training large networks can be slow, and specialized hardware for matrix-matrix multiplication like graphics processing units (GPU) and tensor processing unit (TPU) can boost this process.
If we have multiple GPU, we can further speed things up.
The first approach is model parallelism, in which we partition the model across different machines. This is quite complicated since this requires tight communication between machine and we won’t discuss it further.
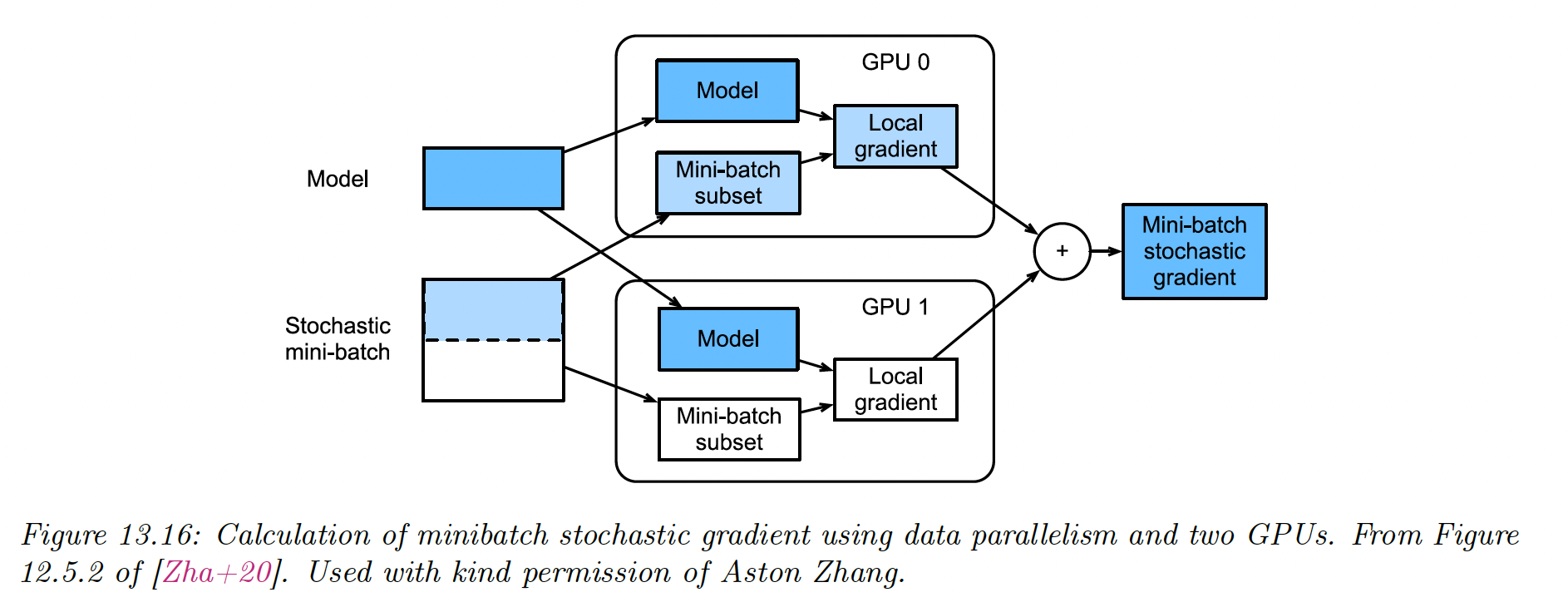
The second approach is data parallelism, which is much simpler as it is embarrassingly parallel. For each training step :
- We split the minibatch across machines to get .
- Each machine computes its own gradient
- We sum all gradient on a central machine
- We broadcast the summed gradient back to all machines,
- Each machine update its parameters using
See this tutorial (opens in a new tab) for a toy implementation in Jax, and this tutorial (opens in a new tab) for a more robust solution in PyTorch.