15.5 Transformers
The transformer model (opens in a new tab) uses attention in both the encoder and decoder, thus eliminating the need for RNN.
It has been used in a wide diversity of sequence generation tasks, like machine translation music generation, protein sequence generation and image generation (opens in a new tab) (treating images as a rasterized 1d sequence).
15.5.1 Self-attention
We saw in section 15.4.4 how the decoder section of an RNN could attend to the encoder to capture contextual embedding of each input.
We can modify this architecture so the encoder attends to itself. This is called self-attention.
Given a sequence of token , with , self-attention can generate output of the same size using:
where the query is and keys and values are all the inputs .
To use this in a decoder, we can set , and , so that all previously generated outputs are available. At training time, all the outputs are already known, so we run self-attention in parallel, overcoming sequential bottleneck of RNNs.
In addition to improve speed, self attention can give improved representation of context. For instance translating into french the sentences:
- “The animal didn’t cross the street because it was too tired”
- “The animal didn’t cross the street because it was too wide”
This phrase is ambiguous because “it” can refer to the animal or the street, depending on the final adjective. This is called coreference resolution.
Self attention is able to resolve this.

15.5.2 Multi-headed attention
If we think about attention matrix like a kernel matrix, we naturally want to use multiple attention matrix to capture different notion of similarity. This is the basic idea behind multi-headed attention (MHA).
Given a query , keys and values , , we define the th attention head as:
where , and are projection matrices.
We then stack the heads together, and project to :
with .
If we set , we can compute all heads in parallel.
See this code snippet (opens in a new tab).
15.5.3 Positional encoding
Vanilla self-attention is permutation invariant, hence ignores the input word ordering. Since this can lead to poor results, we can concatenate or add positional encodings to the word embeddings.
We can represent positional encodings as the matrix , where is the sequence length and is the embedding size.
The original Transformer paper suggests to use sinusoidal basis:
where corresponds to some maximum sequence length.
For , we have:
Below, we see that the leftmost columns toggle fastest. Each row has a blueprint representing its position in the sequence.
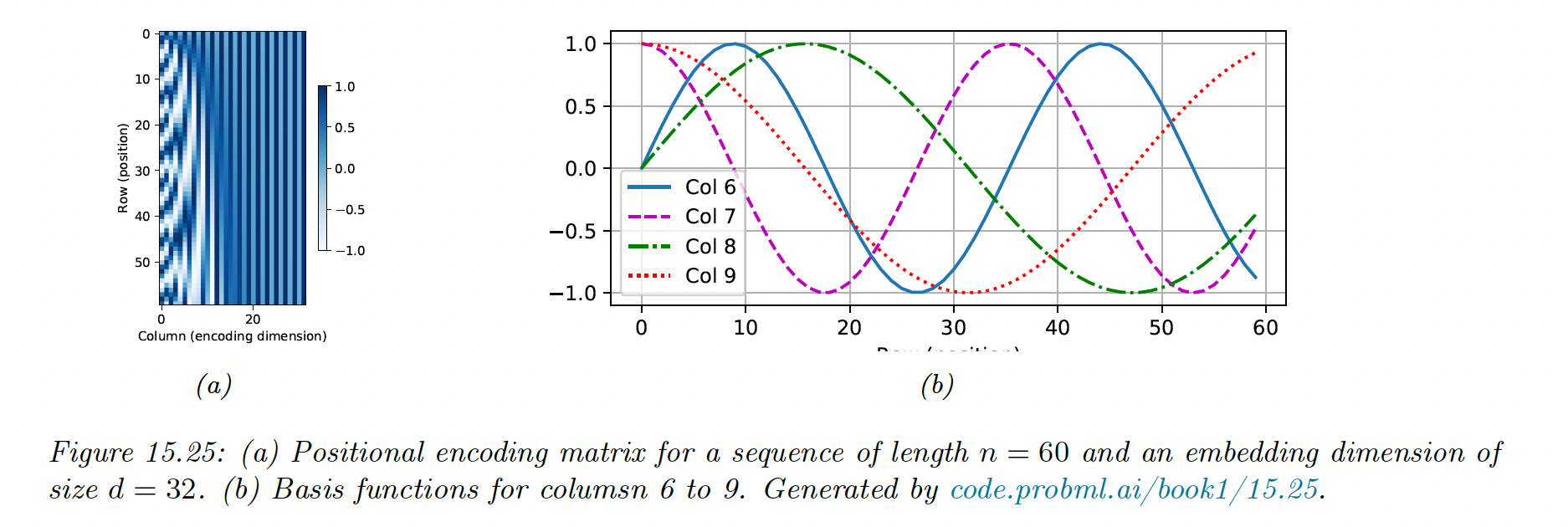
This representation has two advantages:
-
It can be computed for arbitrary sequence size , unlike a learned mapping from integers to vectors.
-
The representation of one location is linearly predictable from any other: , where is a linear transformation.
To see this last point, note that:
If is small, then . This provide a useful form of inductive bias.
Once we have computed the position embeddings , we need to combine them with the word embeddings :
We could also concatenate both matrix, but adding takes less space.
Additionally, since the embeddings are learned, the model could simulate concatenation by zeroing the first dimensions of and the last dimensions of .
15.5.4 Putting it all together
A transformer is a seq2seq model using self-attention in the encoder and decoder rather than an RNN.
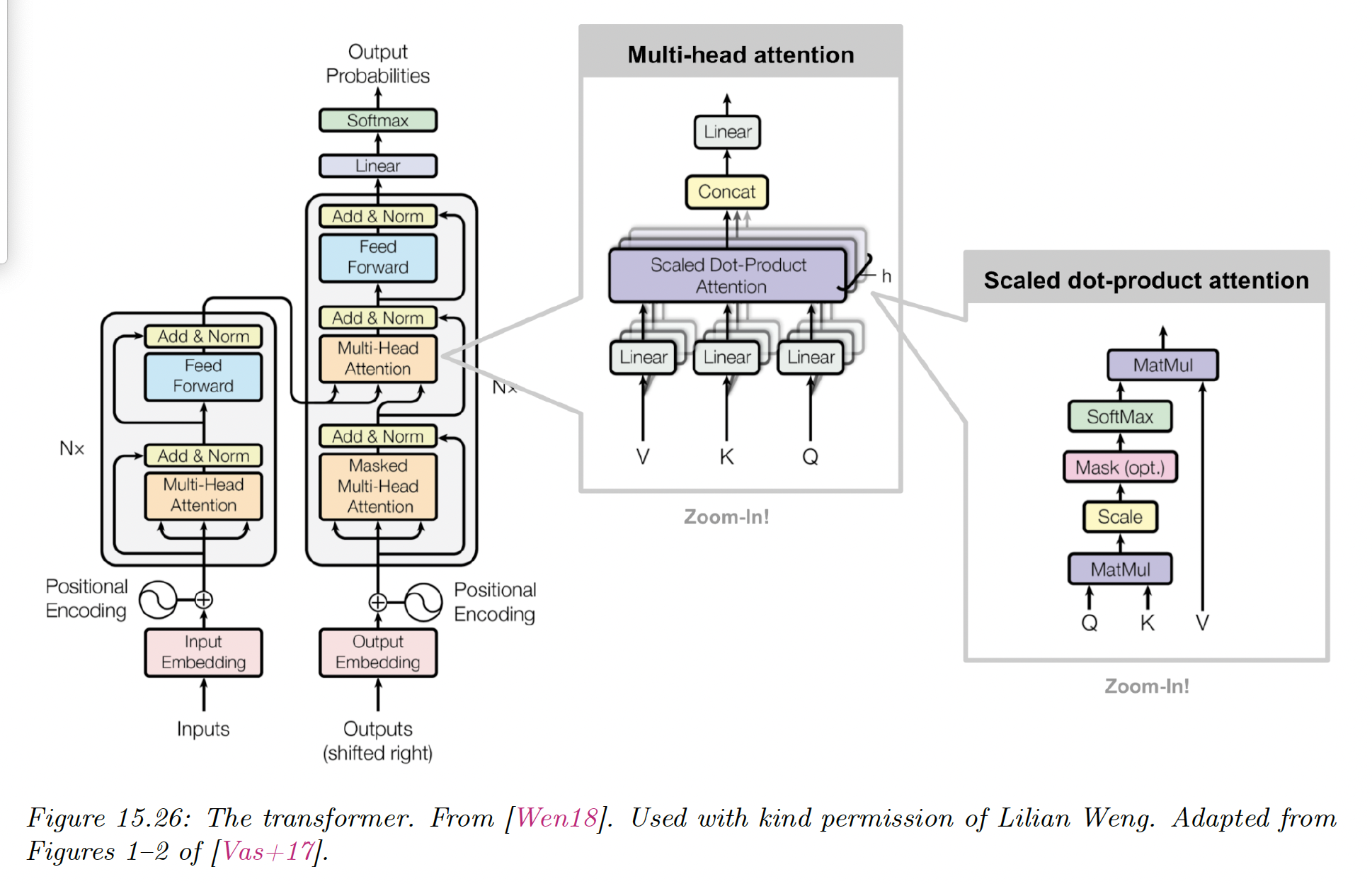
The encoder uses positional encoding, followed by a series of encoder blocks, each of which uses multi-head self-attention, residual connections and layer normalization.
def EncoderBlock(X):
Z = LayerNorm(MultiHeadAttn(Q=X, K=X, V=X) + X)
E = LayerNorm(FeedForward(Z) + Z)
return E
def Encoder(X, N):
E = POS(Embed(X))
for n in range(N):
E = EncoderBlock(E)
return EThe decoder has a more complex structure.
The previous generated outputs are shifted and then combined with a positional embedding.
Then, they are fed to a causal (masked) multi-head attention model, before combining the encoder embeddings in another MHA.
Finally, the probability distribution over tokens are computed in parallel.
def DecoderBlock(Y, E):
Z_1 = LayerNorm(MultiHeadAttn(Q=Y, K=Y, V=Y) + Y)
Z_2 = LayerNorm(MultiHeadAttn(Q=Z_1, K=E, V=E) + Z_1)
D = LayerNorm(FeedForward(Z_2) + Z_2)
return D
def Decoder(Y, E, N):
D = POS(Embed(Y))
for n in range(N):
D = DecoderBlock(D, E)
return DSee this notebook (opens in a new tab) for a tutorial.
Note that:
i) During training, teacher forcing is applied by using masked softmax. It processes all tokens of a sentence in a single pass, instead of looping for each one.
During inference however, we use a for-loop on the num_steps. If we consider a single sentence (), the initial decoder input is only [[”<bos>”]] (beginning of sequence):
Then, we take as input for the next loop the maximum of the output probabilities. Hence, the input stays a single token across loops.
However, state persists the input of the previous loops for each decoder layer, by concatenating it with the new input, resulting in .
In consequence, the first attention query is , but the key and values are the .
ii) The word embeddings of the source (resp. target) language are located in the embedding layer of the encoder (resp. decoder).
15.5.5 Comparing transformers CNNs and RNNs
We visually compare three different architectures to map a sequence to another sequence :
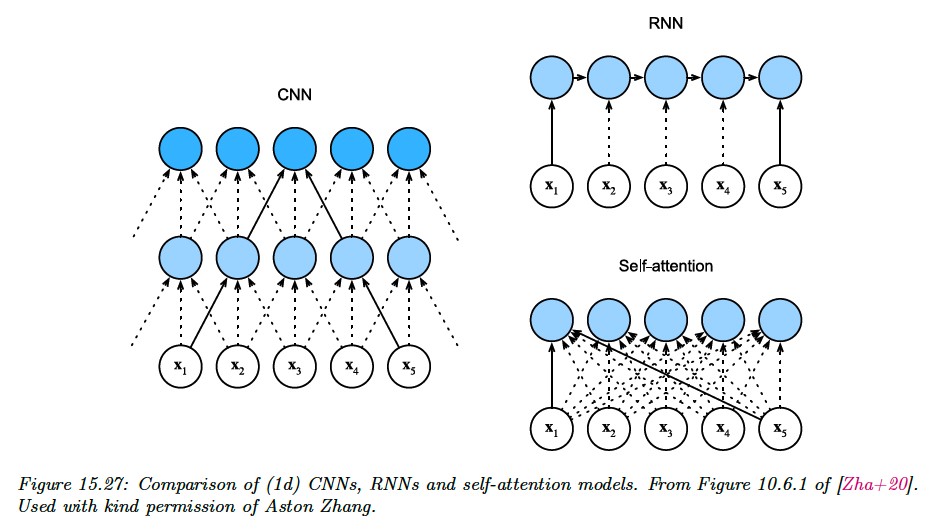
For a 1d CNN with kernel size and and feature channels, the time to compute is , which can be done in parallel. We need a stack of layers (or if we use dilated convolution, to ensure all pairs of inputs communicate.
For a RNN, the computational complexity is , because for a hidden state of size we have to perform matrix-vector multiplication at each step.
Finally, for self-attention models, every output is directly connected to every input. However, the computational cost is , which is fine for short sequence where . For longer sequence, we need fast versions of attention, called efficient transformers.

15.5.6 Transformers for images
CNNs are the most common model type for processing image data, since they have useful built-in inductive bias, locality (due to small kernel), equivariance (due to weight tying) and invariance (due to pooling).
Surprisingly, transformers can also perform well at image classification, but they need a lot of data to compensate for the lack of relevant inductive bias.
The first model of this kind is ViT (vision transformer), which chop images into 16x16 patches, project each patch into an embedding space, and passes these patches as a sequence to a transformer.
The input is also prepended with a special [CLASS] embedding, . The output of the encoder is a set of encodings , the model maps to the target class , and is trained in a supervised way.
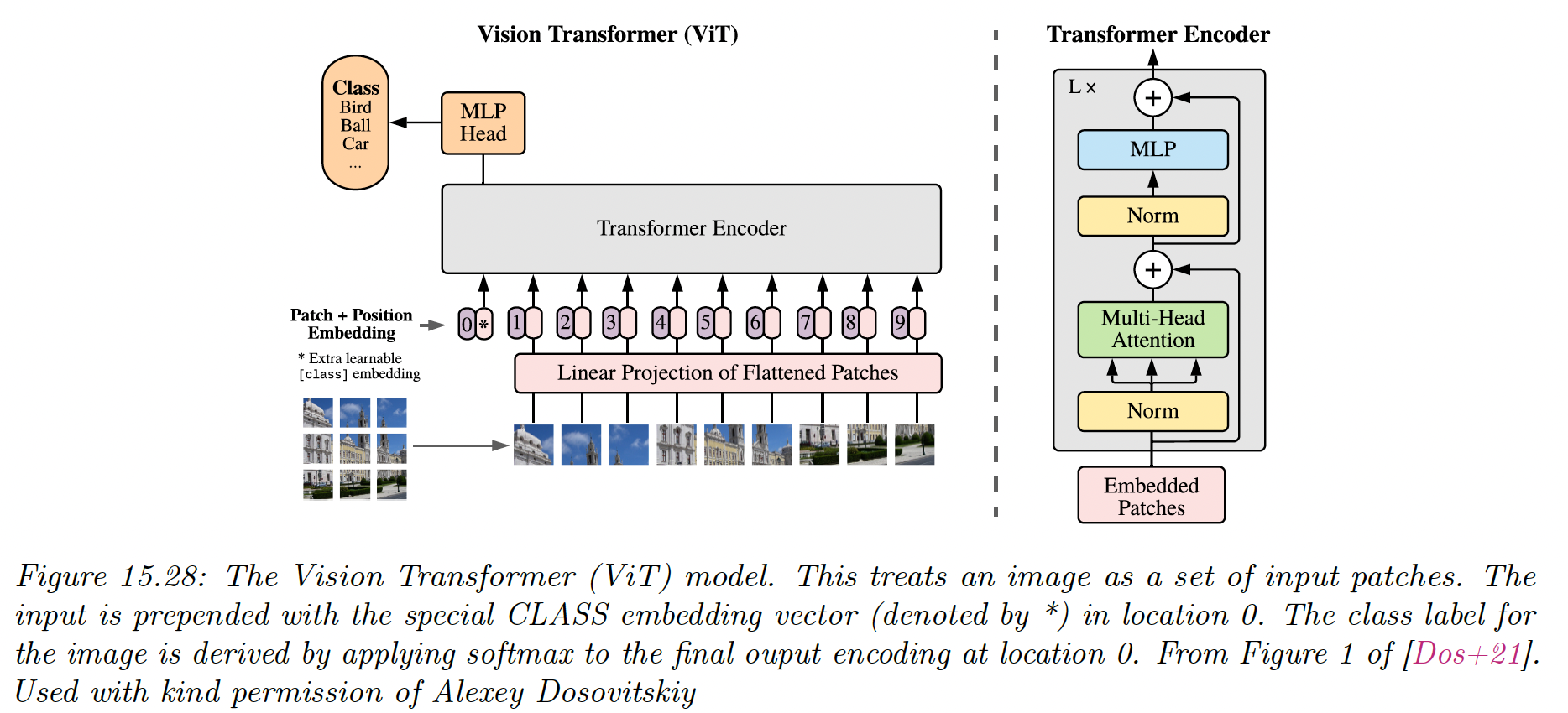
After supervised training, the model is fine-tuned on various downstream classification tasks, an approach known as transfer learning.
When trained on a “small dataset” like ImageNet (1k classes, 1.3m images), ViT can’t outperform a pretrained ResNet model known as BiT (Big transfer).
However, when trained on a bigger dataset, like ImageNet-21k (21k classes, 14m images) or the Google-internal JFT dataset (18k classes, 303m images), ViT outperforms BiT at transfer learning, and matches ConvNext performances.
ViT is also cheaper to train than ResNet at this scale (however, training is still expensive, the large ViT model on ImageNet-21k takes 30 days on a Google Cloud TPUv3 with 8 cores).
15.5.7 Other transformer variants
Many extensions of the transformer have been proposed.
For example, Gshard scales up transformers to even more parameters by replacing some of the feed forward dense layer with a mixture of experts regression module. This allows for sparse conditional computation, where a subset of the model (chosen by a gate) is used.
Conformer adds convolutional layer inside the transformer, which is helpful for various speech recognition tasks.