8.3 Second-order methods
First-order methods only exploit the gradient of the loss function, which is cheap to compute but can be imprecise. Second-order methods leverage the curvature of the loss using the Hessian.
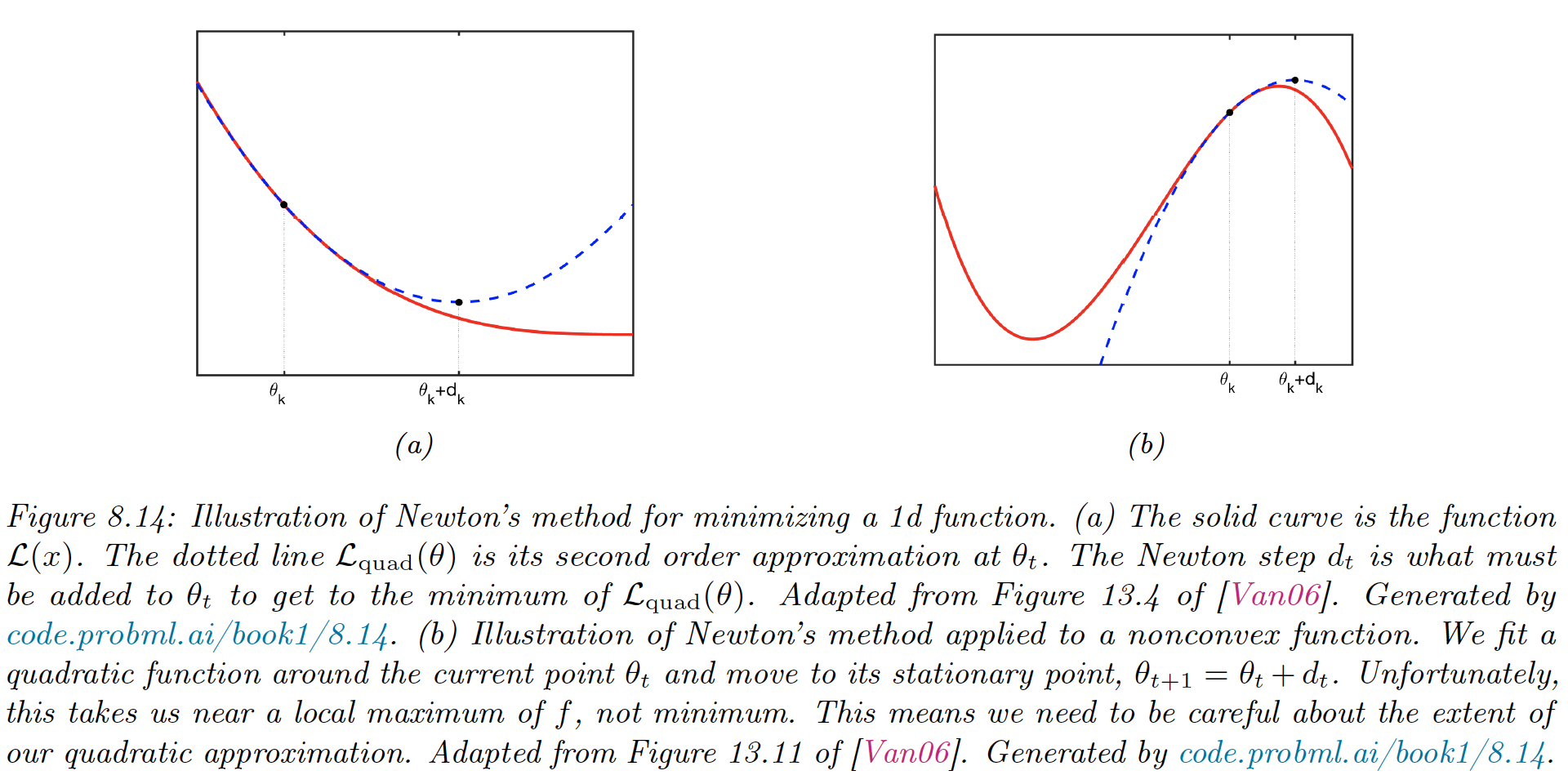
8.3.1 Newton’s method
The classic second-order method is Newton’s method, whose update is:
where is assumed positive-definite. The intuition is that “undoes” the skewness in the local curvature.

To see why, consider the Taylor series approximation of around :
The differential w.r.t gives:
8.3.2 BFGS
Quasi-Newton methods iteratively build up an approximation to the Hessian, using information about the gradient at each step:
with and
If is positive definite and the step size is chosen via line search satisfying the Armiko condition and the curvature condition:
with , then remains positive definite.
Typically, .
Alternatively, BFGS can iteratively update an approximate the inverse of the Hessian:
Since storing the Hessian approximation still takes space, for very large problems the limited memory (L-BFGS) is preferred.
Rather than storing , we store the most recent and then approximate by performing a sequence of inner products with the stored and vectors.
between 5-20 is often sufficient.
8.3.3 Trust region methods
If the objective function is non-convex, then the Hessian may not be positive definite, so may not be the descent direction. In general, any time the quadratic approximation made by Newton’s method is invalid, we are in trouble.
However, there is usually a local region around the current iterate where we can safely approximate the objective by a quadratic.
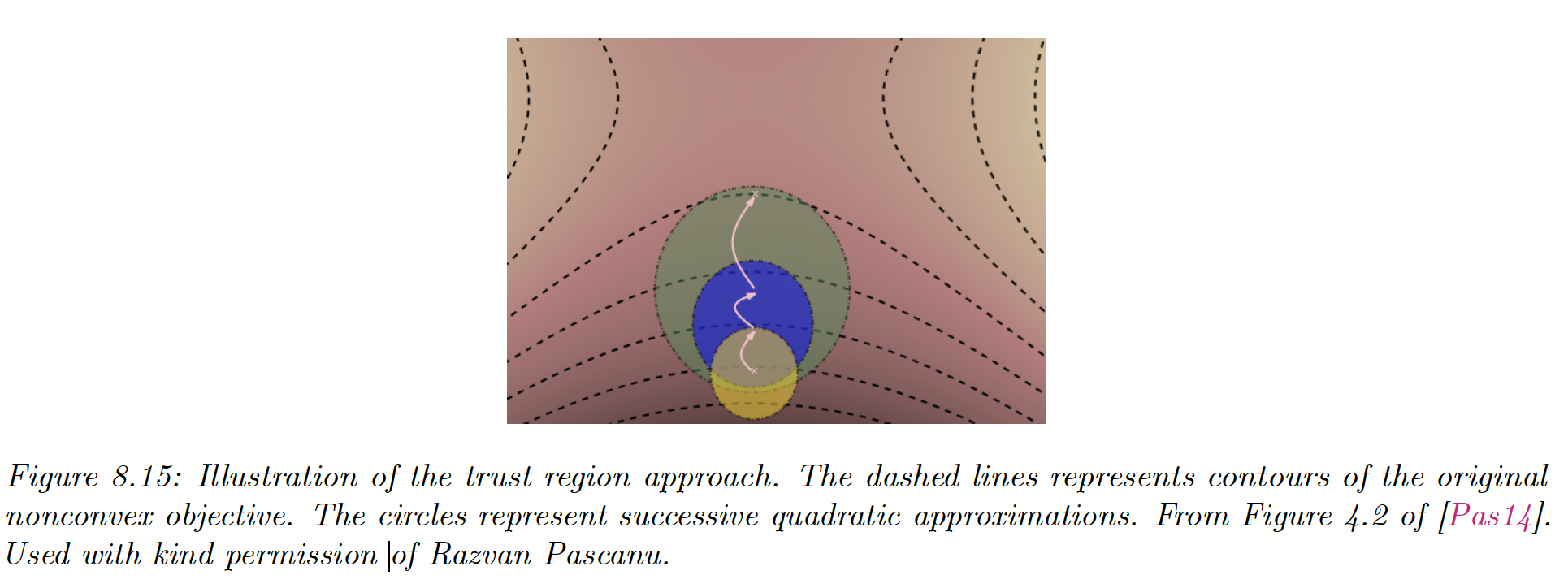
Let the approximation to the objective, where . At each step, we solve:
this is called trust-region optimization.
We usually assume is a quadratic approximation:
We assume that the region is a ball:
The constraint problem becomes an unconstrained one:
for some Lagrange multiplier .
We can solve this using:
This is called Tikhonov regularization, adding a sufficiently large ensure that the resulting matrix is always positive definite.
See Beyond auto-differentiation (opens in a new tab) from Google AI using trust region and quadratic approximations.