10.3 Multinomial logistic regression
In multinomial (or multiclass) logistic regression, the labels are mutually exclusive. This has the following form:
with:
-
-
is the input vector
-
the weight matrix, if we ignore the bias term ,
Because of the normalization condition, we can set , so that
-
the softmax function
This can be written as:
In multi-label logistic regression, we want to predict several labels for a given example.
This can be viewed as , with the form:
10.3.1 Linear and non-linear boundaries
Logistic regression computes linear decision boundaries in the input space.
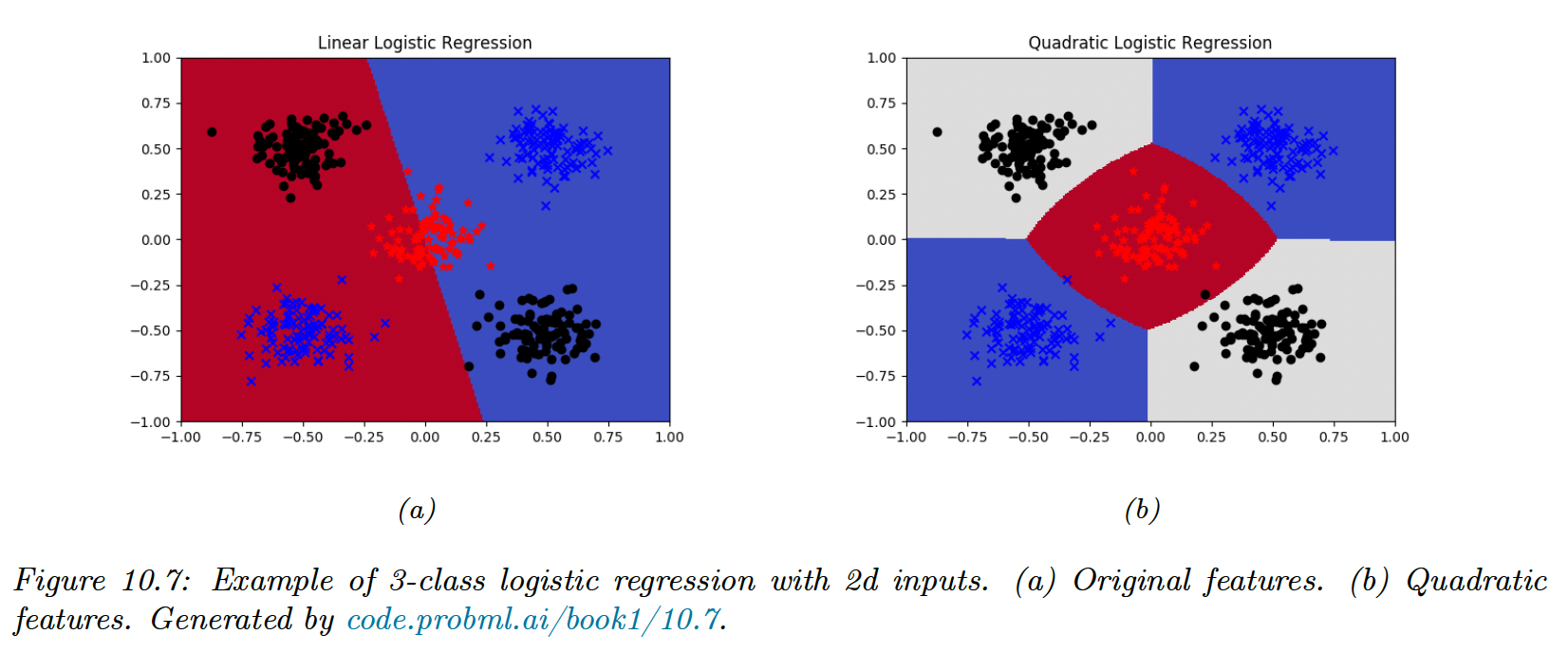
In this example we have classes and .
We can transform the inputs to create non-linear boundaries (here quadratic):
10.3.2 Maximum Likelihood Estimation
10.3.1.1 Objective
The NLL is given by:
where:
- is the one-hot encoding of the label, meaning
To find the optimum, we need to solve , where is a vectorized version of . We derive the gradient and Hessian and prove that the objective is convex.
10.3.1.3 Deriving the gradient
We derive the Jacobian of the softmax function:
If we have 3 classes, the Jacobian matrix is:
In the matrix form, this can be written:
Let’s now derive the gradient of the NLL w.r.t , the vector of weights associated to the class :
We can repeat this operation for all classes and sum all examples, to get the matrix:
10.3.1.4 Deriving the Hessian
We can show that the Hessian of the NLL of a single example is:
Where is the Kronecker product.
The block submatrix is given by:
10.3.3 Gradient-based optimization
Based on the binary results, using the gradient to perform SGD is straightforward. Computing the Hessian is expensive, so one would prefer approximating it with quasi-Newton methods like the limited memory BFGS.
Another similar method to IRLS is Bound optimization.
10.3.4 Bound optimization
If is a concave function we want to maximize, we can obtain a valid lower bound by bounding its Hessian i.e. find such that .
We can show that:
The update becomes:
This is similar to a Newton update, except we use a fixed matrix . This gives us some of the advantages of the second-order methods at lower computational cost.
We have seen that the Hessian can be written as:
In the binary case:
The update becomes:
Compared to the IRLS:
where
Thus we see that this lower bound is faster since can be precomputed.
10.3.5 MAP estimation
The benefits of regularization hold in the multi-class case, with additional benefits about parameter identifiability. We say that the parameters are identifiable iff there is a unique value that maximizes the likelihood, i.e. the NLL is strictly convex.
We can arbitrarily “clamp” , say for example for the class we define
The parameters will be identifiable.
If we don’t clamp but add a regularization, the parameters will still be identifiable.
At the optimum, we can show that we have for , therefore the weights automatically satisfy a sum-to-zero constraint, making them uniquely identifiable.
10.3.7 Hierarchical classification
When the predicted labels can be structured as a taxonomy, it makes sense to perform hierarchical classification.
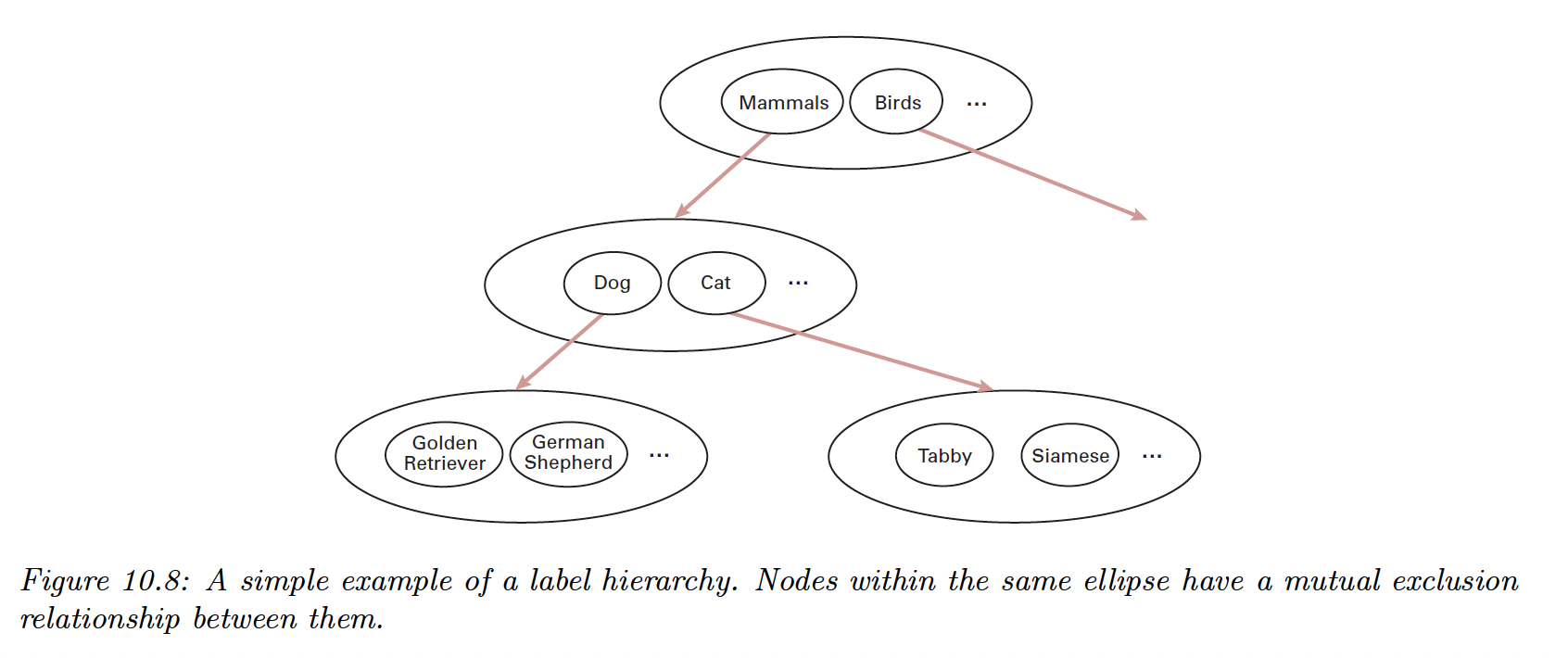
We define a model with a binary target for all of its leaves. Then we apply label smearing (we activate the label of a parent when a child is activated).
If we train a multi-label classifier, it will perform hierarchical classification.
However, since the model doesn’t capture that some labels are mutually exclusive, we add exclusion constraints to labels that are siblings. For example, we enforce:
since these 2 labels are children of the root node. We can further the partition as:
10.3.8 Handling large number of classes
In this section, we discuss the issues that arise when there is a large number of potential classes, like in NLP.
10.3.8.1 Hierarchical softmax
In regular softmax, computing the normalizing term can become the bottleneck since it has a complexity of .
However, by structuring the labels as a tree, we can compute any labels in times, by multiplying the probabilities of each edge from the root to the leaf.
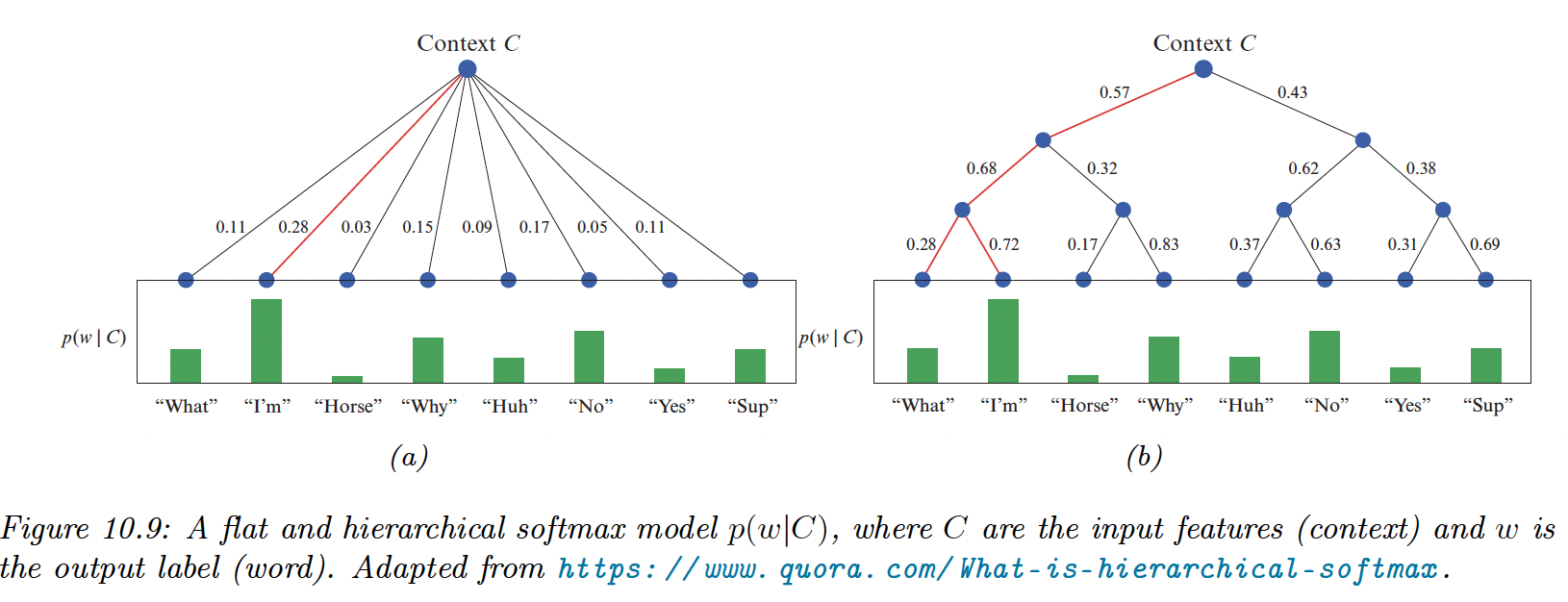
A good way to structure it is to use Huffman encoding, with the most frequent labels on top.
10.3.8.2 Class Imbalance and the long tail
Another issue is having very few examples for most labels, resulting in extreme class imbalance and the model focusing only on the most common labels.
i) One method to mitigate this is to set the bias term such as:
so that the model will match the empirical prior even if . As the model adjusts its weights, it learns input-dependent deviations from the prior.
ii) Another popular approach is resampling to make it more balance during training. In particular, we sample a point from class with probability:
If , we recover the instance-balanced sampling, where the common classes will be sampled more often.
If , we recover class-balanced sampling, where we sample a class uniformly at random, and then sample an instance of this class.
We can consider other options, like , called the square-root sampling
iii) We can also consider the nearest class mean classifier:
where
If we replace with learned features , like after a Neural Net trained using the cross-entropy loss on the original unbalanced dataset, we can get very good performance on the long tail.