8.5 Constrained Optimization
We consider the following problem:
where the feasible set is:
with is the set of equality constraints and the set of inequality constraints.
8.5.1 Lagrange Multipliers
Let’s have a single constrained .
We know that the gradient of the loss and the gradient of the constraint are (anti-?)parallel at some point minimizing .
-
proof
If we move by on the constraint surface we have:
As we have , we must have .
We seek a point on the constrained surface minimizing . must also be orthogonal to the constraint surface, otherwise we could decrease the objective by just moving on the surface.
for some .
This leads to the objective:
At a stationary point, we have:
This is called a critical point.
If we have constraints, we can add them:
We end up with equations for variables and can use unconstrained optimization methods to solve this system.
Exemple
We minimize , subject to the constraint .
The Lagrangian is:
Therefore we need to solve:
8.5.2 The KKT conditions
We introduce inequality constraints :
However, this is a discontinuous function that is hard to optimize.
Instead, we can consider
and our optimization problem becomes:
The general Lagrangian becomes:
When and are convex, then all critical points must satisfy the Karush-Kuhn-Tucker (KKT) conditions:
-
All constraints are satisfied (feasibility)
-
The solution is a stationary point:
-
The penalty for the inequality constraints points in the right direction (dual feasibility):
-
The Lagrange multiplies pick up any slack in the inequality constraints:
If the is convex and the constraints define a convex set, then the KKT conditions are sufficient to ensure global optimality.
8.5.3 Linear Programming
We optimize a linear function subject to linear constraints, represented as:
The feasible set defines a convex polytope: a convex space defined as an intersection of half-spaces.
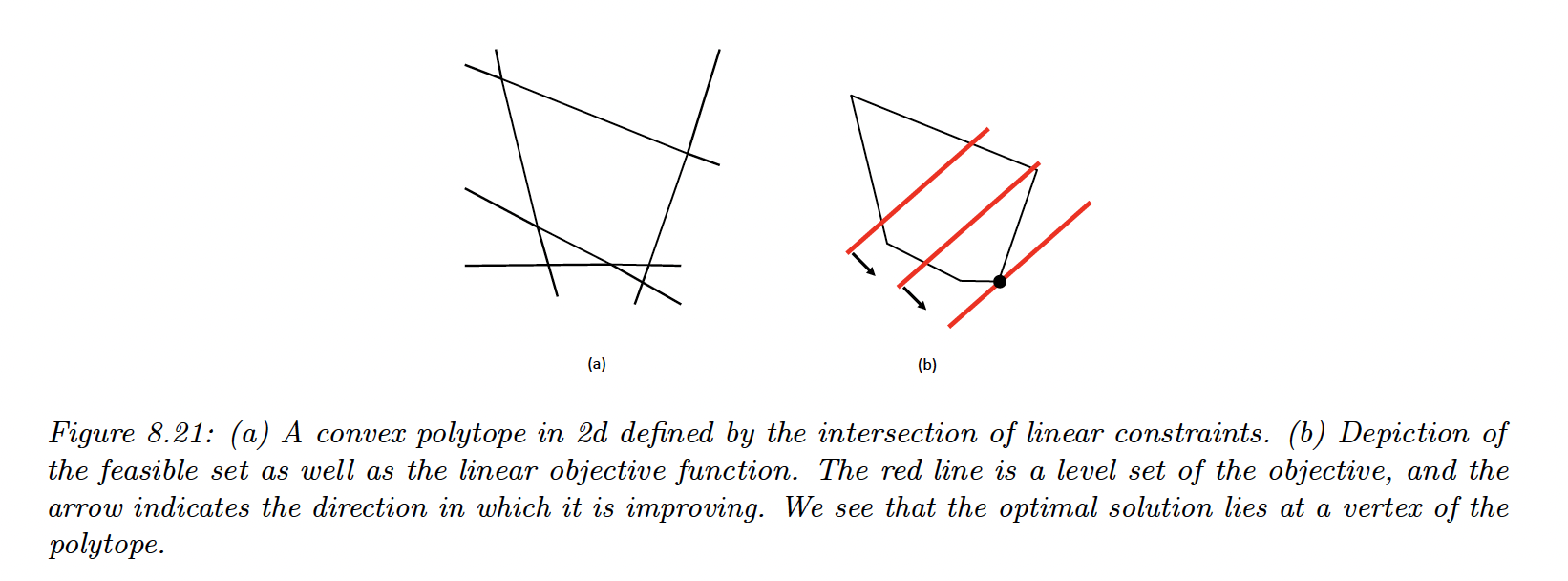
8.5.3.1 The simplex algorithm
It can be shown that the optima of an LP occur at the vertex of the polytope defining the feasible set.
The simplex algorithm solves LPs by moving from vertex to vertex, seeking the edge that most improve the objective.
8.5.3.2 Applications
Applications range from business to machine learning, in robust linear regression settings. It is also useful for state estimation in graphical models.
8.5.4 Quadratic programming
We optimize a quadratic function:
If is semi-positive, then this is a convex problem.
Example
Let’s consider:
with and
Subject to
We can decompose the above constraint into:
We can write as , with
This is now in the standard QP form.
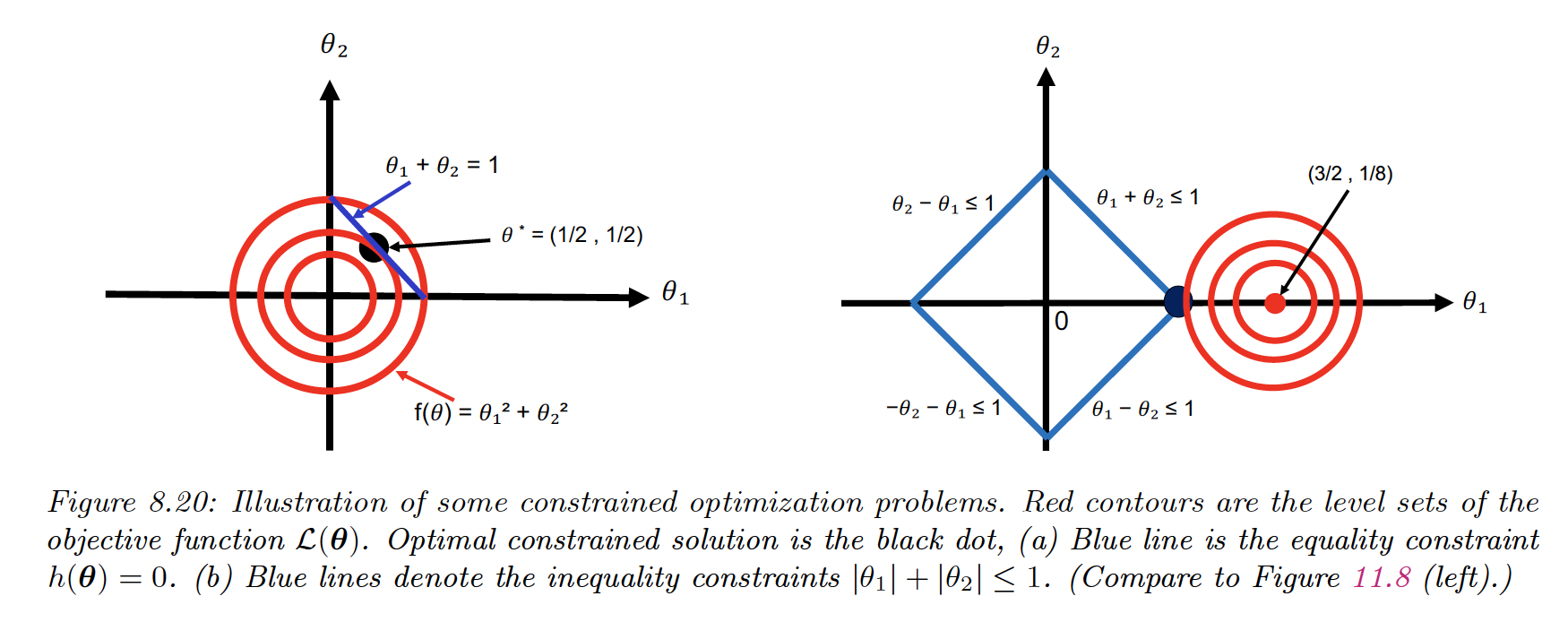
We see that the 2 edges of the diamond to the left are inactive because the objective is in the opposite directions.
This means and and by complementarity
From the KKT conditions, we know that:
This gives us:
The solution is
8.5.4.1 Applications
QP programming is used in the lasso method for sparse linear regression, which optimizes:
It can also be used for SVM.