7.7 Solving systems of Linear Equation
We can formulate linear equations in the form of .
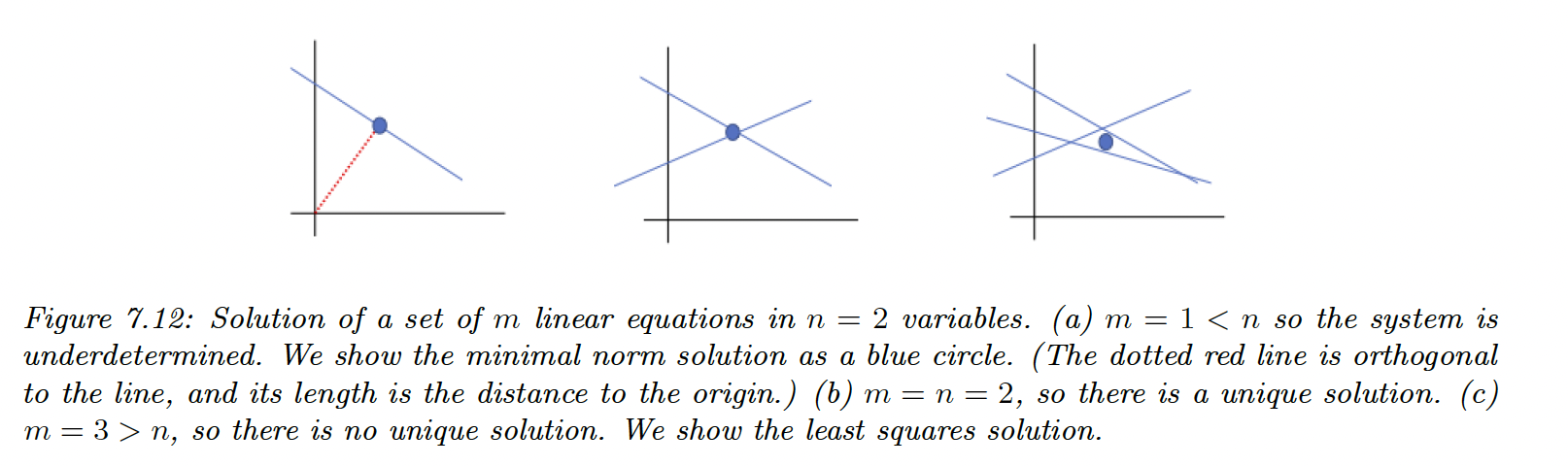
If we have equations and unknowns, then will be a matrix and a vector.
- If and is full rank, there is a single unique solution
- If the system is underdetermined so there is no unique solution
- If the system is overdetermined, not all the lines intersect at the same point
7.7.1 Solving square systems
When , we can solve the LU decomposition for .
The point is that and are triangular, so we don’t need to compute the inverse and can use back substitution instead. For
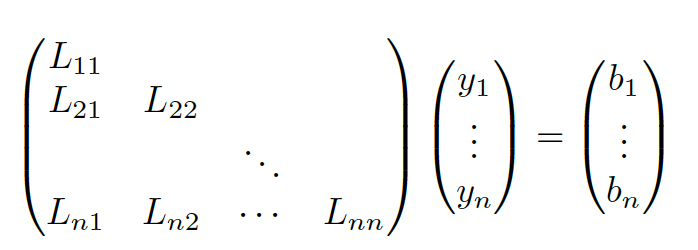
We start by solving , then we substitute it into and iterate.
Once we have , we can apply the same computation for .
7.7.2 Solving under-constrained systems (least norm estimation)
We assume and to be full-rank, so there are multiple solutions:
Where is any solution. It is standard to pick the solution minimizing the regularization:
We can compute the minimal norm solution using the right pseudo inverse:
We can also solve the constrained optimization problem by minimizing the norm:
Therefore:
Finally we find the right pseudo inverse again:
7.7.3 Solving over-constrained systems (least square estimation)
If , we’ll try to find the closest solution satisfying all constrained specified by , by minimizing the least square objective:
We know that the gradient is:
Hence the solution is the OLS:
With the left pseudo inverse.
We can check that this solution is unique by showing that the Hessian is positive definite:
Which is positive definite if is full-rank since for any we have: