5.3 Frequentist decision theory
In frequentist decision theory, we don’t use prior and thus no posterior, so we can’t define the risk as the posterior expected loss anymore.
5.3.1 Computing the risk of an estimator
The frequentist risk of an estimator , applied to data sampled from the likelihood :
Exemple
We estimate the true mean of a Gaussian. Let . We use a quadratic loss, so the risk is the MSE.
We compute the risk for different estimators, the MSE can be decomposed:
with .
- is the sample mean. This is unbiased, so its risk is:
- . This is also unbiased. One can show its variance is approximately:
- returns the constant so its biased is , and its variance is zero. Hence:
- is the posterior mean under a prior:
We can derive its MSE as follow:
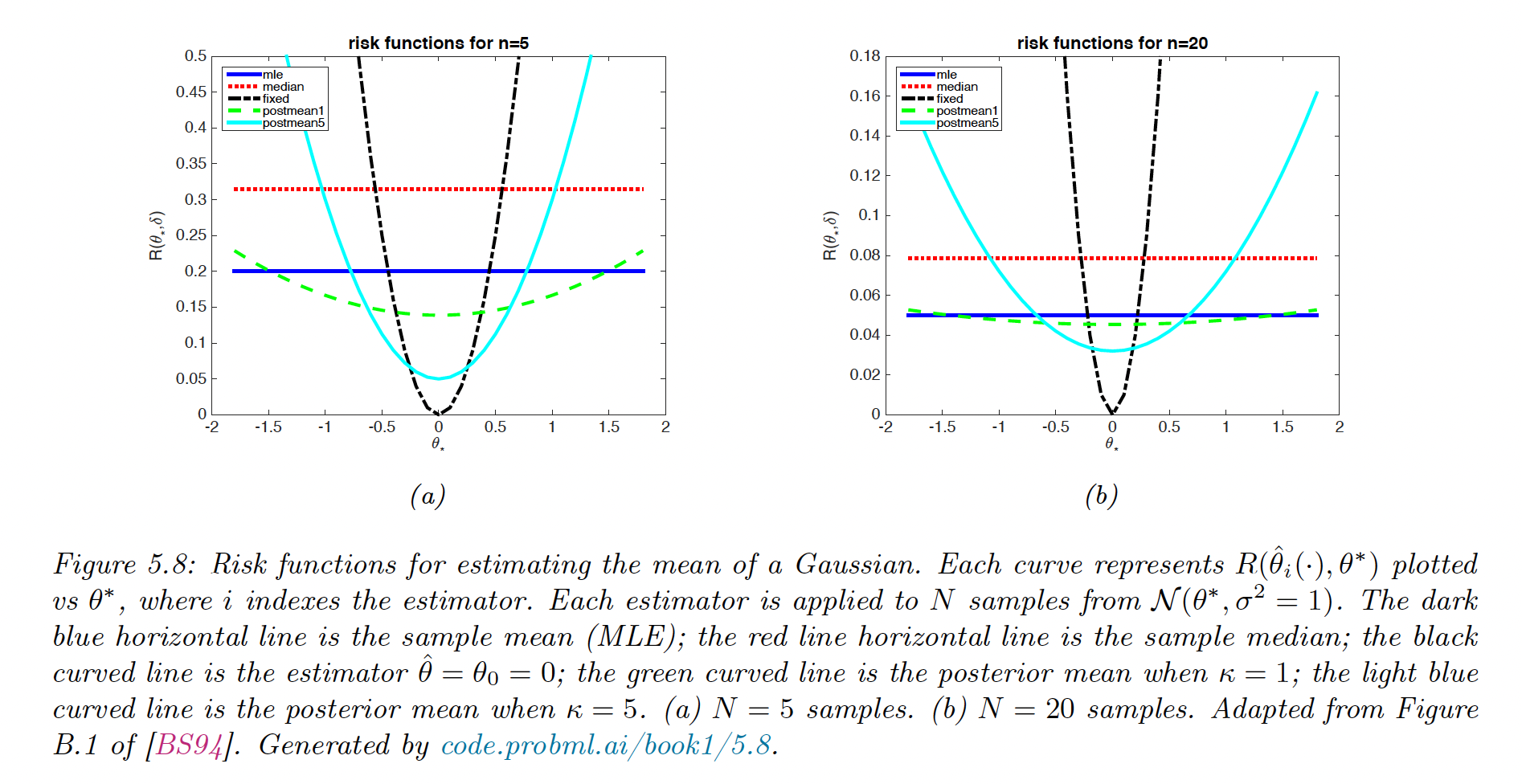
The best estimator depends on , which is unknown. If is far from , the MLE is best.
Bayes risk
In general the true distribution of is unknown, so we can’t compute . One solution is to average out all values of the prior for . This is the Bayes risk or integrated risk.
The Bayes estimator minimizes the Bayes risk:
which corresponds to optimal policy recommended by Bayesian decision theory here.
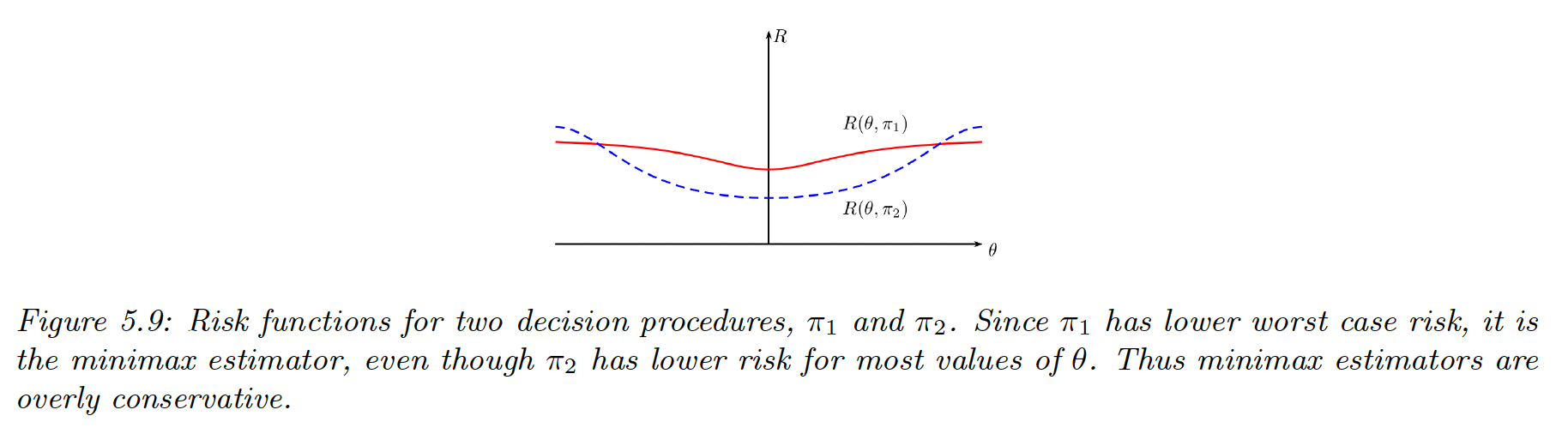
Maximum risk
To avoid using a prior in frequentist, we can define the maximum risk:
To minimize the maximum risk, we use minimax . Computing them can be hard though.
5.3.2 Consistent estimators
An estimator is consistent when as , where the arrow is the convergence in probability.
This is equivalent to minimizing the 0-1 loss .
An example of consistent estimator is the MLE.
Note that an estimator can be unbiased but not consistent, like . Since this is unbiased, but the sampling distribution of doesn’t converge to a fix value so it is not consistent.
In practice, it is more useful to find some estimators that minimize the discrepancy between our empirical distribution and the estimated distribution . If this discrepancy is the KL divergence, our estimator is the MLE.
5.3.3 Admissible estimators
dominates if:
An estimator is admissible when it is not dominated by any others.
In figure 5.8 above, we see that the risk of the sample median is dominated by the sample mean .
However this concept of admissibility is of limited value, since is admissible even though this doesn’t even look at the data.