21.1 Introduction
Clustering is a very common form of unsupervised learning. There are two main kinds of method.
In the first approach, the input is a set of data samples , where typically .
In the second approach, the input is a pairwise dissimilarity matrix , where .
In both cases, the goal is to assign similar points to the same cluster. As often with unsupervised learning, it is hard to evaluate the quality of a clustering algorithm.
If we have labels for some points, we can use the similarity between the labels of two points as a metric for determining if the two inputs “should” be assigned to the same cluster or not.
If we we don’t have labels, but the method is based on generative model of the data, we can use log likelihood as a metric.
21.1.1 Evaluating the output of clustering methods
If we use probabilistic models, we can always evaluate the likelihood of the data, but this has two drawbacks:
- It does not assess the clustering discovered by the model
- It does not apply to non-probabilistic methods
Hence, we review performance measures not based on likelihood.
Intuitively, similar points should be assigned to the same cluster. We can rely on some external form of data, like labels or a reference clustering, by making the hypothesis that objects with the same label are similar.
21.1.1.1 Purity
Let be the number of objects in cluster that belong to class , with be the total number of objects in cluster .
Define the empirical probability of the class in cluster .
We define the purity of a cluster as:
and the overall purity of a clustering as:
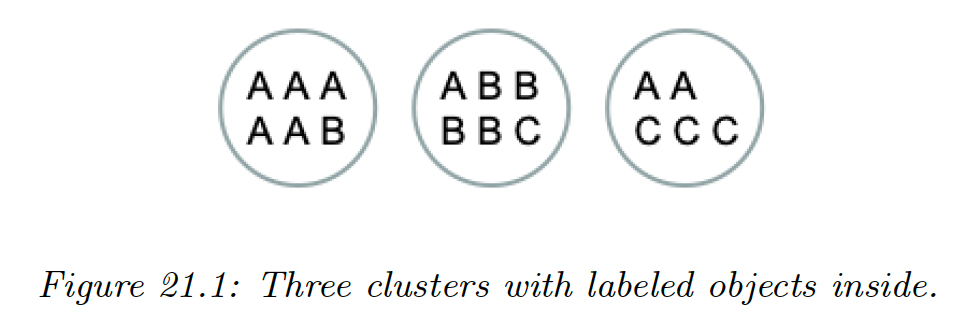
On the figure above we have:
However, this measure doesn’t penalize the number of cluster, since we can achieve the best purity of by trivially putting each object in its own cluster.
21.1.1.2 Rand index
Let and two different partition of the data points. For example, could be the estimated clustering and some reference clustering derived from the class labels.
A common statistics is the Rand index:
which is analogous to the accuracy for classification.
21.1.1.3 Mutual information
where:
- is the probability that a randomly chosen object belong to the cluster in and in
- be the probability that a randomly chosen object belong to the cluster .
This lies between 0 and .
Unfortunately, the maximum can be achieved by using a lot of small clusters, which have low entropy.
To compensate for this, we can use the normalized mutual information:
This lies between and