15.3 1d CNNs
CNNs are usually for 2d inputs, be can alternatively be applied to 1d sequences.
1d CNNs are an interesting alternative to RNNs because they are easier to train, since they don’t need to maintain long term hidden state.
15.3.1 1d CNNs for sequence classification
In this section, we learn the mapping , where is the length of the input, the number of feature per input, and the size of the output vector.
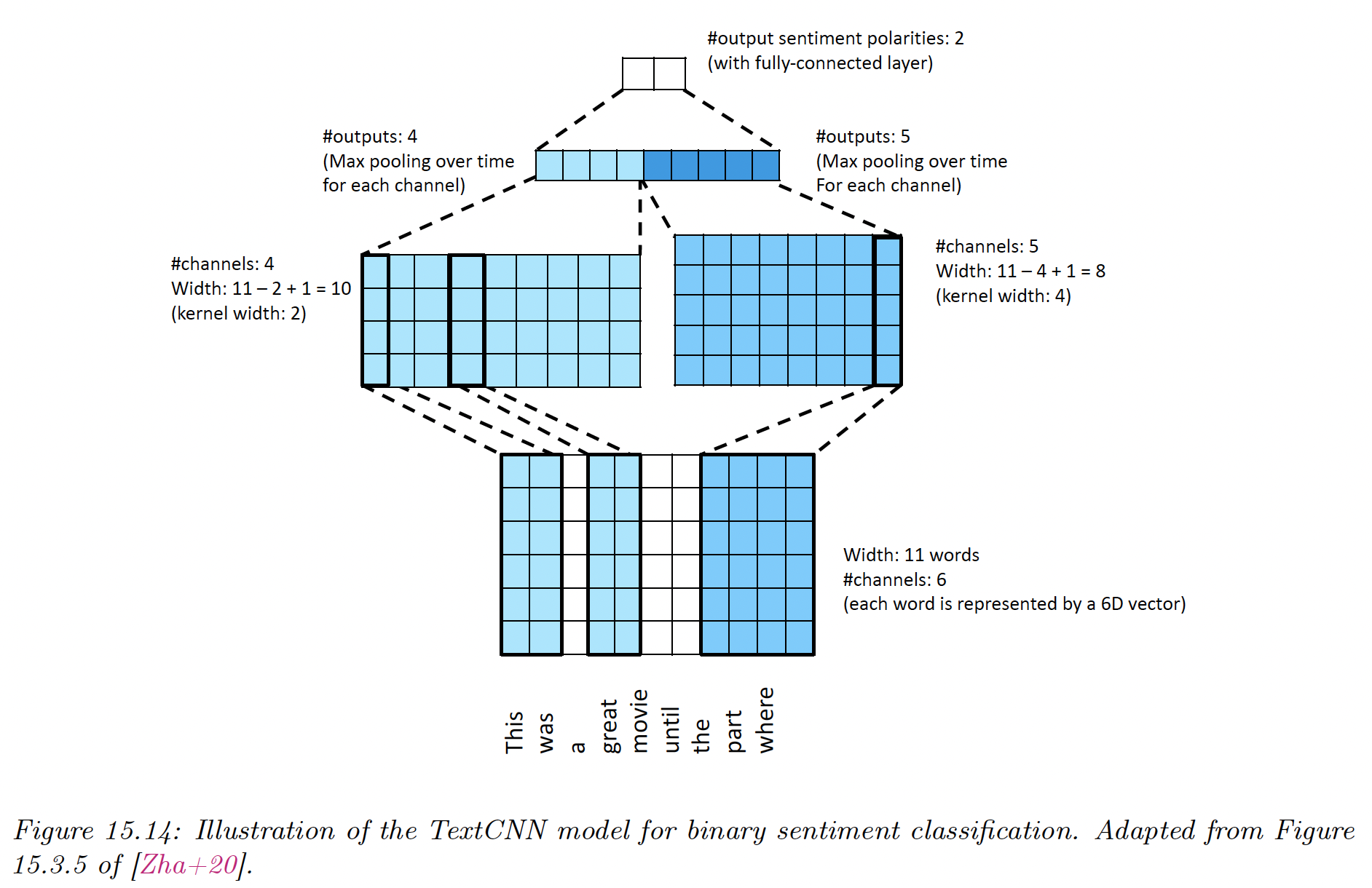
We begin with a lookup of each of the word embeddings to create the matrix .
We can then create a vector representation for each channel with:
This implements a mapping from to .
We then reduce this to a vector using a max-pooling over time:
Finally, a fully connected layer with a softmax gives the prediction distribution over the label classes.
15.3.2 Causal 1d CNNs for sequence generation
To use 1d CNNs in generative context, we must convert them into causal CNNs, in which each output variable only depends on previously generated variables (this is also called convolutional Markov model).
We define the model as:
where is the convolutional filter of size .
This is like regular 1d convolution except we masked future inputs, so that only depends on past observations. This is called causal convolution.
We can use deeper model and we can condition on input features .
In order to capture long-range dependencies, we use dilated convolution.
Wavenet (opens in a new tab) perform text to speech (TTS) synthesis by stacking 10 causal 1d convolutional layer with dilation rates 1, 2, 4…, 512. This creates a convolutional block with an effective receptive field of 1024.
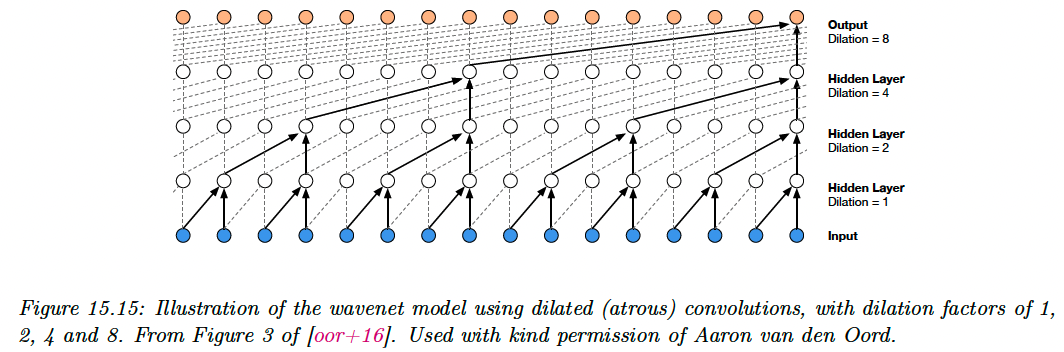
They left-padded each input sequence with a number of zeros equal to the dilation factor, so that dimensions are invariant.
In wavenet, the conditioning information is a set of linguistic features derived from an input sequence of words; but this paper (opens in a new tab) shows that it’s also possible to create a fully end-to-end approach, starting with raw words rather than linguistics features.
Although wavenet produces high quality speech, it is too slow to run in production. Parallel wavenet (opens in a new tab) distils it into a parallel generative model.