4.7 Frequentist statistics
4.7.1 Sampling distribution
In frequentist statistics, uncertainty is represented by the sampling distribution on an estimator.
-
An estimator is a decision procedure mapping observed data to an action (here the action is a parameter vector).
We denote it by , where can be the MLE, MAP estimate or MOM estimate.
-
The sampling distribution is the distribution of results if we applied the estimator multiple times to different datasets from some distribution
We sample different datasets of size from some true model :
For brevity, we denote it
If we apply the estimator to each :
We typically need to approximate it with Monte Carlo.
4.7.2 Gaussian approximation of the sampling distribution of the MLE
The most common estimator is the MLE.
When the sample size becomes large, the sampling distribution of the MLE becomes Gaussian:
is the Fisher information matrix (FIM). It measures the amount of curvature of the log-likelihood at its peak.
One can show that the FIM is also the Hessian of the NLL:
A log-likelihood function with high curvature (a large Hessian) will result in a low variance estimate since the parameters are well determined by the data.
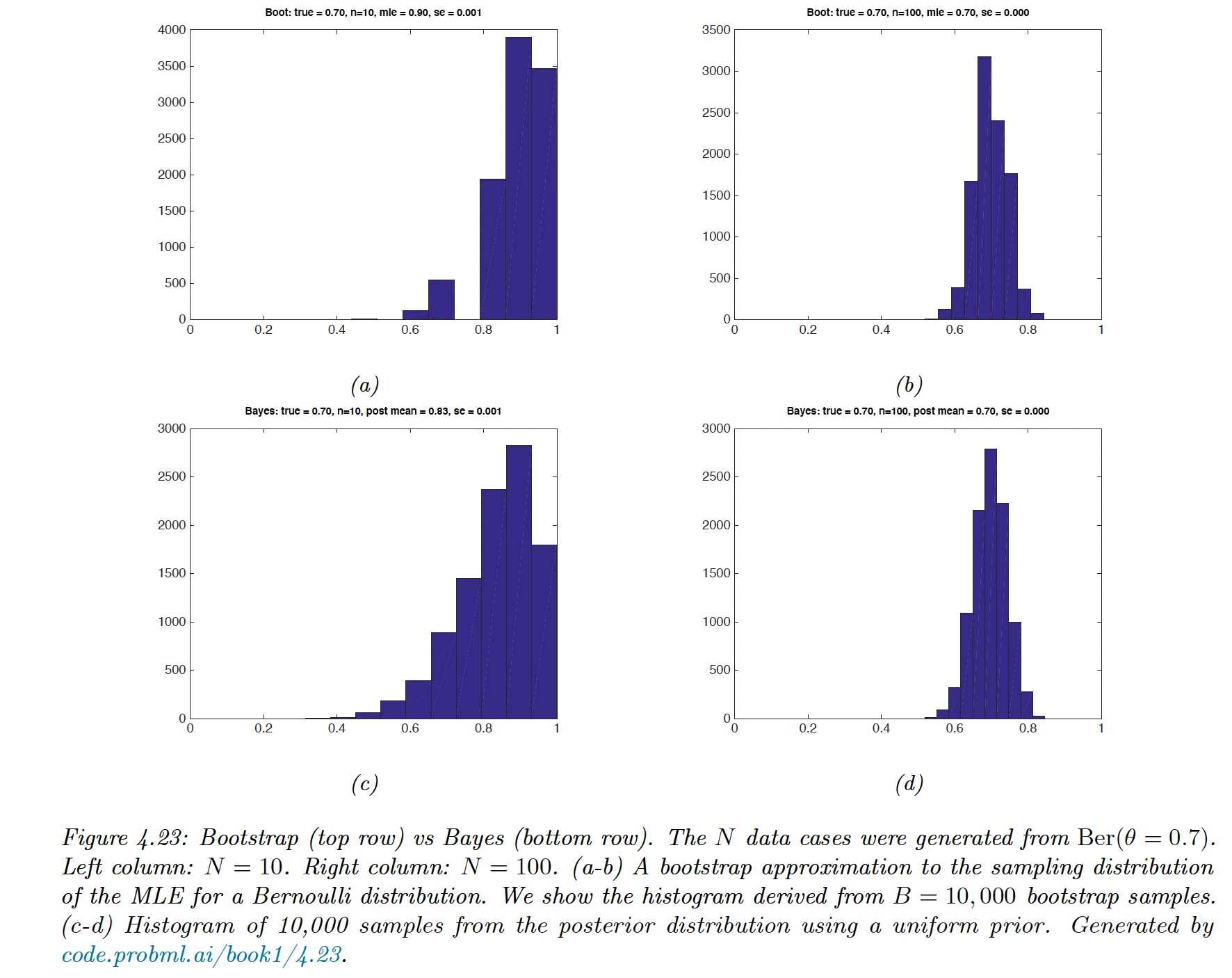
4.7.3 Bootstrap approximation of the sampling distribution of any estimator
When the estimator is a complex function of the data (not jus the MLE) or when the sample size is small, we can approximate the sampling distribution using a Monte Carlo technique called the bootstrap.
- The parametric bootstrap
-
Compute
-
Use it as plugin to create datasets of size :
-
Compute our estimator for each sample, . This empirical distribution is our estimate of the sampling distribution
-
- The non-parametric bootstrap
- Sample points from with replacement, this create
- Compute our estimator as for each sample and draw the empirical distribution.
The bootstrap is a “poor man’s” posterior. In the common case where the estimator is a MLE and the prior is uniform, they are similar.
4.7.4 Confidence intervals
We use the variability induced by the sampling distribution to estimate the uncertainty of an a parameter estimate. We define a -confidence interval as:
where the hypothetical data is used to derives the interval .
If , this means that if we repeatedly sample data and compute , 95% of such intervals would contains the parameter
Suppose is the unknown true parameter but we know :
By rearranging, we find is a CI.
In most cases, we assume a Gaussian approximation to the sampling distribution:
and thus we can compute and approximate CI using:
where is the quantile of the Gaussian CDF and is the estimate standard error.
If the Gaussian approximation is not satisfactory, we can bootstrap the empirical distribution as an approximation to .
4.7.5 Confidence intervals are not credible
A frequentist 95% CI is defined as an interval such that .
If I repeat the experiment over and over, then 95% of the time the CI contains the true mean.
It doesn’t mean that the parameter is 95% likely to live in the interval given by the observed data.
That quantity is instead given by the credible interval
These concepts are different: in the frequentist view, is treated as a unknown, fixed constant, and the data as random. In the Bayesian view, the data is fixed (as it is known) and is random.
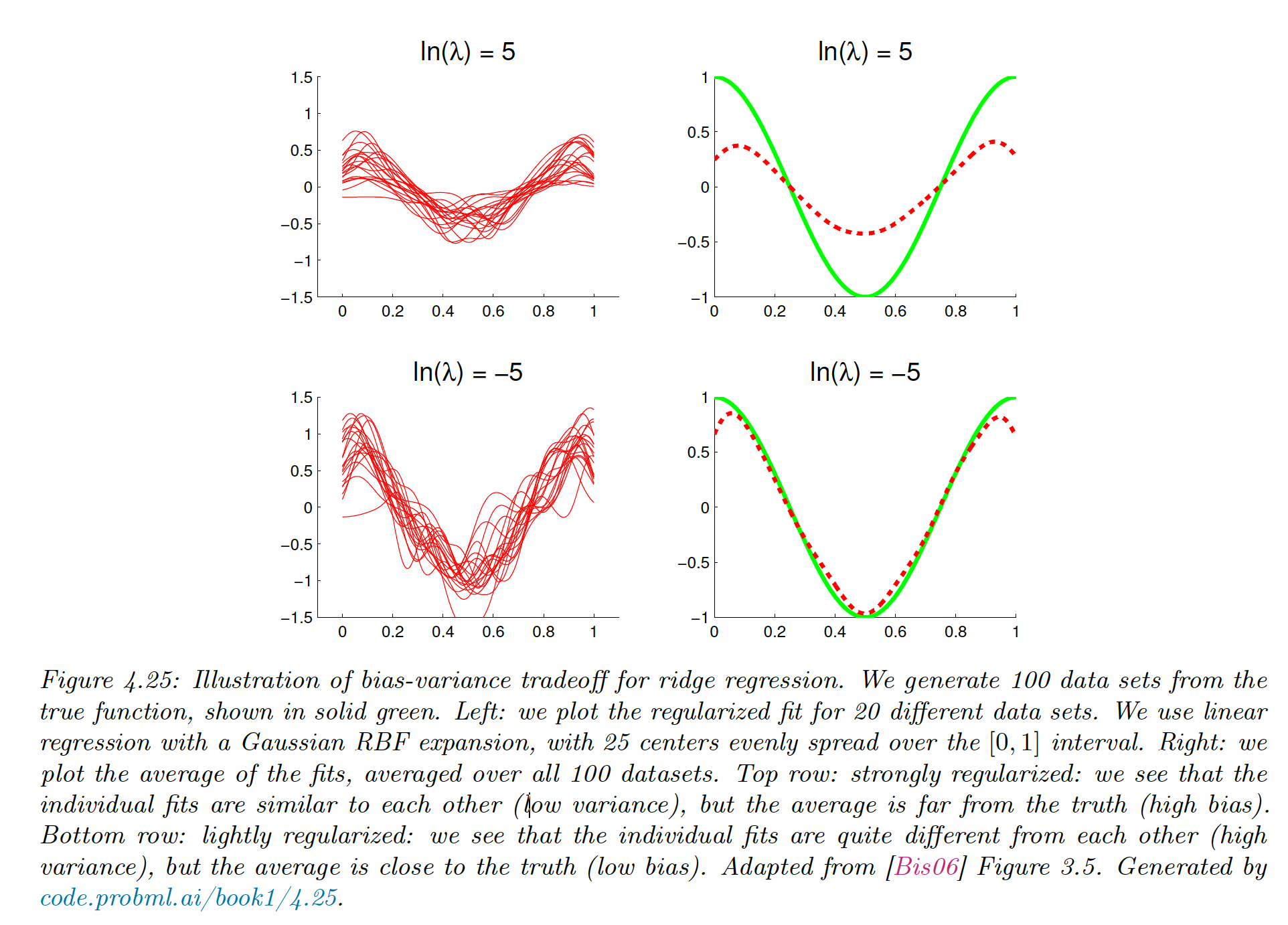
4.7.6 The bias-variance tradeoff
In frequentist, data is a random variable drawn from some true but unknown distribution . So the estimator has a sampling distribution
The bias is defined as:
The MLE of the Gaussian mean is unbiased , but if is not known, the MLE of the Gaussian variance is biased:
Intuitively, this is because we use up one point to get the mean. The unbiased estimator for the Gaussian variance is:
The bias variance tradeoff is given by:
It can be wise to use a biased estimator as long as it reduces the variance by more than the square of the bias.
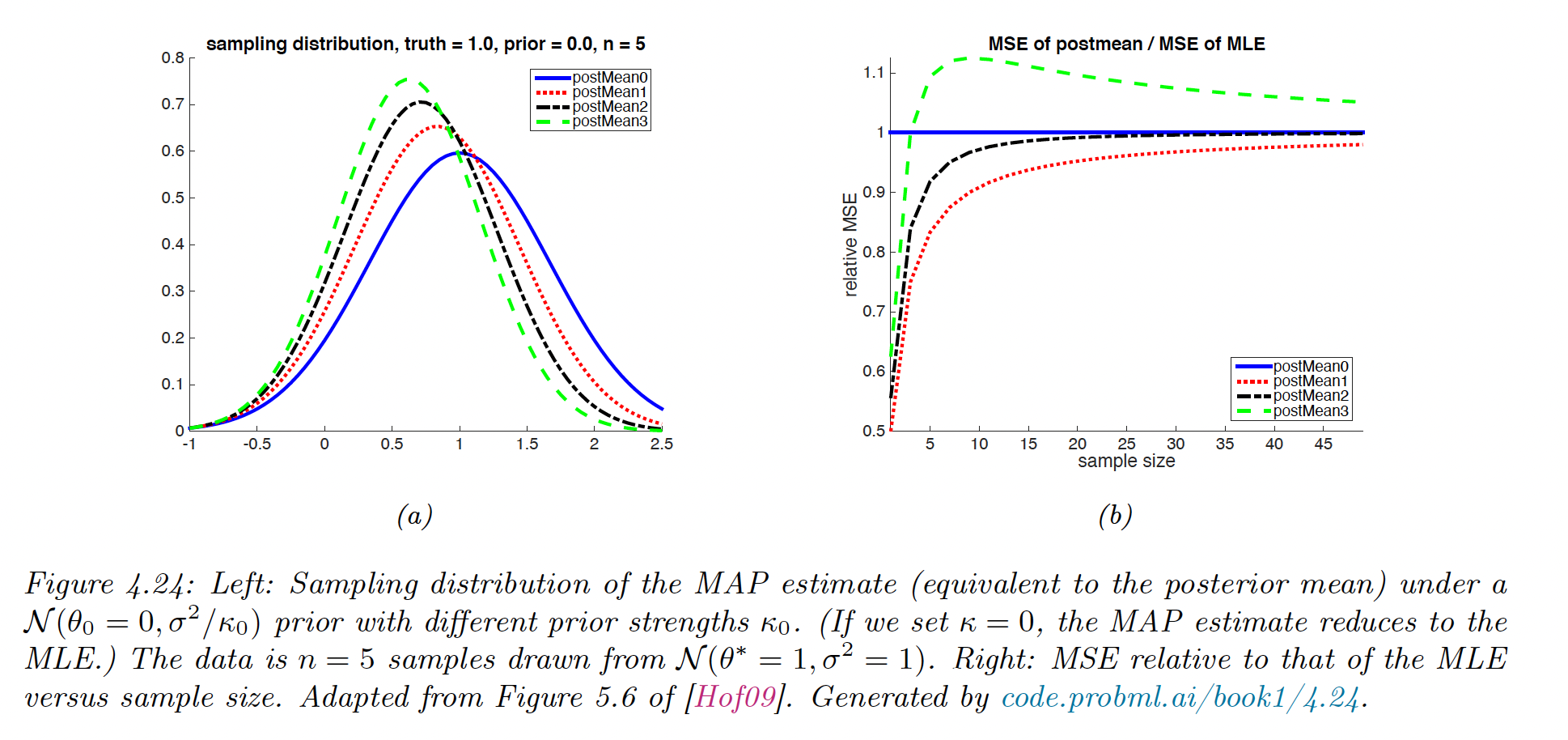
MAP estimator for a Gaussian mean
Suppose we want to estimate the mean of a Gaussian from .
The MLE is unbiased and has a variance of
The MAP under a prior of the form is:
The bias and variance are given by:
MAP estimator for linear regression
MAP estimator for classification
If we use a 0-1 loss instead of the MSE, the frequentist risk is now . If the estimate is on the correct side of the classification, then the bias is negative, and decreasing the variance will decrease the misclassification rate.
However, if the estimate is wrong, the bias is positive and it pays to increase the variance. This illustrates that it is better to focus on the expected loss in classification, not on the bias and variance.