8.4 Stochastic gradient descent
The goal is to minimize the average of the loss function:
where is a training sample. In other words, at each iteration:
where .
The resulting algorithm is the SGD:
As long as the gradient estimate is unbiased, this will converge to a stationary point, providing a decay on .
8.4.1 Finite sum problem
SGD is widely used in ML, because many models are based on empirical risk minimization, which minimizes the following loss:
This is called a finite-sum problem. Computing the gradient requires summing over all examples and can be slow. Fortunately, we can approximate it by sampling a minibatch :
where is a random set of examples. Therefore, SGD is an unbiased estimate of the empirical average of the gradient.
Although the rate of convergence of SGD is slower than in batch GD, the per-step time is lower for SGD. Besides, it is most of the time wasteful to compute the complete gradient, above all at the beginning when the parameters are not well estimated.
8.4.2 Example using the LMS
The objective of the linear regression is:
And its gradient:
And with SGD of batch size the update is:
with the index at each iteration .
LMS and LGD might need multiple passes to the data to find the optimum.
8.4.3 Choosing the step size (learning rate)
An overall small learning rate leads to underfitting, and a large one leads to instability of the model: both fail to converge to the optimum.
Rather than using a single constant, we can use a learning rate schedule. A sufficient condition for SGD to converge is the schedule satisfying the Robbins-Monro condition:
Some common examples of learning rate schedules:
Piecewise constant schedule reduces the learning rate when a threshold is reached, or when the loss has plateaued, this is called reduce-on-plateau.
Exponential decay is typically too fast, and polynomial decay is preferred, here with and .
Another scheduling strategy is to quickly increase the learning rate before reducing it again: we hope to escape a poorly-conditioned loss landscape with small steps, before making progress with larger steps: this is the one-cycle learning rate schedule.
We can also repeat this pattern in a cyclical learning rate schedule to escape local minima.
8.4.4 Iterate averaging
The estimate of the parameter can be unstable with SGD. To reduce the variance, we can compute the average with:
This is called iterate averaging or Polyak-Ruppert averaging. It has been proven that this method yields the best asymptotic convergence for SGD, matching second-order methods.
**Stochastic Weight Averaging (SWA) (opens in a new tab)** exploits the flatness in objective to find solutions that provide better generalization rather than quick convergence. It does so using an equal average with a modified learning rate schedule.
8.4.5 Variance reduction
These methods reduce the variance of the gradients in SGD, rather than the parameters themselves, and can improve the convergence rate from sublinear to linear.
8.4.5.1 Stochastic Variance Reduced Gradient (SVRG)
For each epoch, we take a snapshot of our parameters, , and compute its full-batch gradient . This will act as a baseline, and we also compute the gradient for this snapshot at each minibatch iteration .
The gradient becomes:
This is unbiased since:
Iterations of SVRG are faster than those of full-batch GD, but SVRG can still match the theoretical convergence rate of GD.
8.4.5.2 Stochastic Average Gradient Accelerated
Unlike SVRG, SAGA only needs to compute the full batch gradient once at the start of the algorithm. It “pays” for this speed-up by keeping in memory gradient vectors.
We first initialize and then compute .
Then at iteration , we use the gradient estimate:
we then update and by replacing the old local gradients by the new ones.
If the features (and hence the gradients) are sparse, then the cost of storing the gradients is reasonable.
8.4.5.3 Application to deep learning
Variance reduction techniques are widely used for fitting ML models with convex objectives but are challenging in deep learning. This is because batch normalization, data augmentation, and dropout break the assumptions of SVGR since the loss will differ randomly in ways that do not only depend on parameters and data index.
8.4.6 Preconditioned SGD
We consider the following update:
where is a preconditioned matrix, positive definite. The noise in the gradient estimate makes the estimation of the Hessian difficult, on which second-order methods depend.
Also, solving the update direction with the full preconditioned matrix is expensive, therefore practitioners often use diagonal .
8.4.6.1 Adaptative Gradient (AdaGrad)
AdaGrad was initially designed for convex objectives where many elements of the gradient vector are zero. These correspond to features that are rarely present in the input, like rare words.
The update has the form:
where is the index of the dimension of the parameters, controls the amount of adaptivity and
Equivalently:
where the root and divisions are computed element-wise.
Here we consider
We still have to choose the step size but AdaGrad is less sensitive to it than vanilla GD. We usually fix .
8.4.6.2 RMSProp and AdaDelta
AdaGrad denominator can increase too quickly, leading to vanishing learning rates. An alternative is to use EWMA:
usually with , which approximates the RMS:
Therefore the update becomes:
Adadelta is similar to RMSProp but adds an EWMA to the update of the parameter as well:
with:
If we fix as the adaptative learning rate is not guaranteed to decrease, the solution might not converge.
8.4.6.3 Adaptative Moment Estimation (Adam)
Let’s combine momentum with RMSProp:
this gives the following update:
with , , and
If we initialize , we bias our update towards small gradient values. Instead, we can correct the bias using:
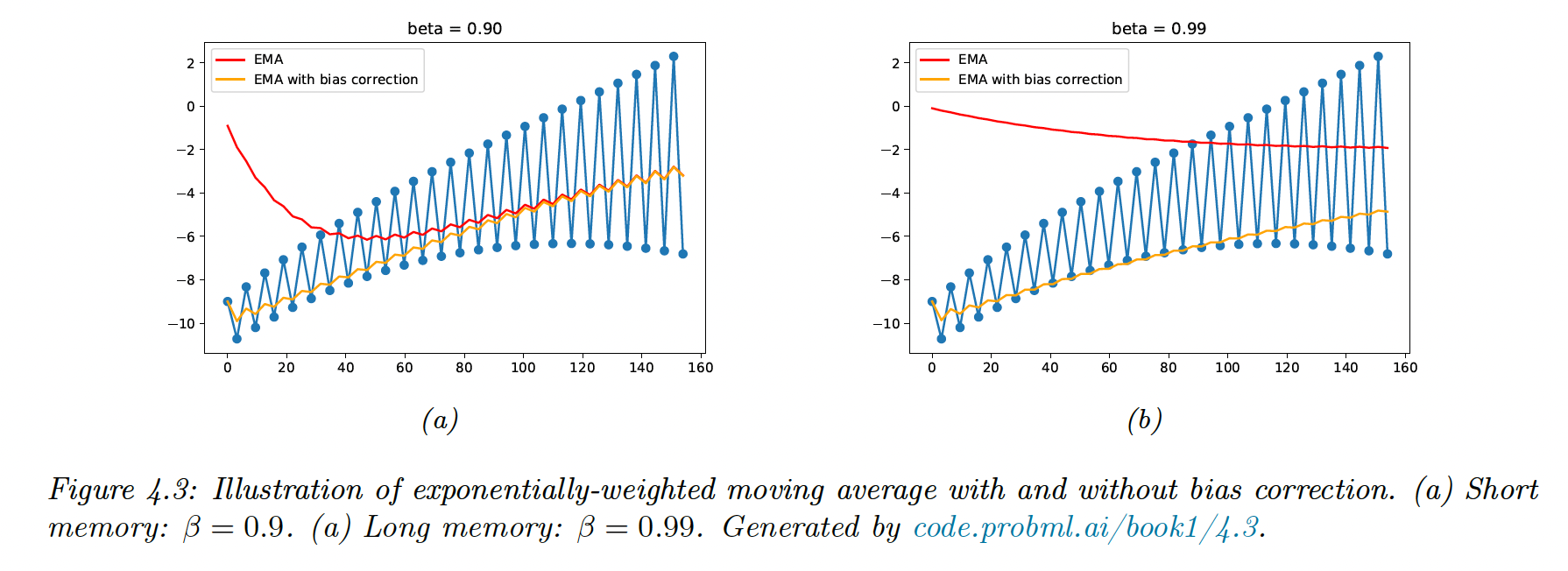
8.4.6.4 Issues with adaptative learning rates
Adaptative learning rates still rely on setting a . Since EWMA is computed using stochastic settings with noisy gradients, the optimization might not converge, even for convex problems, because the effective learning rate increases.
To mitigate this, AMSGrad, Padam, or Yogi (opens in a new tab) have been developed, the latter replacing:
with:
Because ADAM uses EWMA which is by nature multiplicative, its adaptative learning rate decays fairly quickly. In sparse settings, gradients are rarely non-zero so ADAM loses information quickly.
In contrast, YOGI uses an additive adaptative method.
8.4.6.5 Non-diagonal preconditioning matrices
Preceding methods don’t solve the problem of ill-conditioning due to the correlation of the parameters, and hence do not always provide a speed boost over SGD as we might expect.
One way to get faster convergence is to use the full-matrix Adagrad:
where .
Unfortunately, , which is expensive to store and invert.
The Shampoo algorithm (opens in a new tab) makes a block diagonal approximation to M, one per layer of the model, and then uses the Kronecker product structure to invert it.
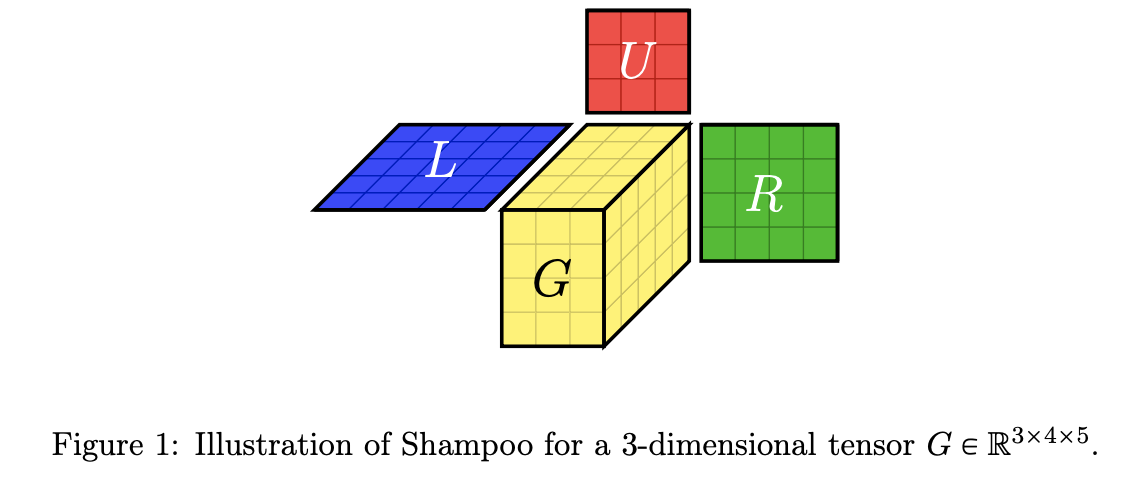


where is the tensor-matrix product. This can be expressed as:
if len(state) == 0:
for dim_id, dim in enumerate(grad.size()):
state[f"precond_{dim_id}"] = epsilon * torch.eye(dim)
for dim_id, dim in enumerate(grad.size()):
precond = state[f"precond_{dim_id}"]
grad = grad.transpose_(0, dim_id)
transposed_size = grad.size()
grad = grad.view(dim, -1)
precond += grad @ grad.T # (dim, dim)
inv_precond = _matrix_power(precond, -1 / order) # uses SVD
grad = inv_precond @ grad # (dim, -1)
grad = grad.view(transposed_size)see full code (opens in a new tab).
However, Shampoo is impracticable in large applications and is difficult to parallelize. Ani+20 (opens in a new tab) introduces the following changes:
- design a pipelined version of the optimization, exploiting the heterogeneity of the CPU-accelerators coupled architecture
- extend Shampoo to train very large layers (such as embeddings layers)
- replace the expensive SVD handling preconditioners with iterative methods to compute the roots of PSD matrices