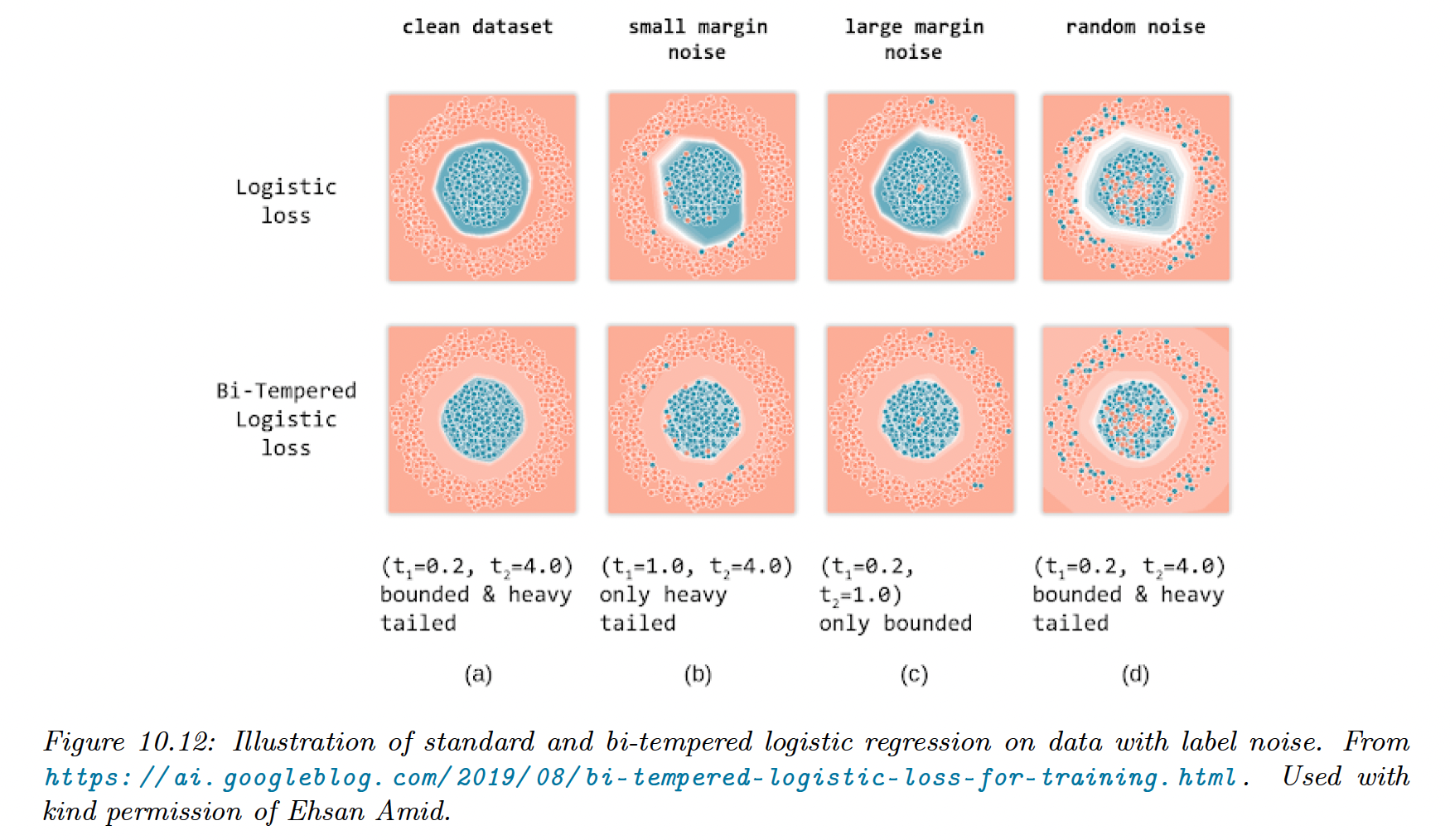
10.4 Robust Logistic Regression
When we have outliers in our data, due to label noise, robust logistic regression help avoid adversarial effects on the model.
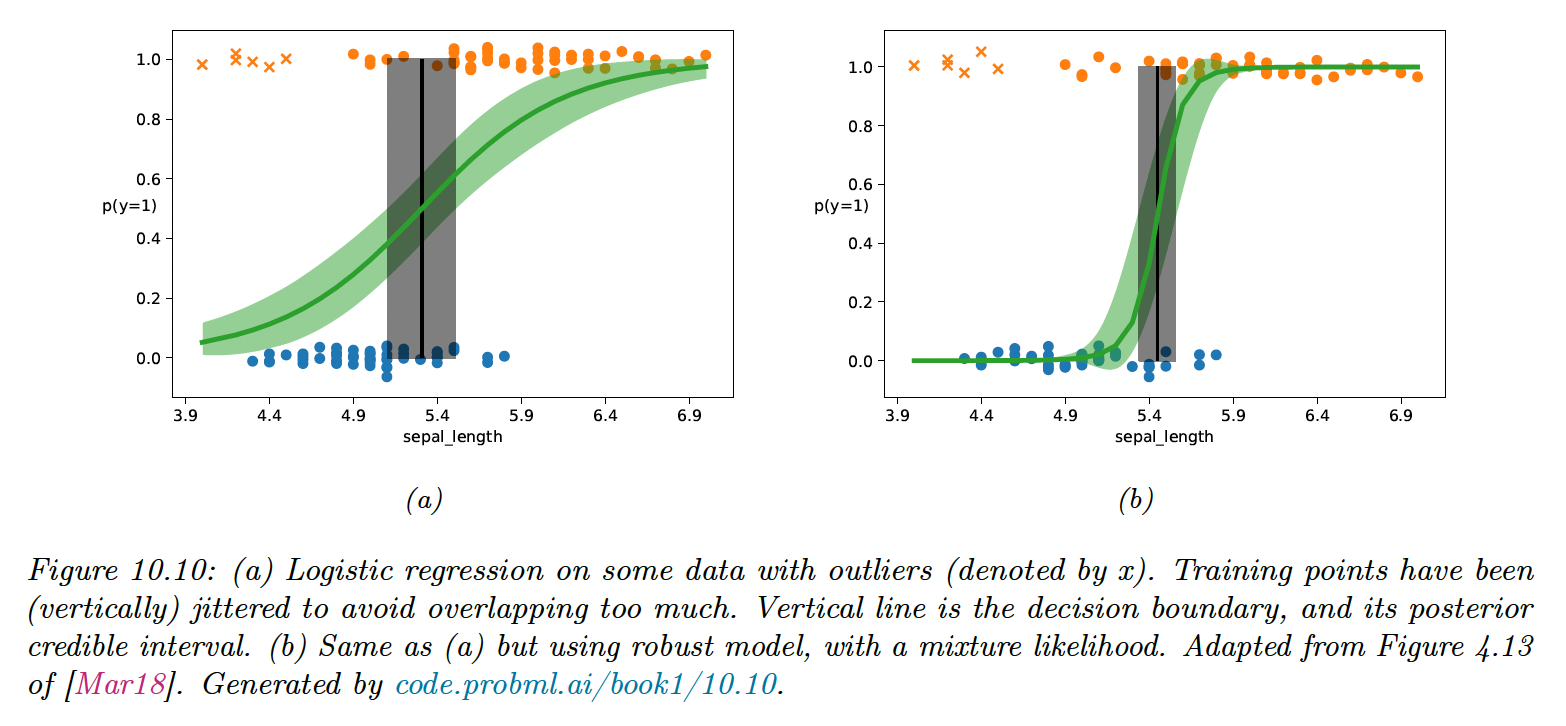
10.4.1 Mixture model for the likelihood
One of the simplest ways to achieve robust logistic regression is to use a mixture likelihood:
This predicts that each label is generated uniformly at random with a probability , and otherwise is generated using the regular conditional model.
This approach can also be applied to DNN and can be fit using standard methods like SGD or Bayesian inference methods like MCMC.
10.4.2 Bi-tempered loss
Examples far from the decision boundary but mislabeled will have undue adverse effects on the model if the loss is convex.
Tempered loss
This can be overcome by replacing the cross entropy loss with a “tempered” version, using a temperature parameter to ensure the loss from outliers is bounded.
The standard cross-entropy loss is:
The tempered cross-entropy is:
when all the mass of is on (one-hot encoding) this simplifies to:
Here is the tempered log:
which is monotonically increasing and concave, and reduces to the standard logarithm when is 1.
This is also bounded below by for , therefore the tempered cross-entropy is bounded above.
Transfer function
Observation near the decision boundary but mislabeled needs to use a transfer function with a heavier tail than the softmax.
The standard softmax is:
The tempered softmax, with is:
where:
when , we find back the standard softmax.
Finally, we need to compute , this needs to satisfy:

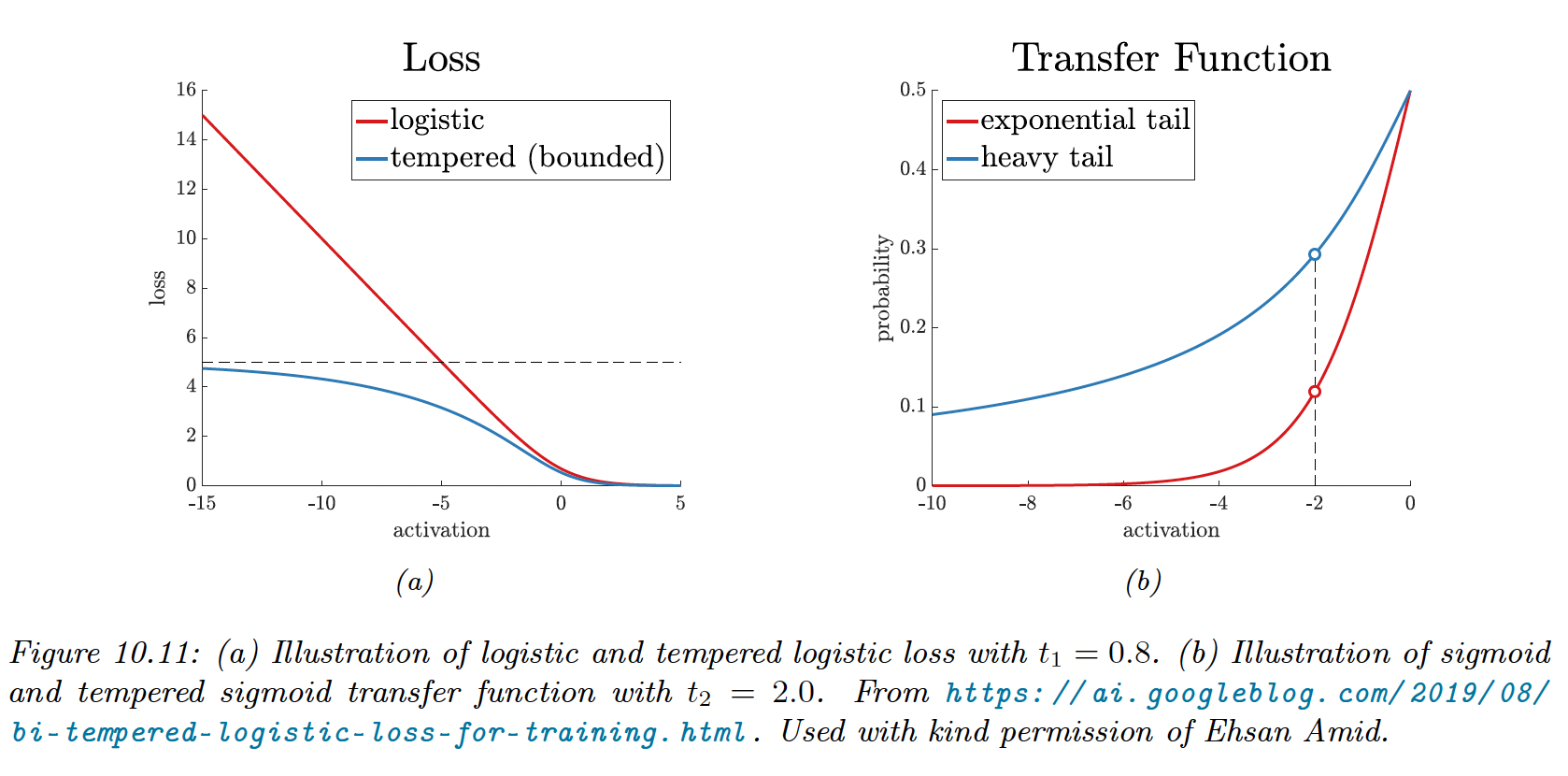
Combining the tempered loss with the tempered transfer function is bi-tempered logistic regression.