16.1 K Nearest Neighbor (KNN) Classification
KNN is one of the simplest kind of classifier: to classify a new input , we find the closest examples in the training dataset, denoted , and look at their labels, to derive a distribution over the outputs for a local region around .
We can return this distribution or the majority label.
The two main parameters are the size of the neighborhood and the distance metric . It is common to use the Mahalanobis distance:
where is a positive definite matrix. When , this reduces to the Euclidean distance.
Despite its simplicity, when the KNN model can becomes within a factor of 2 of the Bayes error (measuring the performance of the best possible classifier).
16.1.1 Example
Below is an example in the case of , where the test point is marked as an “x”.
We can predict .
If we use we can return the label of the nearest point, and the classifier induces a Voronoi tessellation of the points. This is a partition of space which associates a region to each such that all point in are closer to that any other points in .
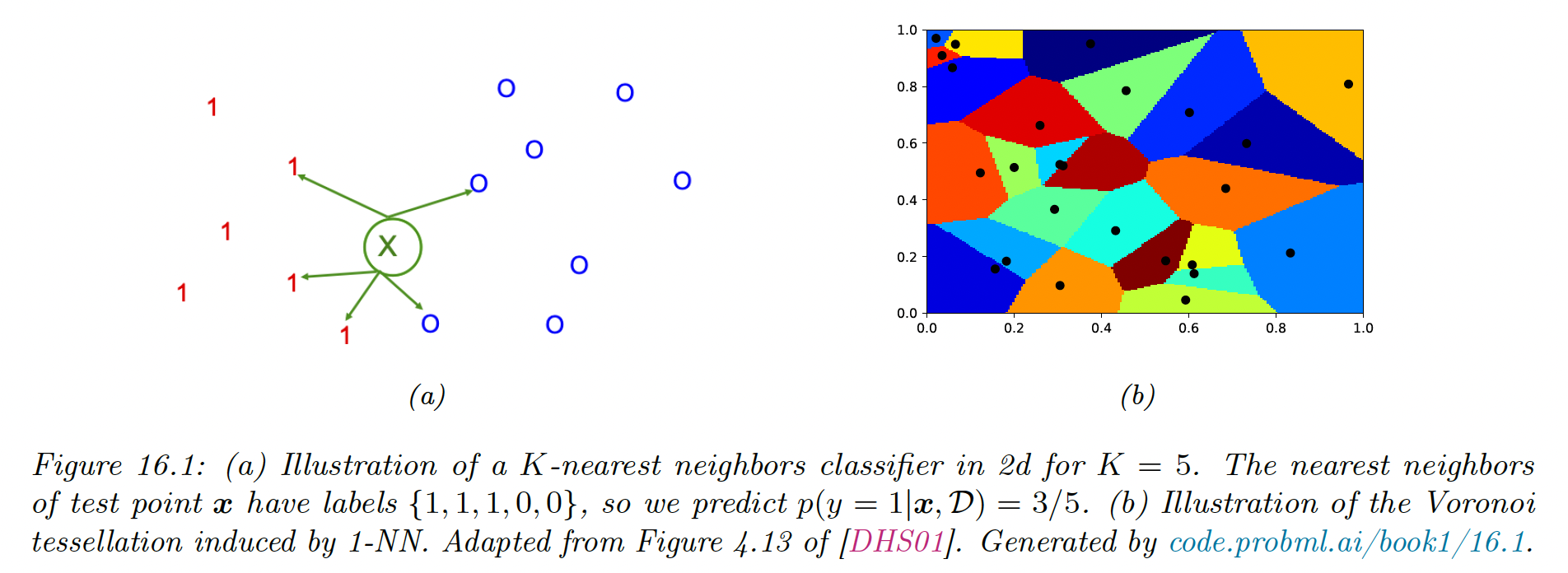
Since the predictive label of each region is the label of , the training error is 0. However, such a model is overfitting the training set.
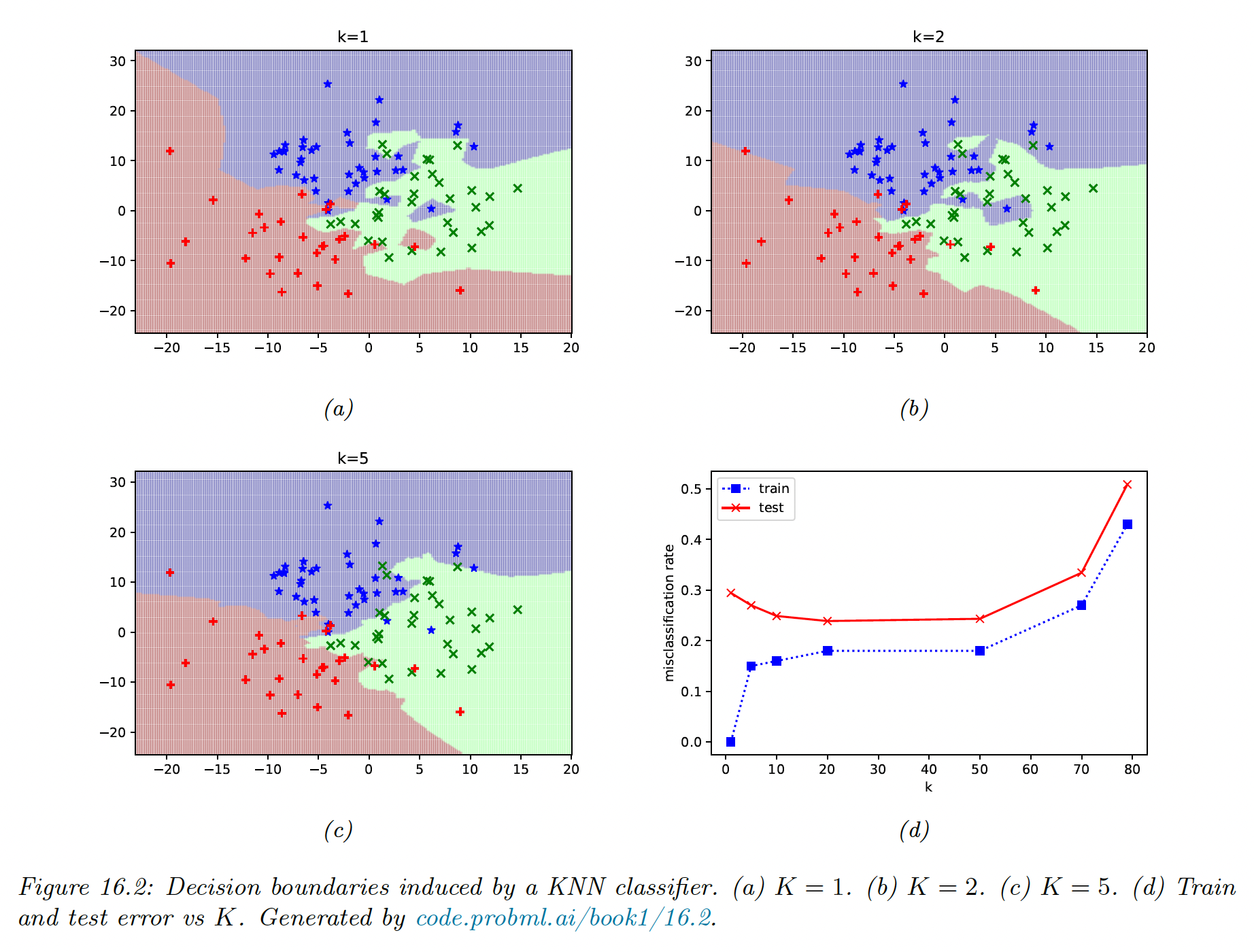
The example below applies a KNN over 3 classes, and we see the decision boundaries becoming smoother as increases. This results in the training error increasing, and the start of underfitting.
The test error shows the characteristic U-shaped curve.
16.1.2 The curse of dimensionality
The main statistical issue with KNN classifiers is that they don’t work well with high-dimensional inputs due to the curse of dimensionality.
The basic problem is that the volume of space grows exponentially fast with dimension, so you might have to look far away in space to find your nearest neighbor.
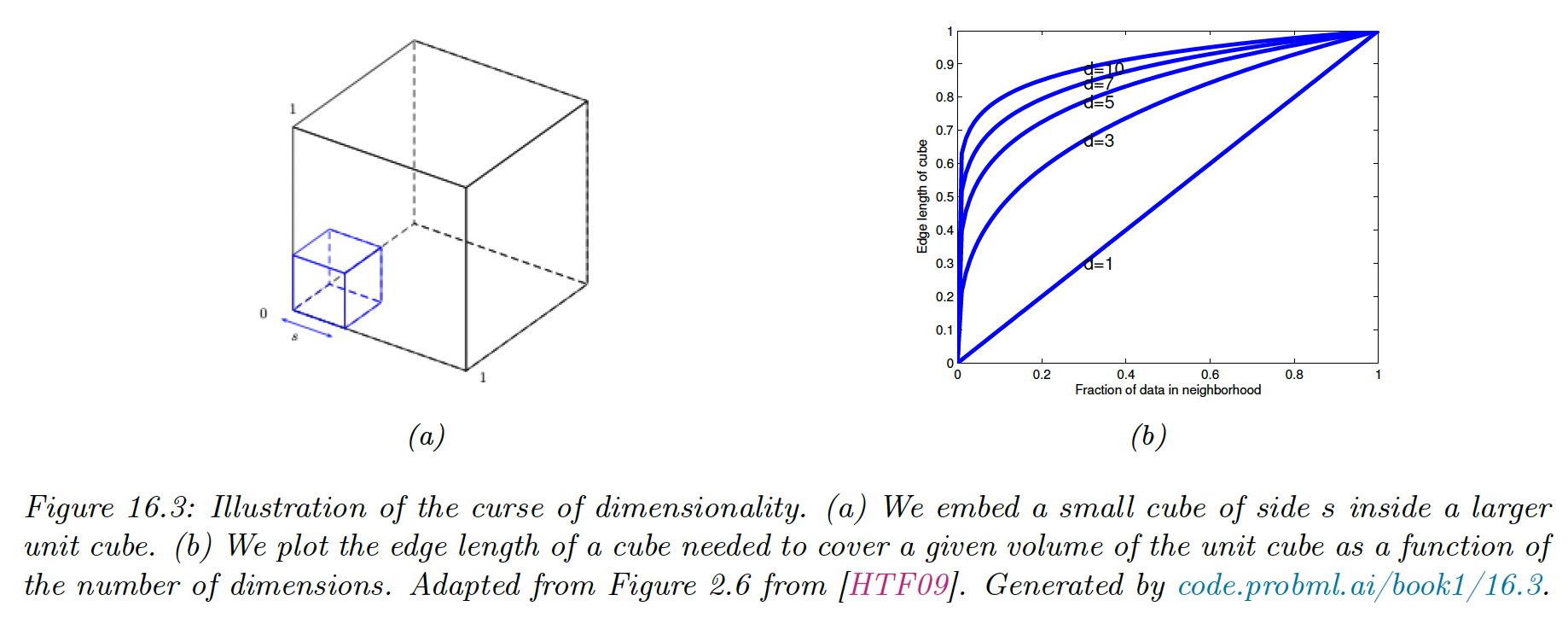
Suppose we apply KNN classifier to data uniformly distributed within a unit cube of dimension . We estimate the class labels density around a point by growing a hypercube around until it contains a fraction of the data points.
The expected length edge of this cube is:
Therefore, if and we want of the data points, we need to extend the cube along each dimension around .
Since the range of the data is 0 to 1, we see this method is not very “local”, so the neighbors might not be good predictors about the behavior of .
There are two main solutions: make some assumption about the form of the function (i.e. use a parametric model) or use a metric that only care about a subset of the dimensions.
16.1.3 Reducing the speed and memory requirements
KNN classifiers store of the training data, which is very wasteful of space. Various pruning techniques have been proposed to remove points that don’t affect decision boundaries.
In terms of running time, the challenge is to find the nearest neighbors in less than time, where is the size of the training set.
Finding exact nearest neighbors is intractable when so most methods focus on finding good approximates.
There are two main classes of techniques:
- Partitioning methods use some kind of k-d tree which divide space into axis-parallel region, or some kind of clustering methods which use anchor points
- Hashing methods, like local sensitive hashing (LSH) is widely used, although more recent methods (opens in a new tab) learn the hashing method from the data
FAISS (opens in a new tab), an open source library for efficient exact or approximate nearest neighbors search (and K-means clustering) of dense vector is available at https://github.com/facebookresearch/faiss (opens in a new tab)
16.1.4 Open set recognition
In all of the classification tasks so far we assumed the number of classes was fixed (this is called closed world assumption).
However, many real-world problem involve test samples that come from new categories. This is called open set recognition.
16.1.4.1 Online learning, OOD recognition and open set recognition
Suppose we train a face recognition system to predict the identity of a person from a fixed set of images.
Let be the labeled dataset at time , with the set of images and the set of people known to the system.
At test time, the system may encounter a new person, let the new image and the new label. The system need to recognize this is a new category, and not accidentally classify it with a label from .
This is called novelty detection, where in this case the image is being generated from with . This can be challenging if the new image appears close to an existing image in .
If the system successfully detects that is novel, then it may ask for the identity of this new person, and add both image and label to the dataset . This is called incremental or online learning.
If the system encounters a photo sampled from an entirely different distribution (e.g. a dog) this is called out of distribution (OOD) detection.
In this online setting, we often get a few (sometimes just one) example of each class. Prediction in this setting is called few-shot classification.
KNN classifiers are well suited to this task, by storing all instances of each classes. At time , rather than labeling using some parametric model, we just find the nearest example in the training set, called . We then need to determine if and are similar enough to constitute a match (this is called face verification in our example).
If there is no match, we can declare the image to be novel or OOD.
The key ingredient for all the above problems is the similarity metric between inputs.
16.1.4.2 Other open world problems
The open set recognition is an example of problem requiring the open world assumption.
Entity resolution or entity linking is another example of this range of problem, where we have to determine whether different strings refer to the same entity or not (e.g. “John Smith” and “Jon Smith).
Multi-object tracking is another important application, also belonging to random finite sets problems.