18.5 Boosting
Ensemble of trees, whether fit using bagging or the random forest algorithm, corresponds to a model of the form:
where is the th tree and is the corresponding weight, often set to .
We can generalize this by allowing the functions to be general function approximators, such as neural nets. The result is called additive model.
We can think of this as a linear function with adaptative basis functions. The goal, as usual, is to minimize the empirical loss function.
The original boosting algorithm sequentially fits additive models where each is a binary classifiers that returns .
- We first fit on the original dataset, then we weight the data samples by the errors made by , so misclassified example get more weight.
- Next, we fit on this weighted dataset.
- We keep repeating this process until number of components have been fitted (where is a hyper-parameter that controls the complexity of the overall-model, and can be chosen by monitoring the performance on a validation dataset, via early-stopping).
It can be shown that as long as each has an accuracy above chance level (even slightly above 50%), then the final ensemble of classifiers will have a higher accuracy that any individual .
In other words, we can boost a weak learner into a strong learner.
Note that boosting reduces the bias of strong learner by fitting trees that depends on each other, whereas bagging and RF reduces the variance by fitting independent trees.
In the rest of this section, we focus on boosting model with arbitrary loss function, suitable for regression, multiclass classification or ranking.
18.5.1 Forward stagewise additive modeling
We sequentially optimize the empirical objective for differentiable loss functions. At iteration , we compute:
where is an additive model.
We then set:
Note that we don’t adjust the weight of the previously added models.
This optimization step depends on the loss function that we choose, and (in some cases) on the form of the weak learner .
18.5.2 Quadratic loss and least square boosting
If we use a squared error loss, the th term in the objective at step becomes:
where is the residual at step of the th observation.
We can minimize this objective by simply setting and fitting to the residual errors. This is called least square boosting.
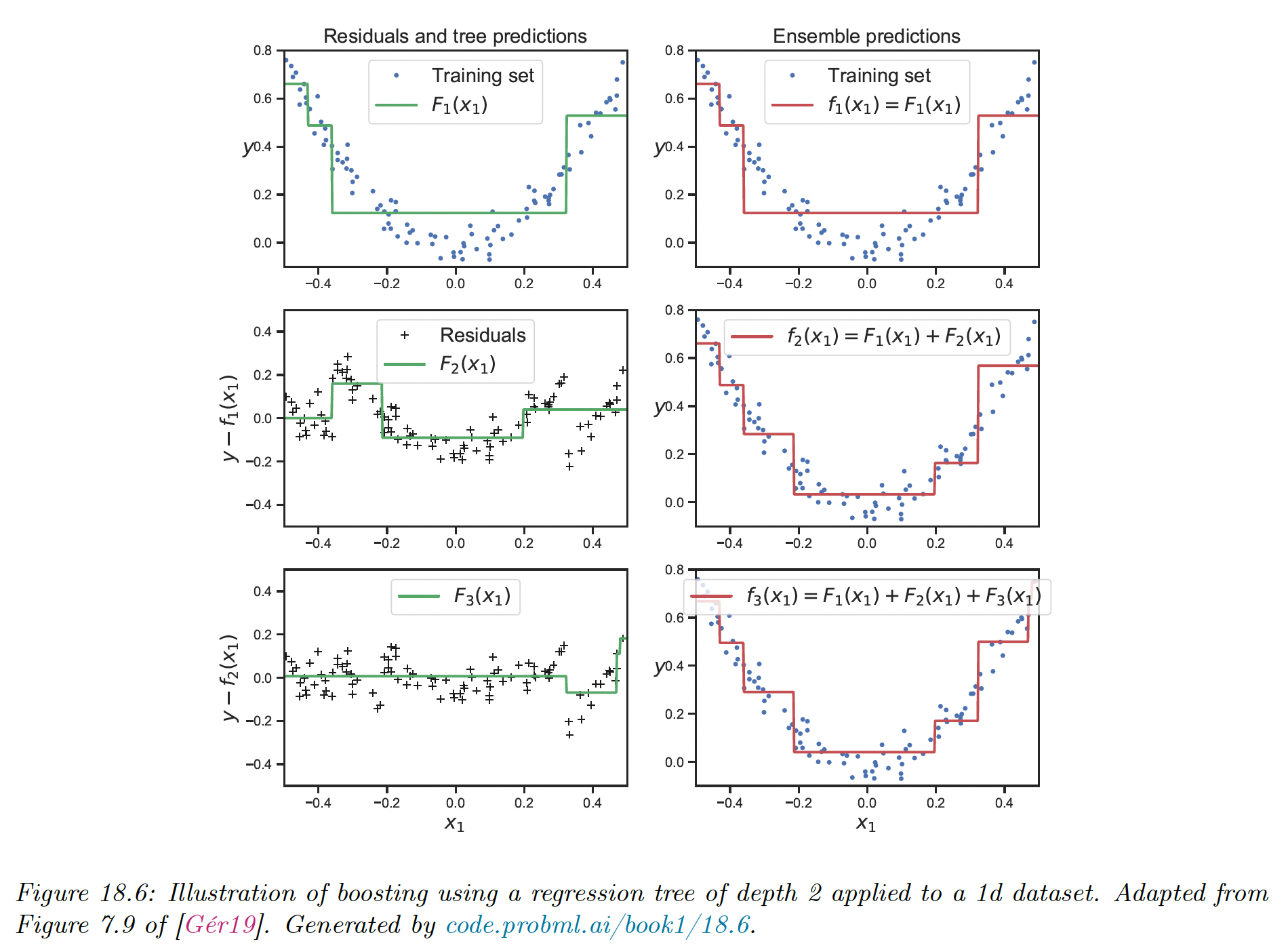
We see how each new weak learner that is added to the ensemble corrects the error made by the earlier version of the model.
18.5.3 Exponential loss and AdaBoost
Suppose we are interested in binary classification, i.e predicting . Let assume the weak learner computes:
The negative log likelihood from section 10.2.3 gives us:
We can minimize this by ensuring the margin is as large as possible.
We see in the figure below that the log loss is an upper bound on the 0-1 loss.
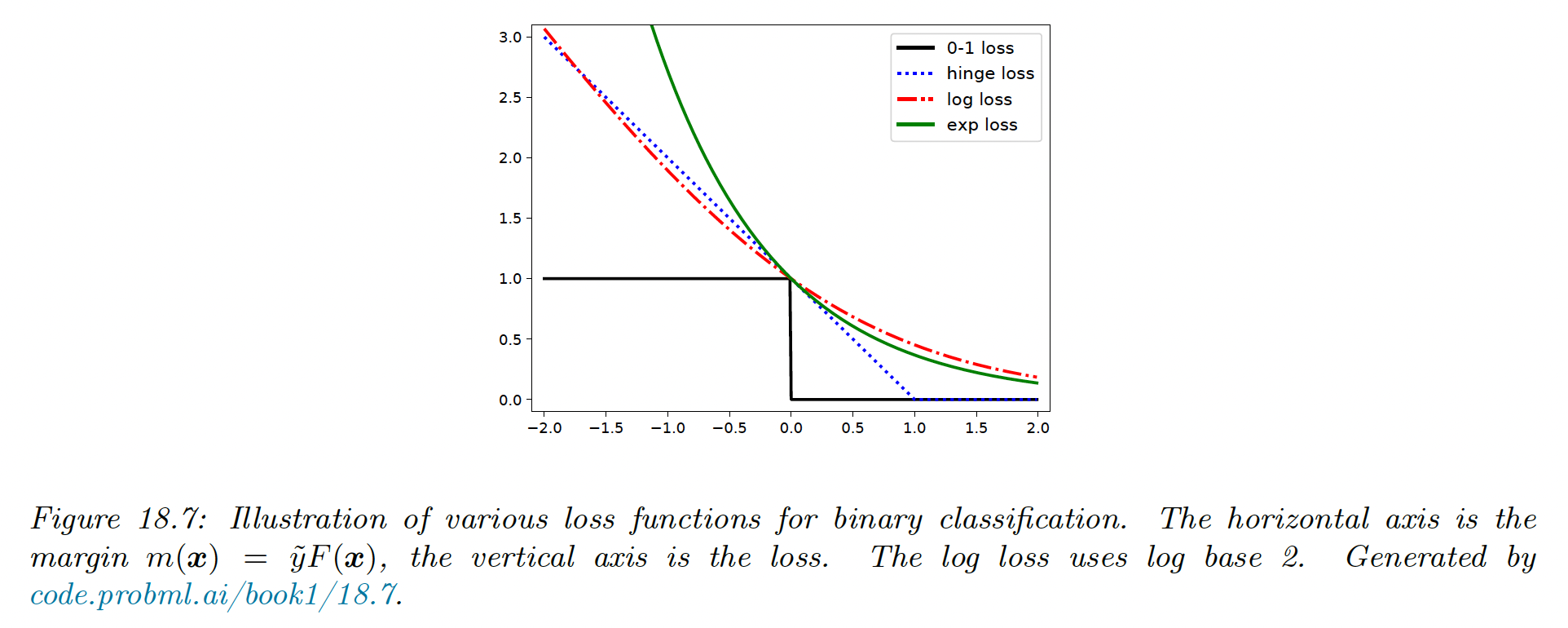
In this section, we consider the exponential loss instead, since it has the same optimal solution as the log loss when the sample size grows to infinity, but it is easier to optimize in the boosting setting.
To see the equivalence with the log loss, we can set the derivative of the expected exponential loss to zero:
We will now discuss how to solve for the th weak learner when we use the exponential loss.
- When returns a binary label, it is called discrete Adaboost
- When returns a probability instead, it is called real Adaboost
At step , we have to minimize:
where
is a weight applied to the th sample.
We can rewrite the objective as follows:
Consequently the optimal function to add is:
This can be found by applying the weak learner to a weighted version of the dataset, with weights .
All that remains is to solve for the size of the update , by substituting into :
where
After updating the strong learner, we recompute the weight for the next iteration:
Since , we finally have:
Since is constant across all examples it can be dropped.
If we then define we have:
We then see that we exponentially increase the weights of misclassified examples. This algorithm is known as Adaboost.

A multiclass generalization of exponential loss, and an adaboost-like algorithm to minimize it is known as SAMME (stagewise additive modeling using a multiclass exponential loss function) — this is the implementation of the Adaboost classifier in scikit-learn.
18.5.4 LogitBoost
The trouble with exponential loss is that it puts a lot of weight on misclassified examples.
In addition, is not the logarithm of any pmf for binary variables , hence we can’t recover probabilities from .
A natural alternative is to use log-loss, which only punishes mistakes linearly, and we’ll be able to extract probability using:
The goal is to minimize the expected log-loss:
By performing Newton update on this update, similarly to IRLS, one can derive the algorithm below, known as logitBoost.
The key subroutine is the ability for the weak learner to solve a weighted least square problem.

18.5.5 Gradient Boosting
Rather than deriving a new boosting algorithm for each loss function, we can derive a generic version known as gradient boosting.
We solve by performing gradient descent in the space of functions. Since functions are infinite dimensional objects, we will represent them by their values on the training set .
At step , let be the gradient of evaluated at :
Gradient of some common loss functions are given by:
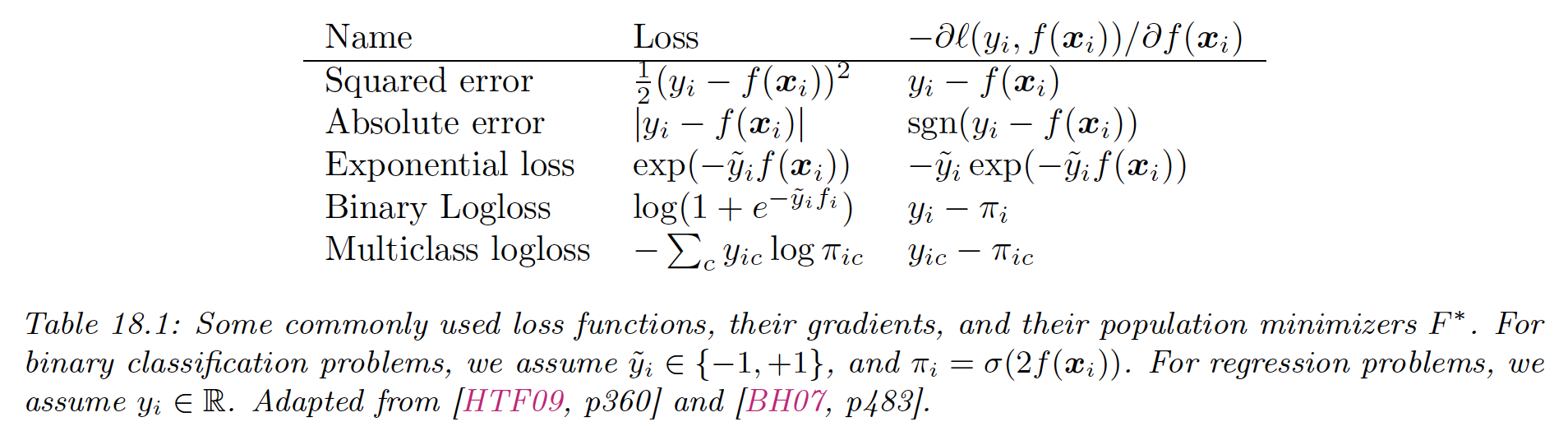
We then make the update:
where is the step length, chosen by:
In its current form, this algorithm is not useful because it only optimize on a fixed set of points, so we don’t learn a function that can generalize.
Instead, we can modify this algorithm by fitting a weak learner to approximate of the negative gradient signal. We use the update:
The overall algorithm is:

We have introduced a learning rate to control the size of the updates, for regularization purposes.
If we apply this algorithm using squared loss, we recover L2Boosting since
For classification, we can use log-loss. In this case, we get an algorithm known as BinomialBoost. Its advantage over LogitBoost is that is doesn’t need to apply weighted fitting, it just applies any black-box regression model to the gradient vector.
To apply this to multiclass classification, we can fit separate regression trees, using the pseudo residual of the form:
Although the trees are fit separately, their predictions are combined using softmax:
When we have large datasets, we can use stochastic variant in which we subsample (without replacement) a random fraction of the data to pass the regression tree at each iteration.
This is called stochastic gradient boosting. Not only is it faster, but it also better generalizes because subsampling the data is a form of regularization.
18.5.5.1 Gradient tree boosting
In practice, gradient boosting nearly always assume the weak learner is a regression tree, which is a model of the form:
where is the predicted output for region (in general can be a vector). This combination is called gradient boosting regression trees. A relative version is known as MART (multivariate additive regression trees).
To use this in gradient boosting, we first find good regions for tree using standard regresion tree learning on the residuals.
Then, we (re)solve for the weight of each leaf by solving:
For squared error, the optimal weight is just the mean of the residuals in that leaf.
18.5.5.2 XGBoost
XGBoost, which stands for extreme gradient boosting, is a very efficient and widely used implementation of gradient boosted trees, and add a few more improvements:
- It adds a regularizer to the tree complexity
- It uses a second-order approximation of the loss instead of a linear approximation
- It samples features at internal nodes (as in random forests)
- It ensures scalability on large datasets by using out-of-core methods
Other popular implementations are LightGBM and CatBoost.
XGBoost optimizes the following objective:
where:
is the regularizer, is the number of leaves and and are regularization coefficients.
At the th step, the loss is given by:
We compute a second order Taylor expansion as follows:
where is the hessian:
In the case of regression trees, we have , where specifies which node the input belongs to, and are the leaf weights.
We can rewrite the loss by removing elements that are independent of :
with is the set of indices of points assigned to leaf .
This is quadratic in each , so the optimal weights are given by:
The loss for evaluating different tree structures then becomes:
We can greedily optimize this using a recursive node splitting procedure. For a given leaf , we consider splitting it into a left and right partition .
We can compute the gain (i.e. the reduction in loss) of this split:
where and
Thus, we see that it is not worth splitting if the gain is negative (the first term is below