8.6 Proximal gradient method
We are often interested in optimizing an objective of the form:
where:
- is a differentiable (smooth) loss, like the NLL
- is a convex loss but may not be differentiable, like the norm or an indicator function that is infinite when constraints are violated.
One way to solve this is to use a Proximal gradient method: take a step size in the gradient direction and then project the result in the constraints space respecting :
where:
We can rewrite the proximal operator as a constraint optimization problem:
Thus the proximal function minimizes the rough loss while staying close to the current iterate .
8.6.1 Projected gradient descent
We want to optimize:
where is a convex set.
We can have box constraints, with
In unconstrained settings, this becomes:
with:
We can solve that with the proximal gradient operator:
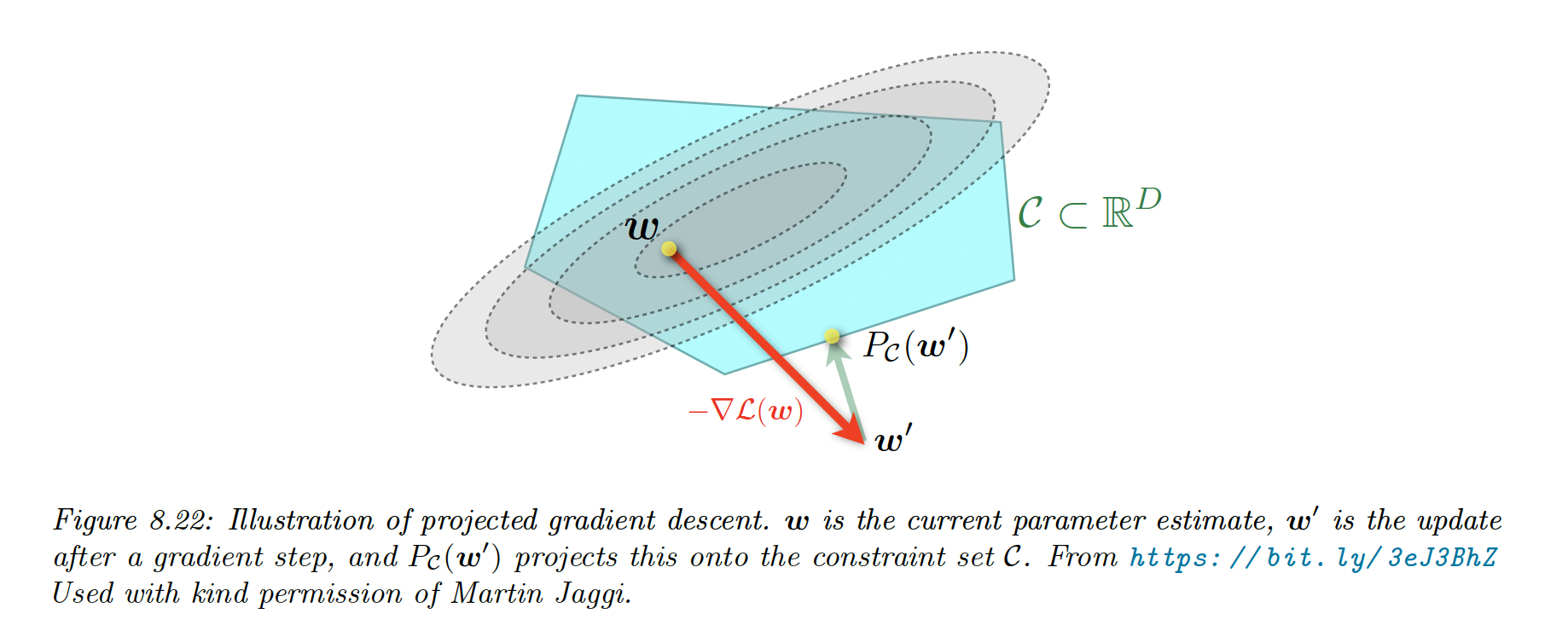
In the box constraints example, the projection operator can be computed element-wise:
8.6.2 Proximal operator for the L1-norm regularizer
A linear predictor has the form .
We can foster model interpretability and limit overfitting by using feature selection, by encouraging weight to be zero by penalizing the norm:
This induces sparsity because if we consider 2 points: and , we have but .
Therefore the sparse solution is cheaper when using the norm.
If we combine our smooth loss with the regularizer we get:
We can optimize this with the proximal operator, in a element-wise fashion:
In section 11.4.3, we show that the solution is given by the soft threshold operator:
8.6.3 Proximal operator for quantization
In some applications like edge computing, we might want to ensure the parameters are quantized.
We define a regularizer measuring the distance between the parameter and its nearest quantized version:
In the case , this becomes:
We solve this with proximal gradient descent, in which we treat quantization as a regularizer: this is called ProxQuant.
The update becomes:
8.6.4 Incremental (online) proximal methods
Many ML problems have an objective function that is the sum of losses, one per example: these problems can be solved incrementally, with online learning.
It is possible to extend proximal methods to these settings, the Kalman Filter is one example.