5.2 Choosing the right model
We can use Bayesian decision theory to choose the best model among candidates.
5.2.1 Bayesian hypothesis testing
We have two hypothesis: the null and the alternative and we want to know which one is more likely to be true: this is hypothesis testing.
If we use zero-one loss, the optimal decision is to pick when . With uniform prior, and hence we pick when the Bayes factor is:
This is close to a likelihood ratio except we integrate out the parameters, so that we can compare models of different complexity, due to the Bayesian Occam’s razor effect.
The Bayes factor is the frequentist equivalent to p-values.
Exemple: testing the fairness of a coin
The marginal likelihood under is simply:
And the marginal likelihood under by taking a Beta prior is:
We prefer over when observing 2 or 3 heads. The figure below list all the possible draw () for 5 tosses.
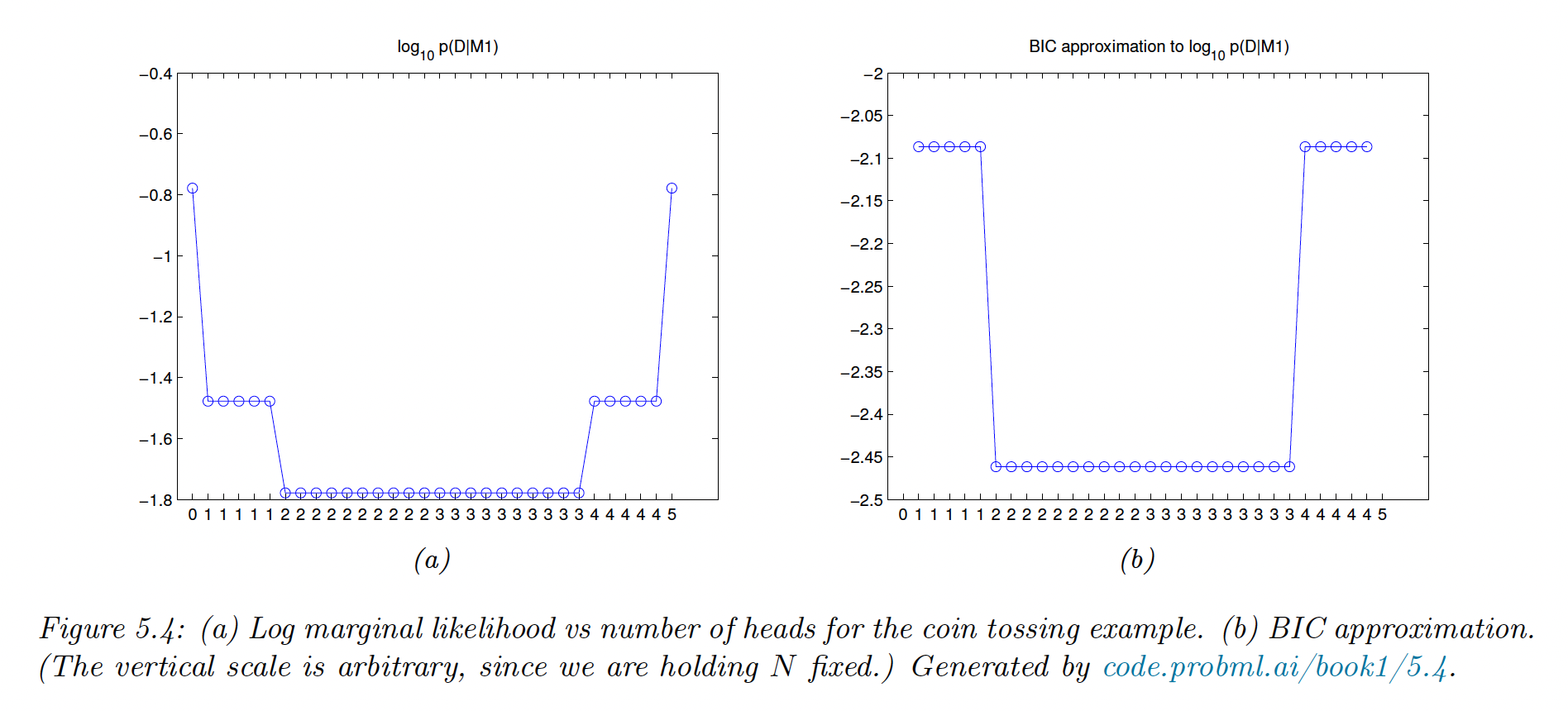
5.2.2 Model selection
We now have more than 2 models and need to pick the most likely. We can view model selection as decision theory problem, where the action space requires choosing a model .
If we have a 0-1 loss, the optimal action is to pick the higher posterior over models:
With a uniform prior, , then the MAP is given by:
with the marginal likelihood:
If all settings of assign a high probability to the data, is probably a good model.
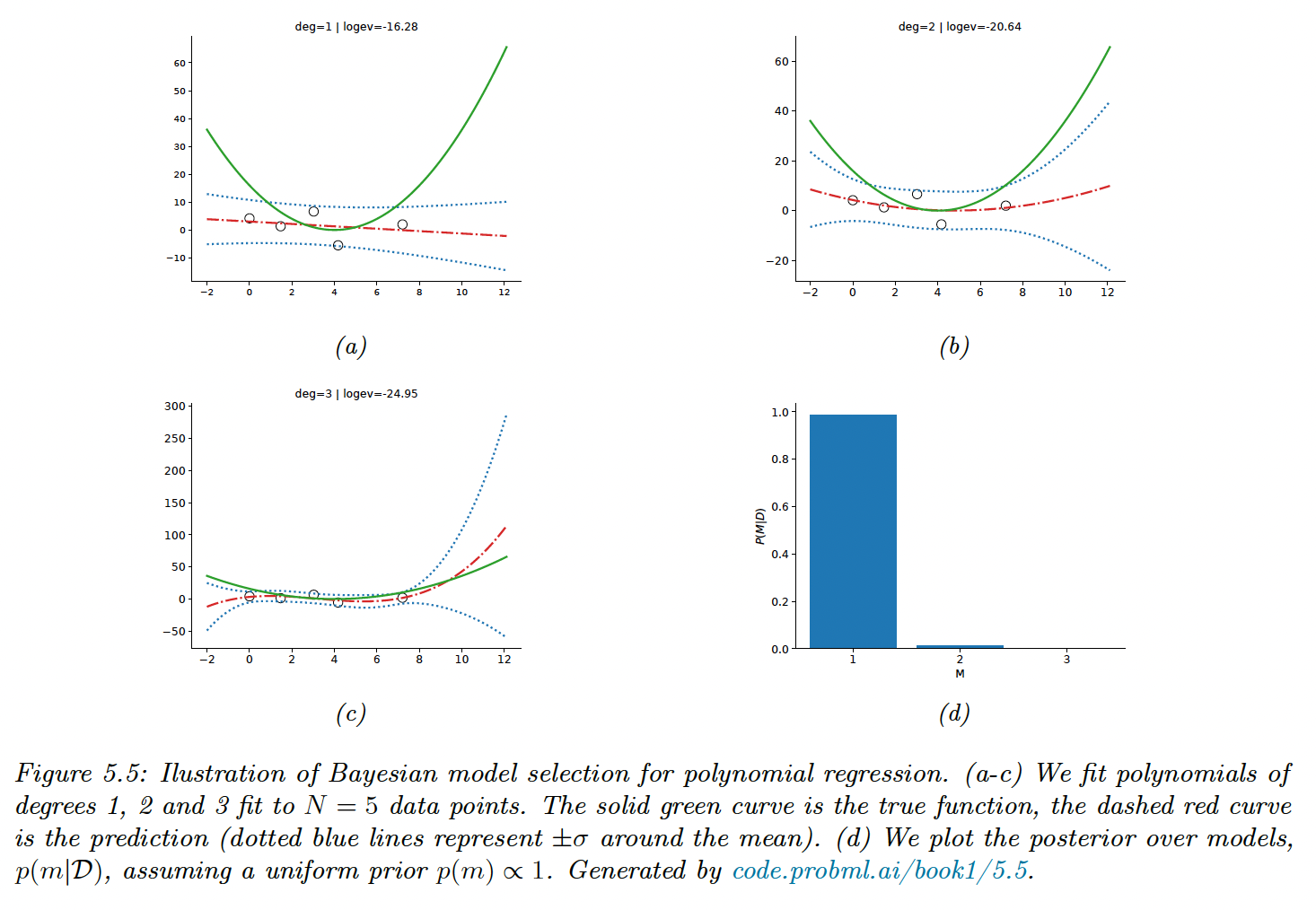
We use a uniform prior over models and use empirical Bayes to estimate the prior over the regression weights. We then compute the evidence for each model. With , there is not enough data to choose a more complex model than degree of 1.
5.2.3 Occam’s razor
Consider two models: a simpler one and a more complex one . If both can explain the data equally well, ie , then we should choose the simpler one.
This is because the complex model will put less prior probability on the “good parameters” that explain the data, since the prior must integrate to 1 over the feature space.
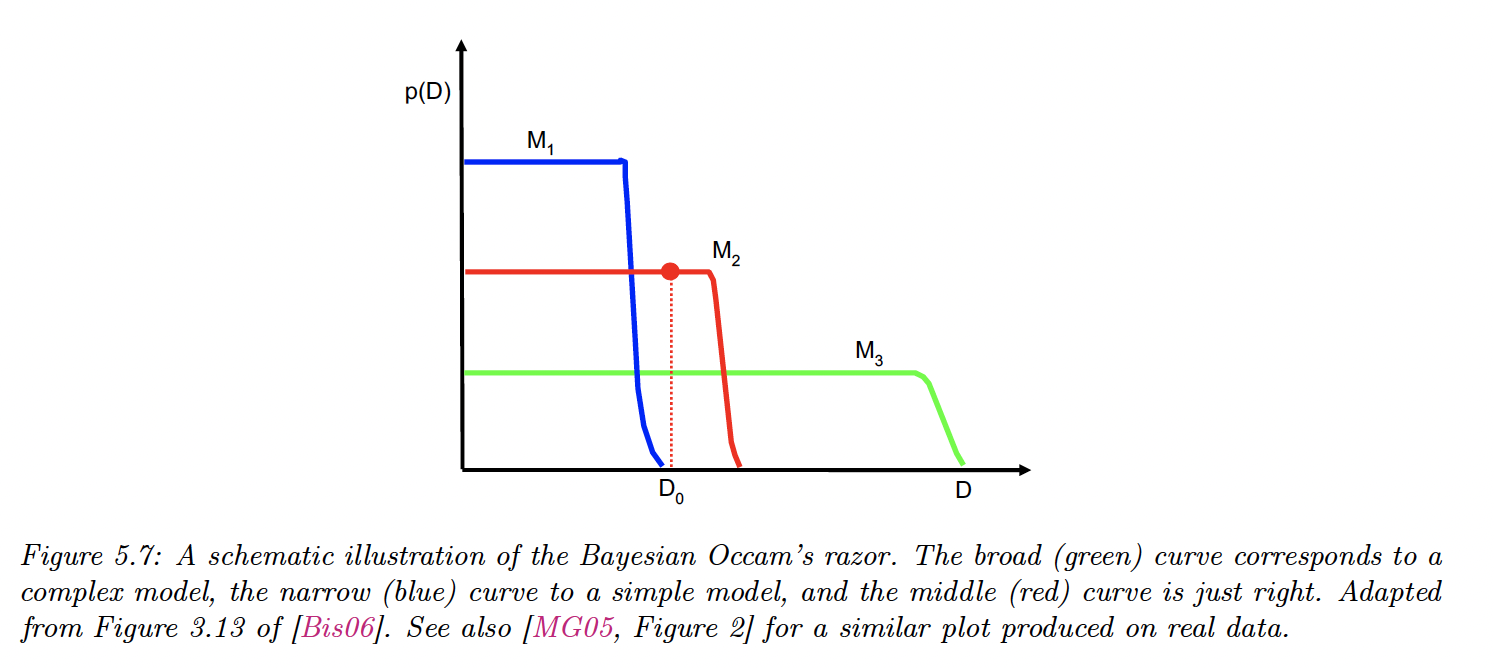
The figure present the predictions (marginal likelihood) of 3 models on increasingly more “complex“ datasets ( is the observed dataset, on which is optimal).
5.2.4 Connection between cross validation and marginal likelihood
Marginal likelihood helps us choose models of the right complexity. In non-Bayesian approaches, it is standard to select model via cross validation.
The marginal likelihood can be written:
and by using the plugin approximation:
Finally:
This is similar to the leave-one-out cross validation (LOO-CV) which has the form:
except the marginal likelihood ignores the part.
Overly complex models will overfit the early data examples and will predict the remaining poorly, leading to a low CV score.
5.2.5 Information criteria
The marginal likelihood can be difficult to obtain since it requires integrating over the entire parameter space.
We introduce alternative information criterias
5.2.5.1 Bayesian information criterion (BIC)
BIC can be considered as a simple approximation to the marginal likelihood. If we make a Gaussian approximation to the posterior and use the quadratic approximation from section 4.6.8.2:
where is the hessian of the negative log joint evaluated in . The hessian is called the Occam factor since it measures the model complexity.
So:
Let’s approximate each by a constant :
Where . We can drop the last term, constant in .
With a uniform prior, , we have the BIC score:
Then the BIC loss is
5.2.5.2 Akaike information criterion (AIC)
It has the form:
This penalizes less heavily than BIC since the penalty doesn’t depend on
5.2.6 Posterior inference over effect sizes and Bayesian significance testing
Bayesian hypothesis testing leverages the Bayes factor but computing the marginal likelihood is computationally difficult and the results can be sensitive to the choice of the prior.
We are often more interested in the effect size, e.g. when comparing the means of 2 models . The probability that the mean of is higher than mean of can be computed as or , with the minimum magnitude effect (one-sided or two-sided t-test).
More generally, represents the region of practical equivalence (ROPE). We can define 3 events of interest:
- The null hypothesis , when (which is more realistic than )
- : , is better than
- : , the opposite
To choose among these hypothesis, we have to estimate , which avoids computing the Bayes factor.
Bayesian t-test for difference in means
Let be the error of method on sample . Since the samples are common across datasets, we use paired test, that better compare methods than average performances.
Let , we assume and our goal is to estimate with .
If we use a non-informative prior, one can show that the posterior marginal for the mean is given by the student distribution:
with the sample mean and an unbiased estimate of the variance .
Therefore we can easily compute with a ROPE of
Bayesian -test for differences in rates
Let be the number of correct sample for method over a total of trial, so the accuracy is .
We assume , and we are interested in with and .
If we use a uniform prior: , our posterior is:
The posterior for is given by:
We can compute it for any :
This can be computed using 1-dimensional numerical integration or analytically.
Note that data is often summarized in a contingency table:
