20.3 Autoencoders
We can think of PCA and factor analysis (FA) as learning a mapping called the encoder and another mapping called the decoder.
The model tries to minimize the following loss function:
where the reconstruction function is .
More generally, we can use:
In this section, we consider the case where encoder and decoder are nonlinear mappings implemented by neural nets. This is called an autoencoder.
If we use an MLP with one hidden layer, we get:
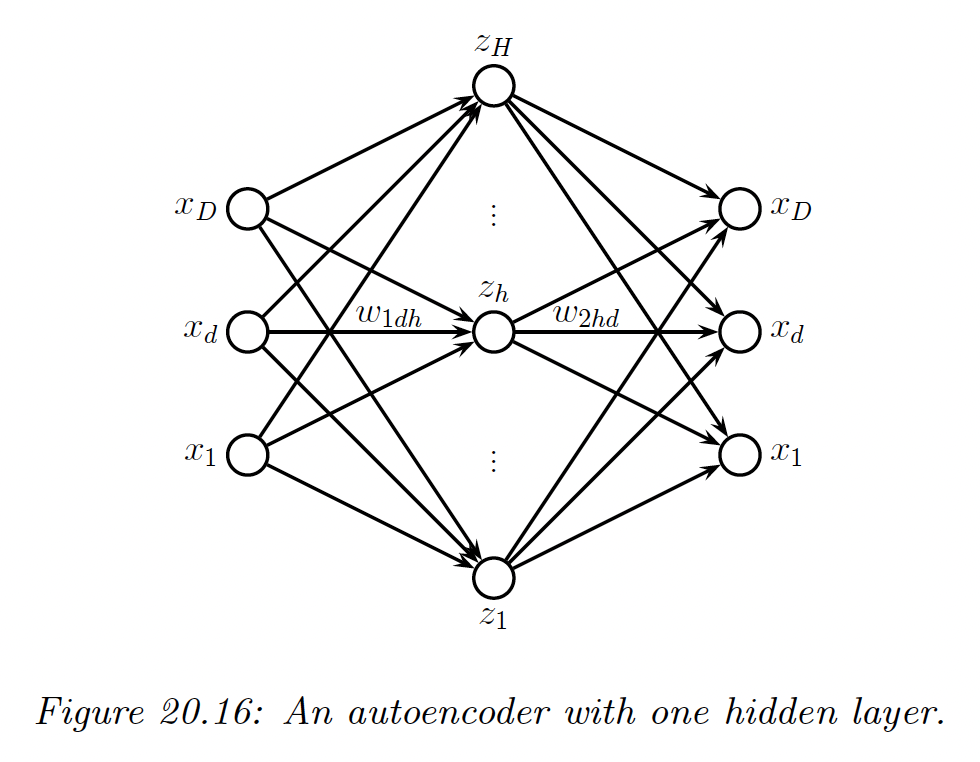
We can think of the hidden units in the middle as a low-dimensional bottleneck between the input and its reconstruction.
If the hidden layer is wide enough, we can’t prevent it from learning the identity function. To avoid this degenerate solution, we can set use a narrow bottleneck layer ; this is called undercomplete representation.
The other approach is to use , known as an overcomplete representation, but to impose some kind of regularization, such as adding noise to the inputs, forcing the activation of the hidden units to be sparse, or imposing a penalty on the derivate of the hidden units.
20.3.1 Bottleneck autoencoders
We start by considering linear autoencoders, in which there is one hidden layer.
The hidden units are computed using:
and the output is reconstructed using
where , and .
Hence the output of the model is:
If we train this model to minimize the squared reconstruction error,
one can show that is an orthonal projection onto the first eigenvectors of the covariance matrix of . This is therefore equivalent to PCA.
If we introduce nonlinearity in the autoencoder, we get a model that is strictly more powerful than PCA.
We consider both an MLP architecture (2 layers and a bottleneck of size 30), and a CNN based architecture (3 layers, and a 3d bottleneck with 64 channels).
We use a Bernoulli likelihood model and binary cross entropy at the loss.

We see that the CNN model reconstructs the images more accurately than the MLP model (although both models are small and only trained on 5 epochs).
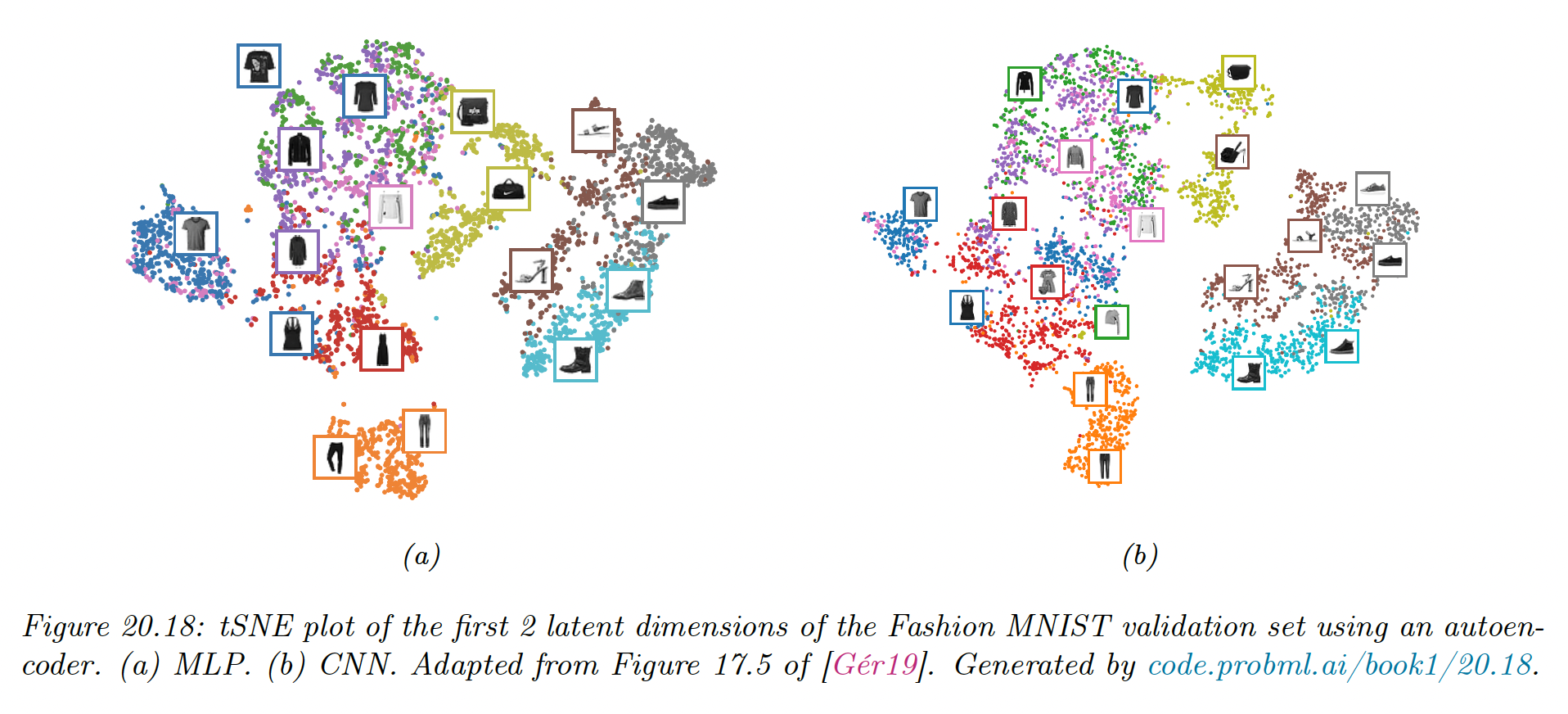
We visualize above the first 2 (of 30) latent dimensions produced by the MLP-AE, by plotting the tSNE embeddings, color coded by class label.
We see that both this method and the CNN have done a good job of separating the classes in a fully unsupervised way. We also see that both latent spaces are similar when viewed through 2d projection.
20.3.2 Denoising autoencoders
One way to control the capacity of an autoencoder is to add noise to the input, and then train the model to reconstruct the uncorrupted version of the input. This is called a denoising autoencoder.
We can implement this by adding Gaussian noise or Bernoulli dropout.

We see that the model is able to hallucinate details that are missing in the input, because it has already see similar images before and can store this information in its parameters.
Suppose we train a DAE using Gaussian corruption and squared error reconstruction, i.e. we use:
and:
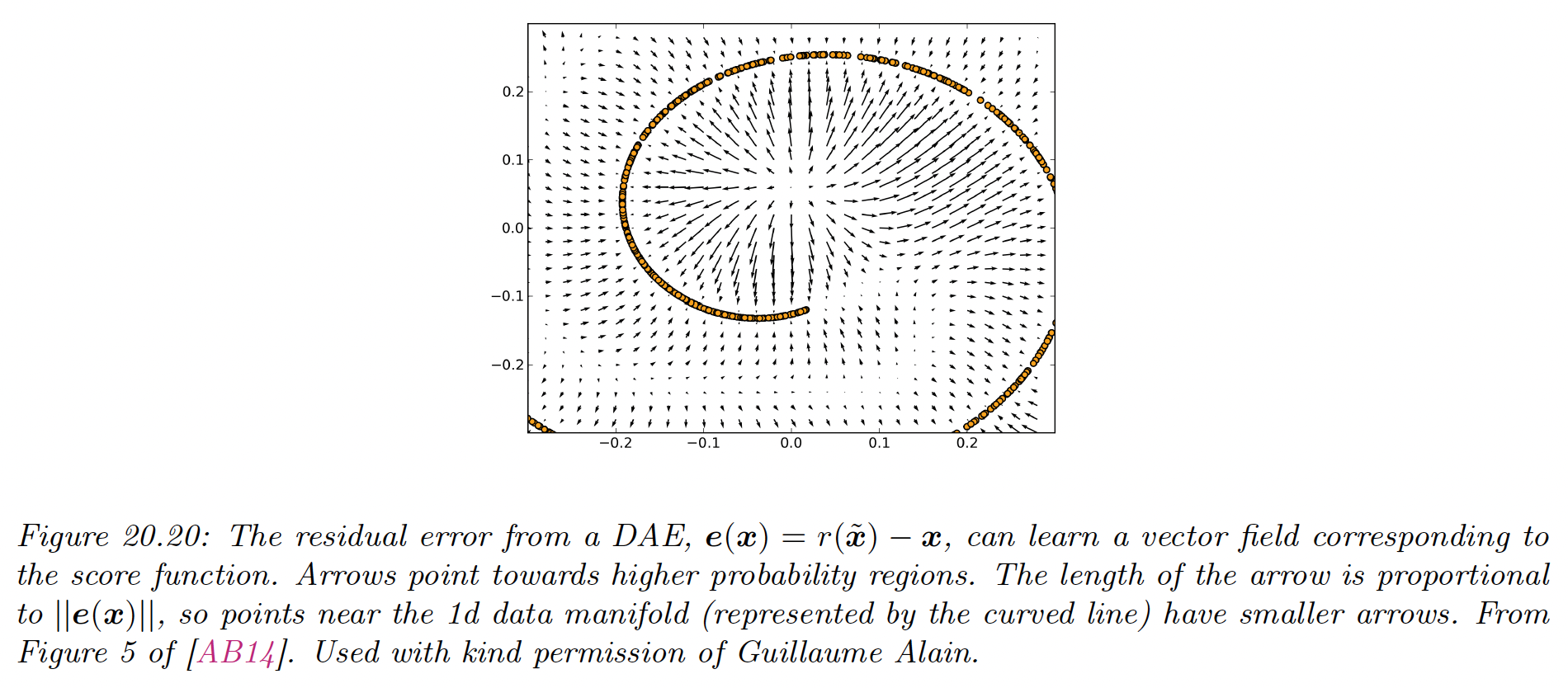
where is the residual error.
Then one can show that as (and with a sufficiently powerful model and enough data), the residuals approximate the score function, which is the log probability of the data:
That is, the DAE learns a vector field, corresponding to the gradient of the log data density. Thus, points that are close to the manifold will be projected onto it via the sampling process.
20.3.3 Contractive autoencoders
A different way to regularize autoencoders is to adding a penalty term to the reconstruction loss:
where is the value of the th hidden embedding unit.
We penalize the Frobenius norm of the encoder’s Jacobian. This is called a contractive AE (CAE). A linear operator with Jacobian is called a contraction if for all unit norm input .
Intuitively, to minimize the penalty, the model would like to ensure the encoder is a constant function. However, if it was completely constant, it would ignore its input and hence incur high reconstruction error.
Thus, the two terms together encourage to model to learn a representation where only a few units change in response to the most significant variation of the input.
Unfortunately, CAEs are slow to train due to the expense of computing the Jacobian.
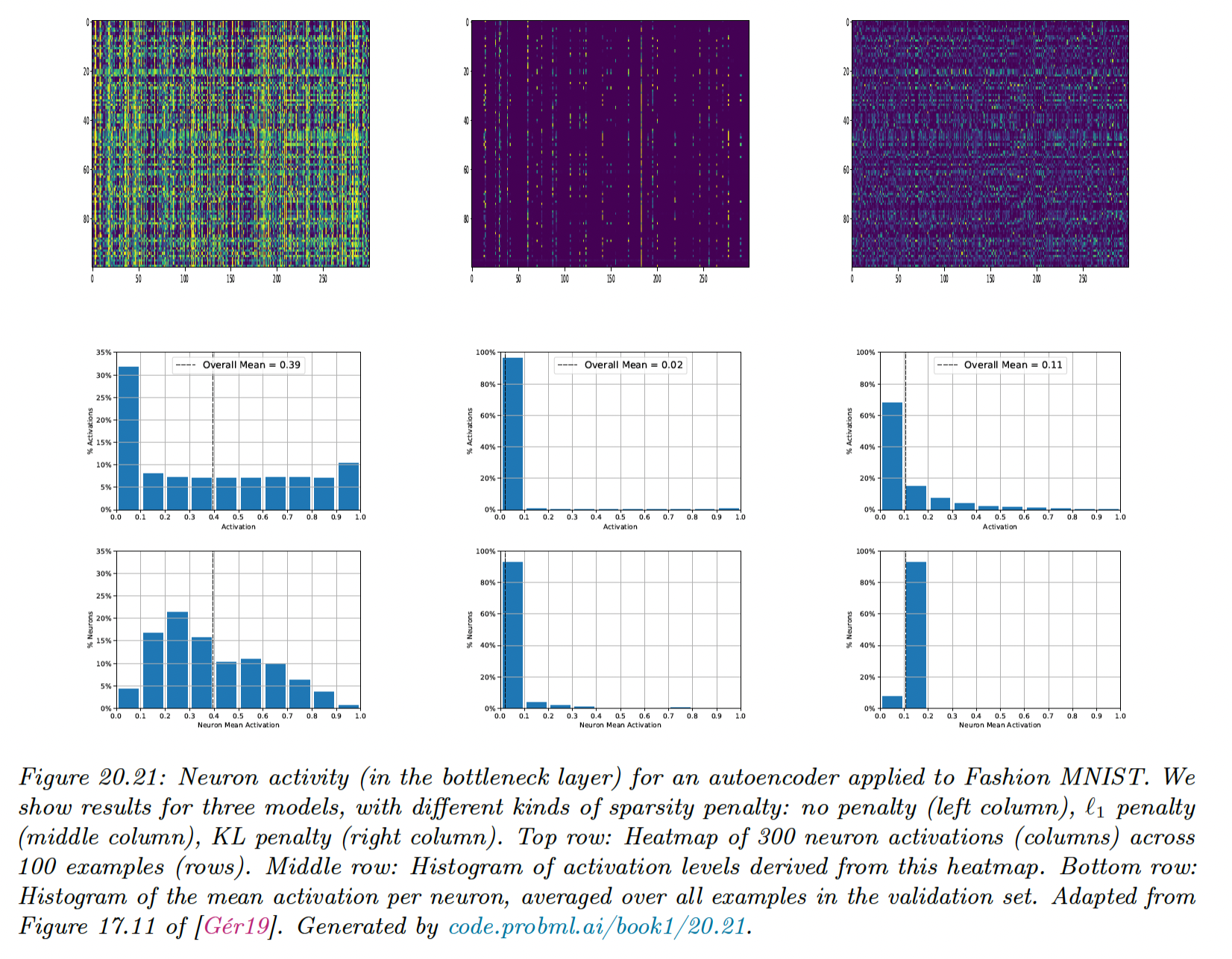
20.3.4 Sparse autoencoders
Another way to regularize AEs is to add a sparsity penalty to the latent activations of the form:
This is called activity regularization.
An alternative way to implement sparsity is to use logistic units, and then compute , the average activation on each unit in a minibatch.
We use:
where is the desired target distribution and is the empirical distribution for unit , computed as:
We show below the activation of the hidden layer for a AE-MLP (with 300 hidden units).
20.3.5 Variational autoencoders (VAE)
VAE can be thought of as a probabilistic version of the deterministic AE we previously saw. The principle advantage is that VAE is a generative model that can create new samples, whereas an autoencoder generates embeddings of input vectors.
VAEs combined two key ideas.
First we create a non linear extension of the factor analysis generative model, i.e. we replace:
with:
where is the decoder.
For binary observations we should use a Bernoulli likelihood:
Second, we create another model called the recognition network or inference network, that is trained simultaneously with the generative model to approximate the posterior inference.
If we assume the posterior is Gaussian with diagonal variance we get:
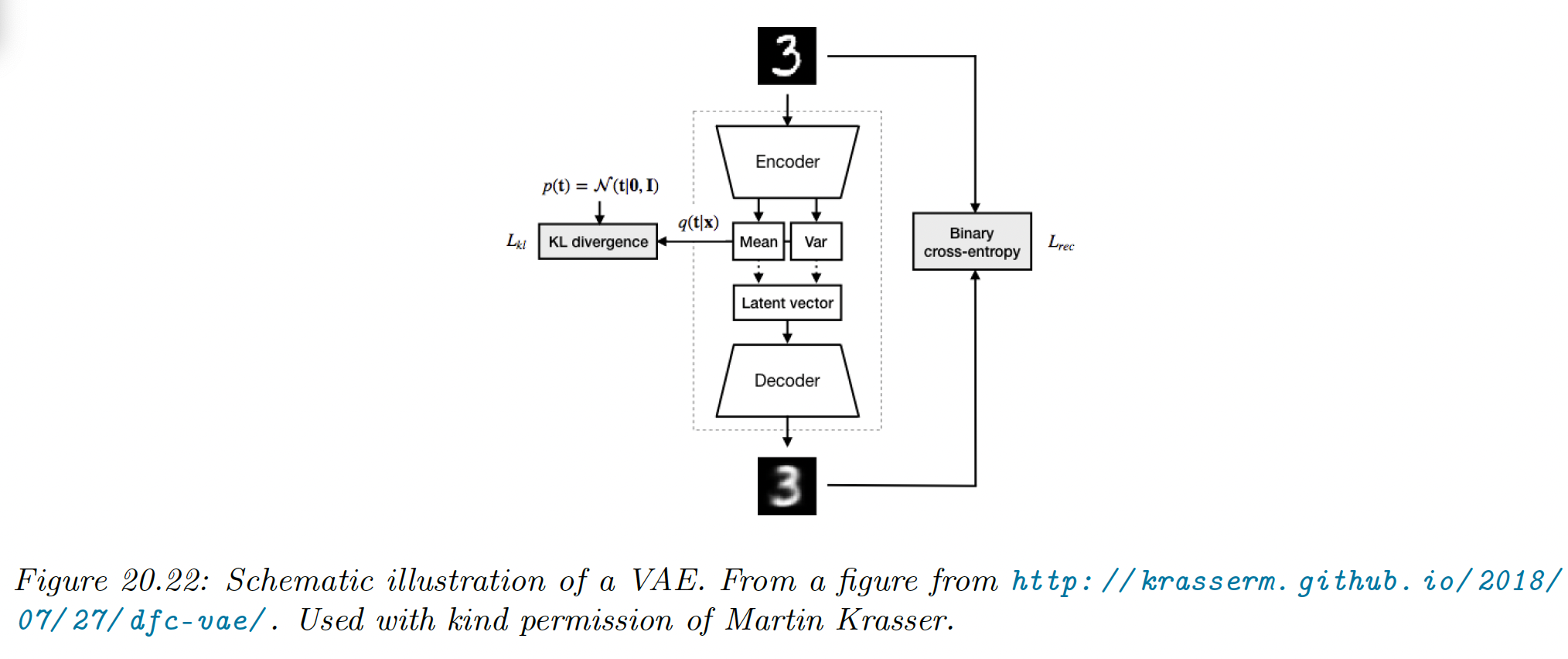
Thus, we train an inference network to “invert” a generative network, rather than running the optimization algorithm to infer the latent code. This is called amortized inference.
20.3.5.1 Trainings VAEs
We can’t compute the exact marginal likelihood needed for MLE training, because posterior inference in a nonlinear FA model is intractable. However, we can use the inference network to compute an approximation of the posterior .
We can then use this to compute the evidence lower bound (ELBO). For a single example , this is given by:
This can be interpreted as the expected log likelihood, plus a regularizer that penalize the posterior from deviating too much from the prior. This is different from sparse AEs where we apply KL penalty to the aggregate posterior in each minibatch.
The ELBO is a lower bound on the log marginal likelihood (aka evidence) as can be seen from Jensen’s inequality:
Thus, for a fix inference network , increasing the ELBO should increase the log likelihood of the data.
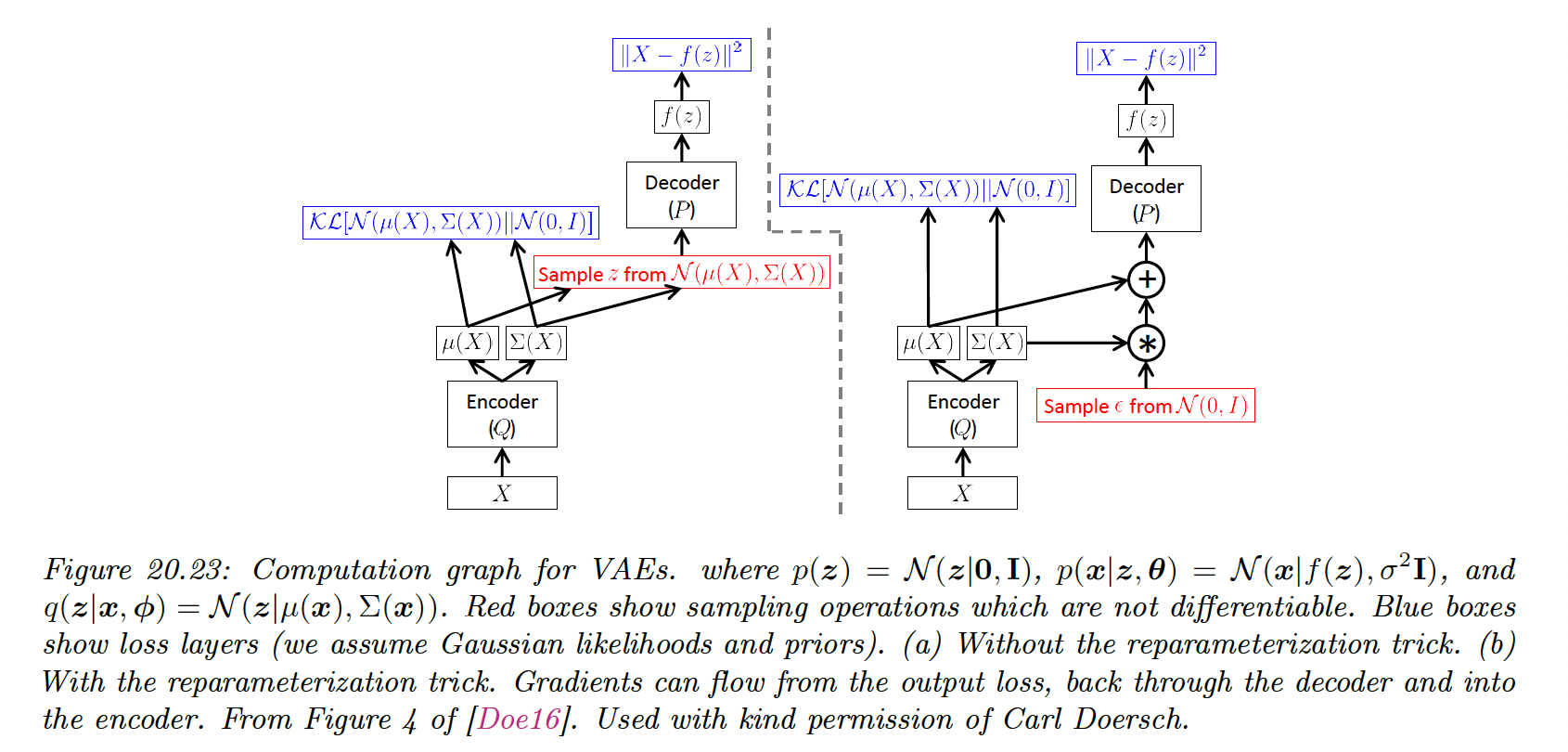
20.3.5.2 The reparameterization trick
We now discuss how to compute the ELBO and its gradient. Since is Gaussian, we can write:
where . Hence:
Now the expectation is independent of the parameters of the model so we can push gradients inside and use backpropagation for training the usual way, by minimizing wrt and . This is known as the reparameterization trick.
The first term of the ELBO can be approximated by sampling , scaling it by the output of the inference network to get , and then evaluating using the decoder network.
The second term of the ELBO is the KL of two Gaussian, which has a close form solution. In particular, by using and , we get:
(see section 6.3 for details).
20.3.5.3 Comparison of VAEs and autoencoders
VAEs are very similar to autoencoders, where the generative model acts like the decoder and the inference network acts like the encoder.
Their reconstruction abilities are similar.

The primary advantage of the VAE is that it can be used to generate new data from random noise. In particular, we sample , scale it to get and then pass this through the decoder to get .
The VAE’s decoder is trained to convert random points in the embedding space (generated by perturbing the input encodings) to sensible outputs.
By contrast, the decoder for the deterministic AE only ever gets as input the exact encodings of the training set, so it is not equipped to handle random inputs outside of what it has been trained on. So, a standard AE can’t create new samples.

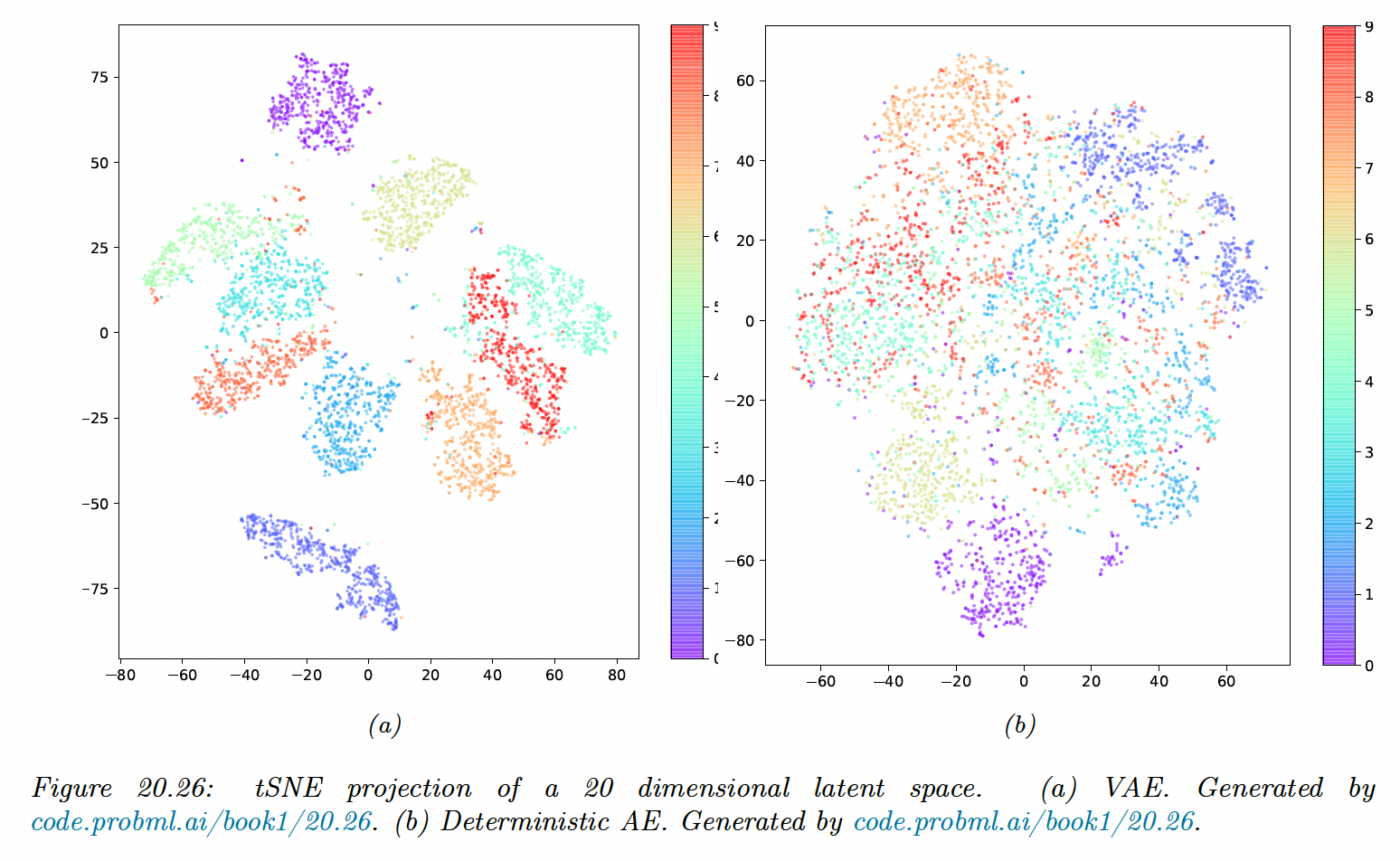
The reason the VAE is better at sample is that it embeds images into Gaussians in latent space, whereas the AE embeds images into points, which are like delta functions.
The advantage of using a latent distribution is that it encourages local smoothness, since a given image may map to multiple nearby places, depending on the stochastic sampling.
By contrast, in a AE, the latent space is typically not smooth, so images from different classes often end-up next to each other.
We can leverage smoothness of the latent space to perform linear interpolation.
Let and be two images and let and be their embeddings. We can now generate new images that interpolate between these two anchors by computing:
where , and then decoding by using .
This is called latent space interpolation. We can use a linear interpolation since it has been shown that the learned manifold has approximately zero curvature.
