22.1 Explicit feedback
We consider the simplest setting in which the user gives explicit feedback in terms of a rating, such as +1 or -1 (for like / dislike) or a score from 1 to 5.
Let be the rating matrix, for users and movies. Typically the matrix will be very large but very sparse since most users will not provide a feedbacks on most items.
We can also view the matrix as a bipartite graph, where the weight of the edge is . This reflects that we are dealing with relational data, i.e. the values of and don’t have intrinsic meaning (they are just indices), it is the fact that and are connected that matters.
If is missing, it could be that user didn’t interact with item , or that they knew they wouldn’t like it and choose not to engage with it. In the former case, the data is missing at random whereas in the second the missingness is informative about the true value of .
We will assume that data is missing at random for simplicity.
22.1.1 Datasets
In 2006, Netflix released a large dataset of 100m movie ratings (from a scale of 1 to 5) from 480k users on 18k movies. Despite its large size, the matrix is 99% sparse (unknown).
The winning team used a combination of techniques, see Lessons from the Netflix Challenge (opens in a new tab).
The Netflix dataset is not available anymore, but the MovieLens group has released an anonymized public dataset of movie ratings, on a scale of 1-5, that can be used for research. There are also the Jester jokes and the BookCrossing datasets.
22.1.2 Collaborative filtering
The original approach to the recommendation problem is called collaborative filtering. The idea is that users collaborate on recommending items by sharing their ratings with other users.
Then, if wants to know if they interact with , they can see what ratings other users have given to , and take a weighted average:
where we assume if the entry is unknown.
The traditional approach measured the similarity of two users by comparing the sets and , where is the set of items.
However, this can suffer from data sparsity. Below, we discuss about learning dense embedding for users and items, so that we are able to compute similarity in a low dimensional feature space.
22.1.3 Matrix factorization
We can view the recommender problem as one of matrix completion, in which we wish to predict all the missing entries of . We can formulate this as the following optimization problem:
However, this is an under-specified problem, since there are an infinite number of ways of filling in the missing entries of .
We need to add some constraints. Suppose we assume that is low-rank. Then we can write it in the form:
where and , is the rank of the matrix.
This corresponds to a prediction of the form:
This is called matrix factorization.
If we observe all entries, we can find the optimal using SVD. However, when has missing entries, the corresponding objective is no longer convex, and doesn’t have a unique optimum.
We can fit this using alternative least square (ALS) (opens in a new tab), where we estimate given and then given . Alternatively, we can use SGD.
In practice, it is important to also follow for user-specific and item-specific baselines, by writing:
This can capture the fact that some users tend to give low or high ratings, and some items may have unusually high ratings.
In addition, we can add some regularization to the parameters to get the objective:
We can optimize using SGD by sampling an entry from the set of observed values, and performing the update:
where is the error term, and is the learning rate.
This approach was first introduced by Simon Funk, who was one of the first to do well in the early days of the Netflix challenge (opens in a new tab).
22.1.3.1 Probabilistic matrix factorization (PMF)
We can convert matrix factorization into a probabilistic model by defining:
This is known as probabilistic matrix factorization (PMF).
The NLL is equivalent to the matrix factorization objective. However, the probabilistic perspective allows us to generalize the model more easily.
For example, we can capture the fact that ratings are positive integers (mostly zeros) instead of reals by using a Poisson or negative Binomial likelihood.
22.1.3.2 Example: Netflix
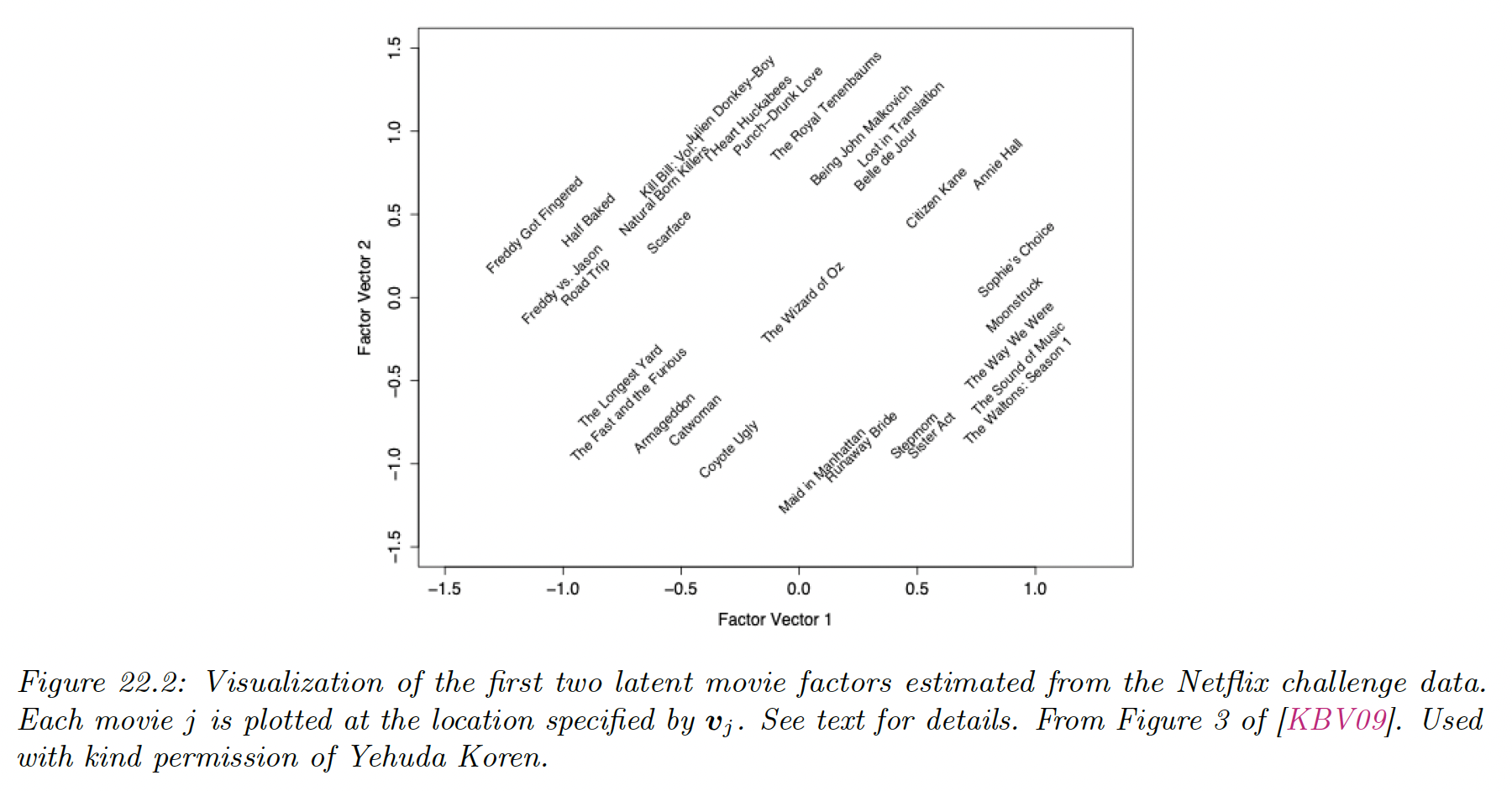
We apply PMF to the Netflix dataset using latent factors. The figure below visualizes some learning embedding vectors .
Left is humor and horror movies, while movies on the right are more serious. Top is critically acclaimed independent movie and on the bottom mainstream Hollywood blockbusters.
Users are embedded into the same space as movies, we can then predict the rating for any user-video pair using proximity in the latent embedding space.
22.1.3.3 Example: MovieLens
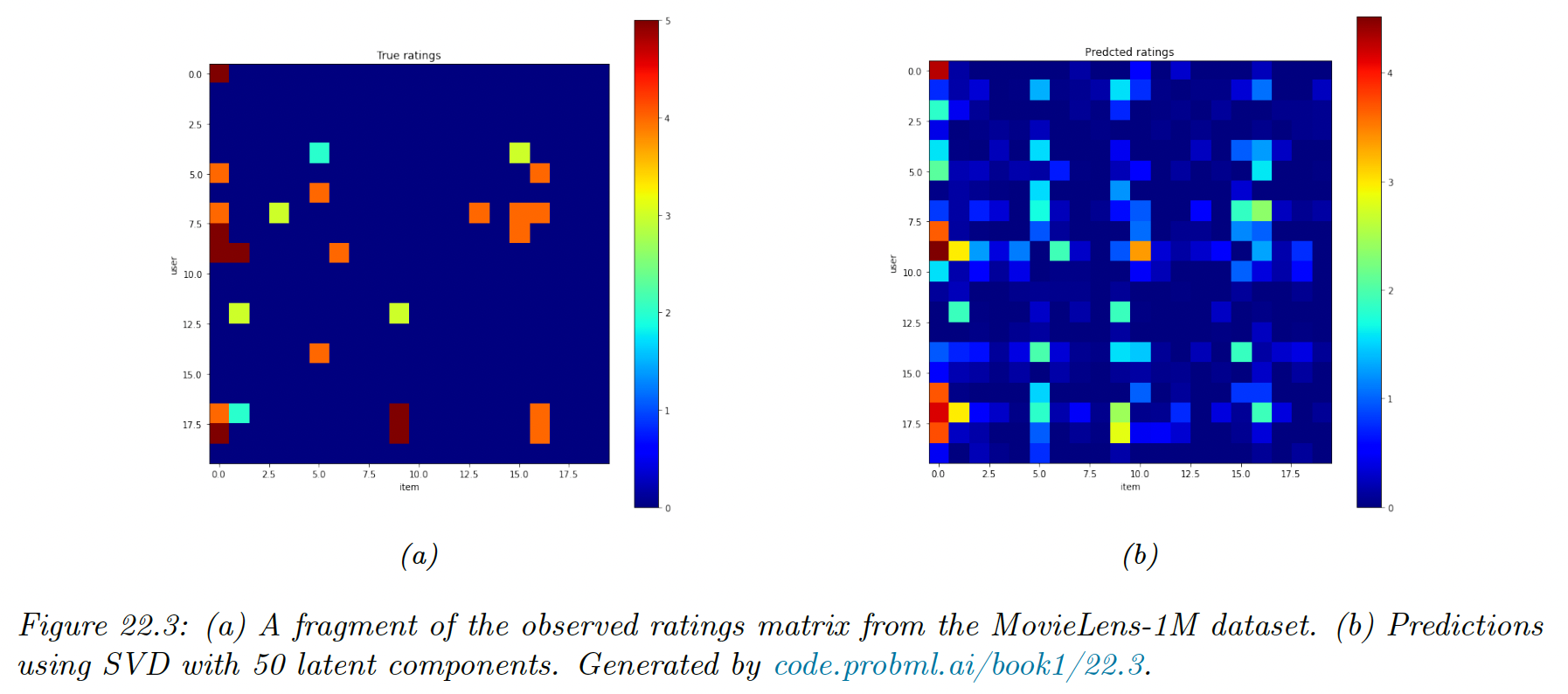
We apply PMF to the MovieLens-1M dataset with 6k users, 3k movies and 1m ratings. We use factors.
For simplicity, we fit this using SVD applied to the dense ratings matrix, where we replace the missing values with 0. We truncate the predictions so that they lie in the range .
We see that the model is not particularly accurate but it captures some structure in the data.
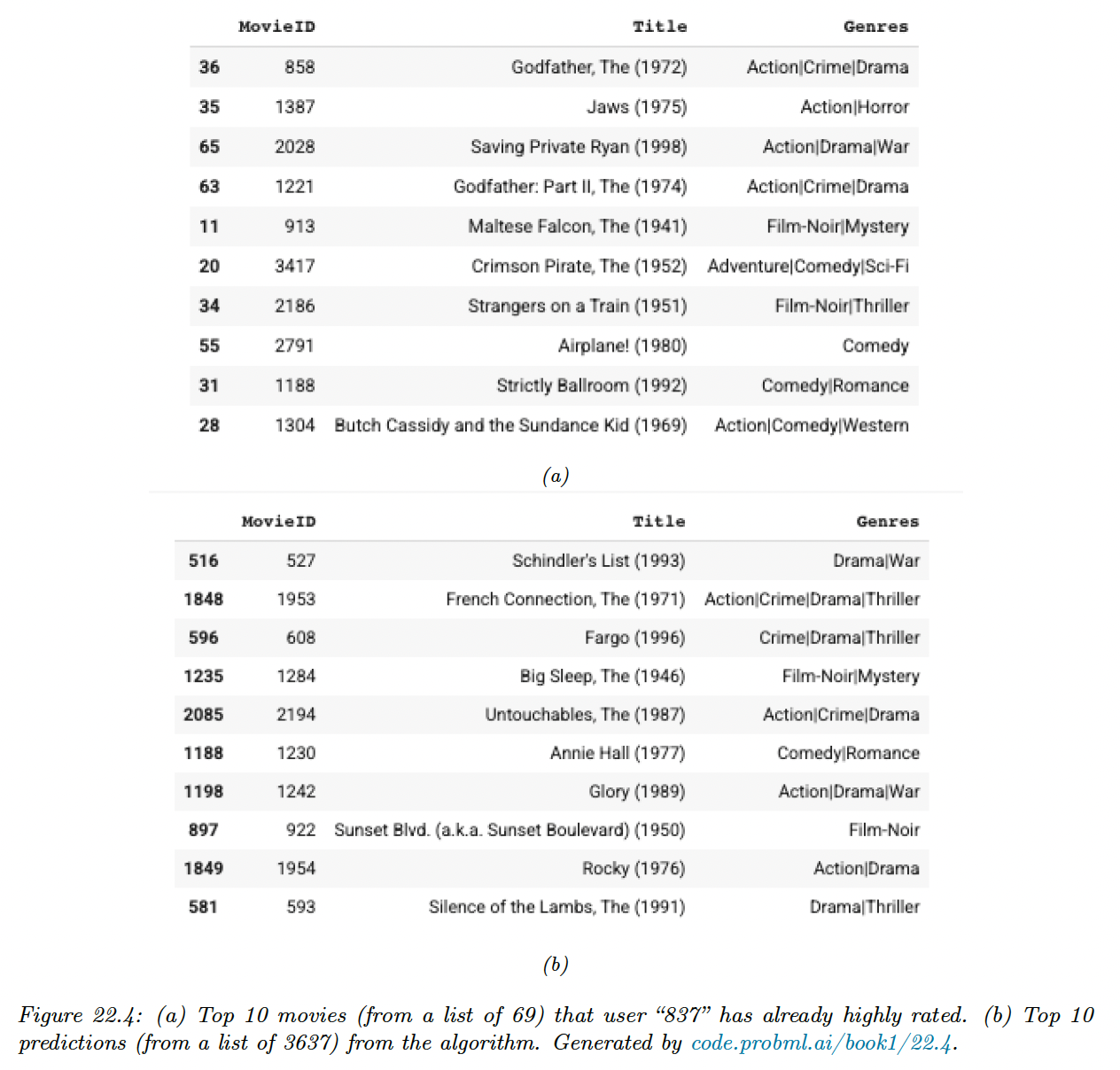
Furthermore, it seems to behave in a qualitatively sensible way. Below, we show the top 10 movies rated by a user and show the top 10 predictions for movies they had not seen.
Without giving explicit informations, the model captured the underlying preference for action and film-noir.
22.1.4 Autoencoders
Matrix factorization is a (bi)linear model. We can make it nonlinear using autoencoders.
Let be the th column of the rating matrix, where unknown ratings are set to 0.
We can predict this ratings vector using an autoencoder of the form:
where maps the ratings to the embedding space, maps the embedding space to a distribution over ratings, are the biases of the hidden units, are the biases of the output units and is the sigmoid activation function.
This is called the item-based version of the AutoRec (opens in a new tab) model. This has parameters.
There is also a user-based version with parameters, but on both MovieLens and Netflix, the authors find the item-based version works better.
We can fit this by only updating parameters that are associated with the observed entries of , and add a regularizer to get the objective:
Despite the simplicity of the method, authors find that this does better than restricted Boltzmann machines (RBMs) and local low-rank matrix (LLORMA).