7.1 Introduction
7.1.1 Notation
Vector
A vector is usually written as a column vector:
The vector of all ones is , of all zeros is .
The unit or one-hot vector is a vector of all zeros except entry which is .
Matrix
A matrix is defined similarly. If the matrix is square.
The transpose of a matrix results in flipping its row and columns: . Some of its properties:
A symmetric square matrices satisfies . The set of all symmetric matrices of size is denoted .
Tensor
A tensor is a generalization of a 2d array:
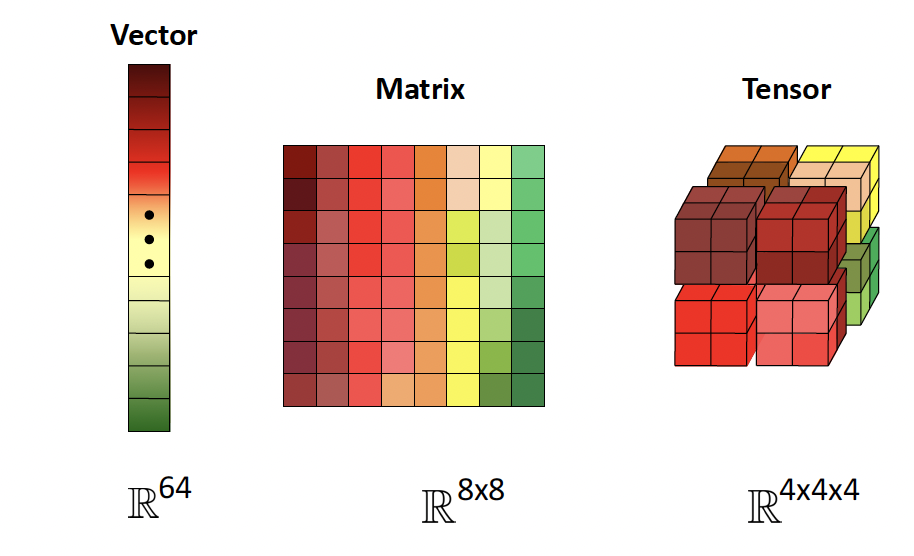
The rank of a tensor is its number of dimensions.
We can stack rows (resp columns) of a matrix horizontally (resp vertically) to get a C-contiguous or row-major order (resp F-contiguous or columns-major order).
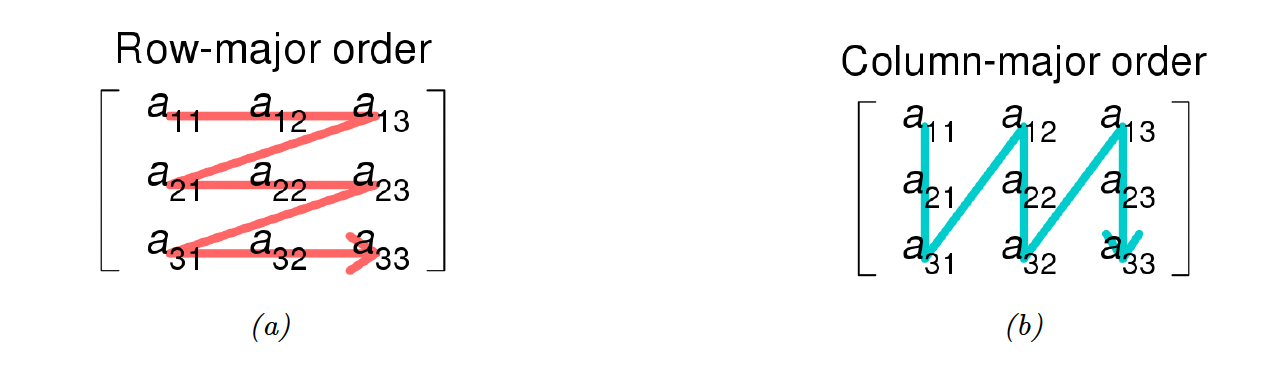
7.1.2 Vector spaces
Spans
We can view a vector as a point in n-dimensional Euclidean space. A vector space is a collection of such vector, which can be added together and scale by scalar .
A set of vector is linearly independent if no vector can be represented as a linear combination of the others.
The span of is the set of all vectors that can be obtained its linear combinations:
It can be shown that if each form a set of linearly independent vectors, then:
and therefore any vectors of can be written as a linear combination of this set of vector.
A basis is a set of linearly independent vector that spans the whole space:
There are often multiple basis to choose from, a standard one is the coordinate vectors .
Linear maps
A linear map is the transformation such that:
Once the basis of is chosen, a linear map is completely determined by computing the image basis of .
Suppose we can compute and store it in .
We can then compute any for any by:
The range of the space reached by the matrix :
The nullspace is:
Linear projection
The projection of onto the span with , is:
And for a full rank matrix , with , we can define the projection of on the range of
7.1.3 Vector and matrix norms
Vector norms
A norms is any function that satisfies the following properties:
- non-negativity:
- definiteness:
- absolute value homogeneity:
- triangle inequality:
Common norms:
-
p-norm: , for
-
or Manhattan:
-
or Euclidean:
also note the square euclidean:
-
max-norm or Chebyshev:
-
zero-norm: . This is a pseudo norm since it doesn’t respect homogeneity.
Matrix norms
i) Induced norms
Suppose we think of a matrix as defining a linear function .
We define the induced norm of as the maximum amount by which can lengthen input:
In the special case of (the Euclidean norm), the induced norm is the spectral norm:
with the th singular value
ii) Element-wise norms
If we treat a matrix as a vector of size , we can define the -norm:
when , we get the Frobenius norm:
If is expensive but is cheap, we can approximate the F-norm with the Hutchinson trace estimator:
with
iii) Schatten norms
The Schatten -norms arise when applying the element-wise -norm to the singular values of a matrix:
When , we get the nuclear norm (or trace norm):
since .
Using this as a regularizer encourages many singular values to become zero, resulting in a low-rank matrix.
When , we get the Frobenius norm.
When , we get the Spectral norm
7.1.4 Properties of a matrix
Trace
The trace of a square matrix is:
We have the following:
This last property allows to define the trace trick:
In some case, might be expensive but cheap, we can use the Hutchinson trace approximator:
with
Determinant
The determinant is a measure of how much a square matrix change a unit volume when viewed as a linear transformation.
With :
- iff is singular
- If is not singular,
- , where are the eigenvalues of
For a positive definite matrix, where is a lower triangle Cholesky decomposition:
so
Rank
The column (resp row) rank is the dimension spanned by the columns (resp rows) of a matrix, and its a basic fact that they are the same:
-
For ,
If equality, is said to be full rank (it is rank defficient otherwise).
-
-
For ,
-
For ,
-
A square matrix is invertible iff full rank
Condition number
All norms that follow are .
The condition number of a matrix measures of numerically stable any computation involving will be:
If is close to 1, the matrix is well conditioned (ill-conditioned otherwise).
A large condition means is nearly singular. This a better measure to nearness of singularity than the size of the determinant.
For exemple, leads to but , indicating that even though is nearly singular, it is well conditioned and simply scales the entry of by 0.1.
7.1.5 Special types of matrices
Diagonal matrices All elements are 0 except the diagonal.
We can convert a vector to a diagonal matrix with this notation
Identity matrix Diagonal of ones, with the identity property:
Block diagonal matrix
Non zero only on the main diagonal:
Band-diagonal matrix Non-zero entries along k-sides of the diagonal:

Triangular matrix Upper (resp lower) have only non-zero on the diagonal and above (resp below)
Useful property: the diagonal is the eigenvalues, therefore
Positive definite matrices
A symmetric matrix is positive definite iff:
If equality is possible, we call positive semi-definite.
The set of all positive definite matrices is denoted
A matrix can also be negative definite or indefinite: there exists and such that:
Note that a matrix having all positive coefficient doesn’t imply being positive definite ex:
Conversely, it can have negative coefficient.
For a symmetric, real matrix, a sufficient condition for positive definiteness is having the diagonal coefficient “dominate” their rows:
The Gram-matrix is always positive semidefinite.
If is full rank and , then is positive definite.
Orthogonal matrices
-
are orthogonal if
-
is normalized if
-
A set of vectors that is pairwise orthogonal and normalized is called orthonormal
-
is orthogonal if all its columns are orthonormal (note the difference of notation)
If all entries of are complex valued, we use the term unary instead of orthonormal
If is orthogonal:
In otherwords,
One nice property is norm invariance when operating on a vector:
with and non-zero
Similarly, the angle is unchanged after a transformation with an orthogonal matrix:
In summary, orthogonal matrices are generalization of rotation (if ) and reflections (if ) since they preserves angle and lenghts.