14.2 Common layers
14.2.1 Convolutional layers
We describe the basics of 1d and 2d convolution and their role in CNNs.
14.2.1.1 Convolution in 1d
The convolution between two functions is:
If we use discrete functions, we evaluate
- at the points to yield the filter
- at the points to yield the feature vector
The above equation becomes:

Cross-correlation is a close operation where we don’t “flip” the weight vector. After eliminating the negative indices:
If the weight vector is symmetric, as it’s often the case, then cross-correlation and convolution are the same.
In deep learning, cross-correlation is often called “convolution”, and we will follow this convention.

14.2.1.2 Convolution in 2d
In 2d, the cross-correlation equation becomes:
where the 2d filter has size .
For instance, convolving a input with a kernel :
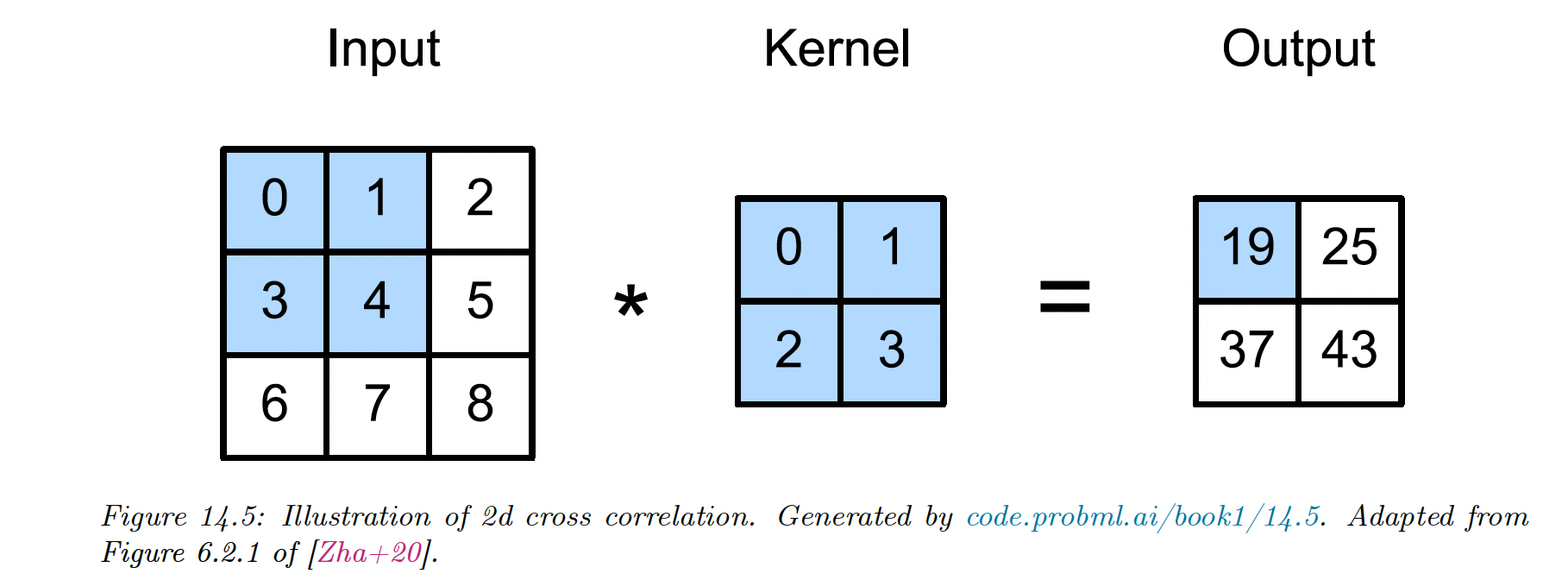
We can think of 2d convolution as feature detection: if represents an edge, the activation will “light-up” where an edge is present in the input.
The result is therefore called a feature map.

14.2.1.3 Convolution as matrix-vector multiplication
Since convolution is a linear operator, we can represent it by matrix multiplication. By flattening into , we get:
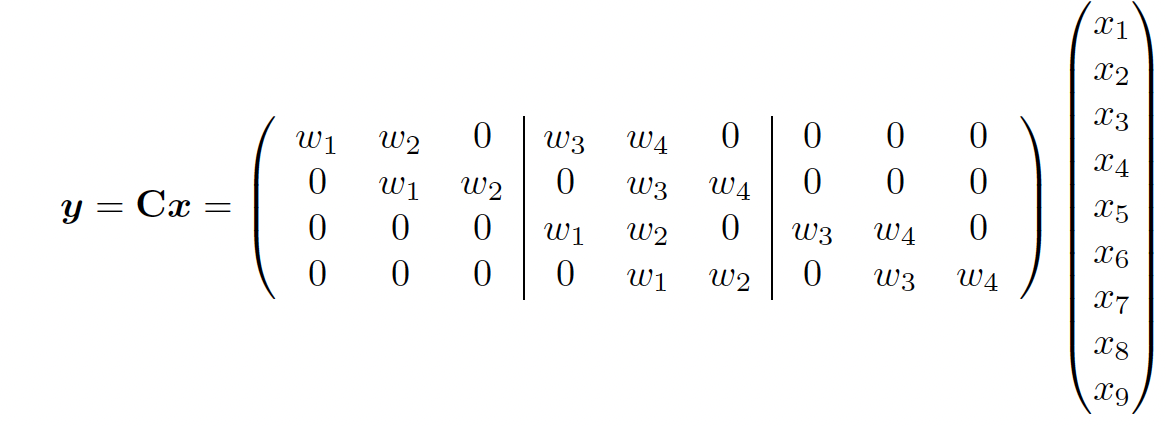
We see that CNNs are like MLPs where the weight matrices have a special spatial sparse structure.
This implements the idea of translation invariance and reduces the number of parameters compared to a dense layer.
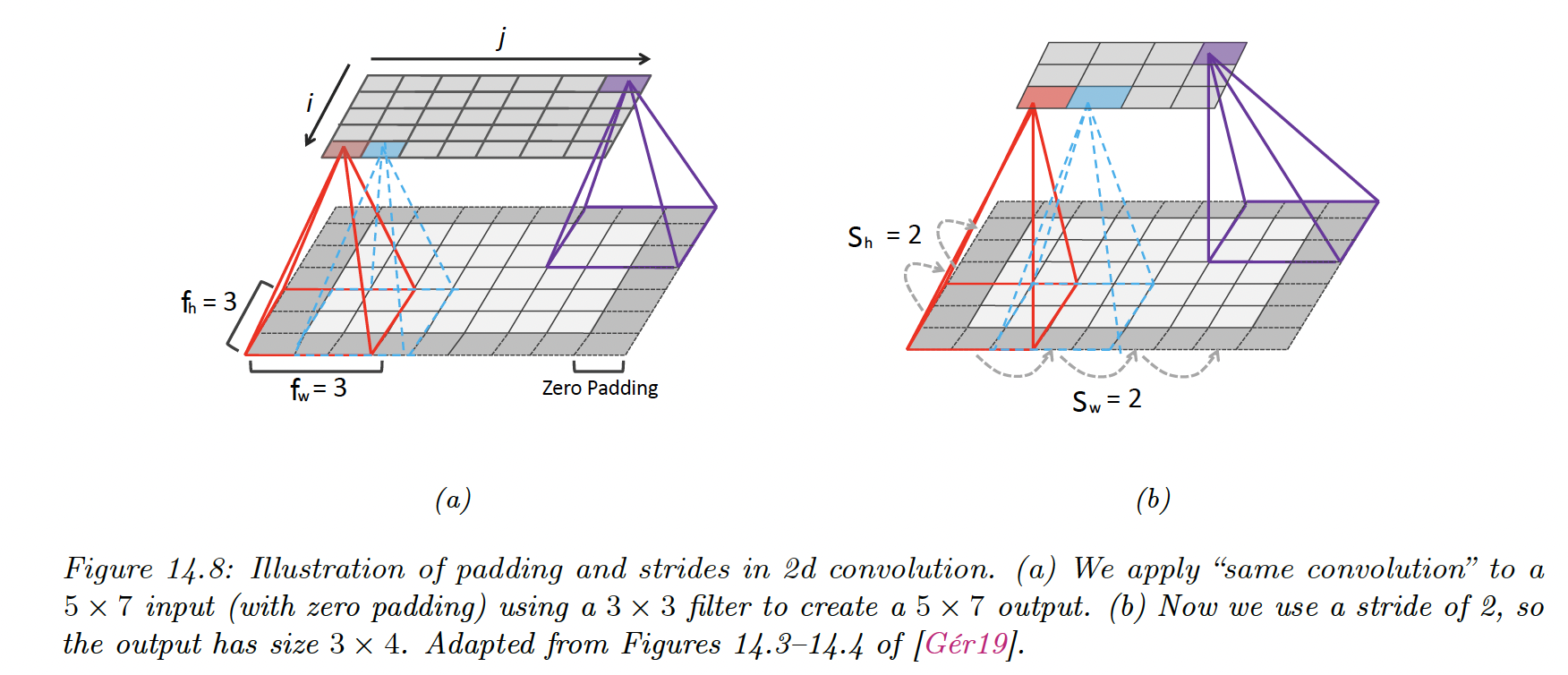
14.2.1.4 Boundary conditions and padding
- Valid convolution, where we only apply the filter to “valid” parts of the image, produces outputs that are smaller than inputs
- Same convolution uses zero-padding (adding a border of 0s) on the input to ensure the size of input and output are the same.
14.2.1.5 Strided convolutions
Since every output pixel is generated by a weighted combination of inputs in its receptive field, neighboring outputs will have similar values because their inputs are overlapping.
We can reduce this redundancy by choosing a stride different than 1.
Given:
- the input has size
- the filter ,
- we use zero padding on each side of size and
- we use strides of size and
The output size will be:
14.2.1.6 Multiple inputs and output channels
If the input image is not grayscale but has multiple channels (RGB or hyper-spectral bands for satellite images) we can extend the definition of convolution using a 3d weight matrix or tensor:
where is the stride (same for height and width for simplicity) and is the bias term.
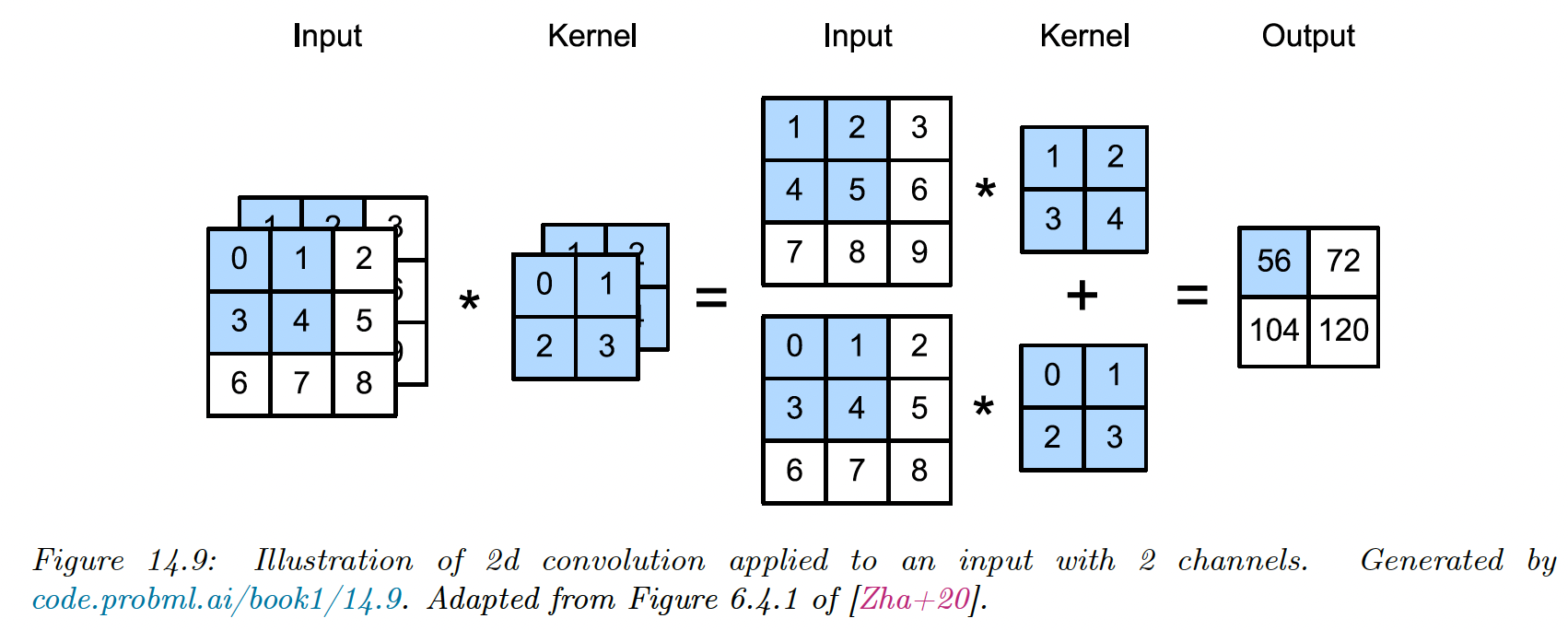
Each weight matrix can only detect a single type of pattern, but we usually want to detect many.
We can do this by using a 4d weight matrix, where the filter to detect feature in channel is stored in
The convolution becomes:
which is exactly the formula used in PyTorch Conv2d (opens in a new tab).
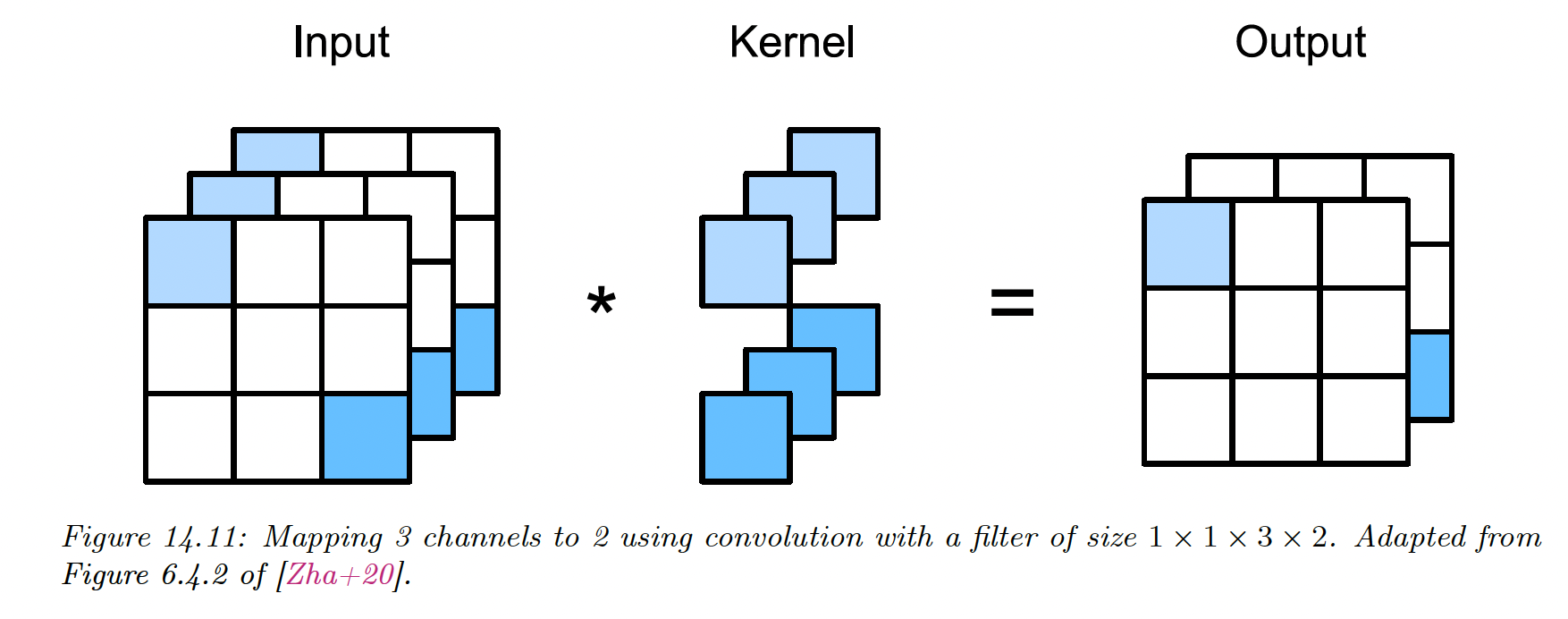
Each vertical cylindrical column is a set of output features at , this is called a hypercolumn.
Each element is a different weighted combination of the features in the receptive field of the layer below.
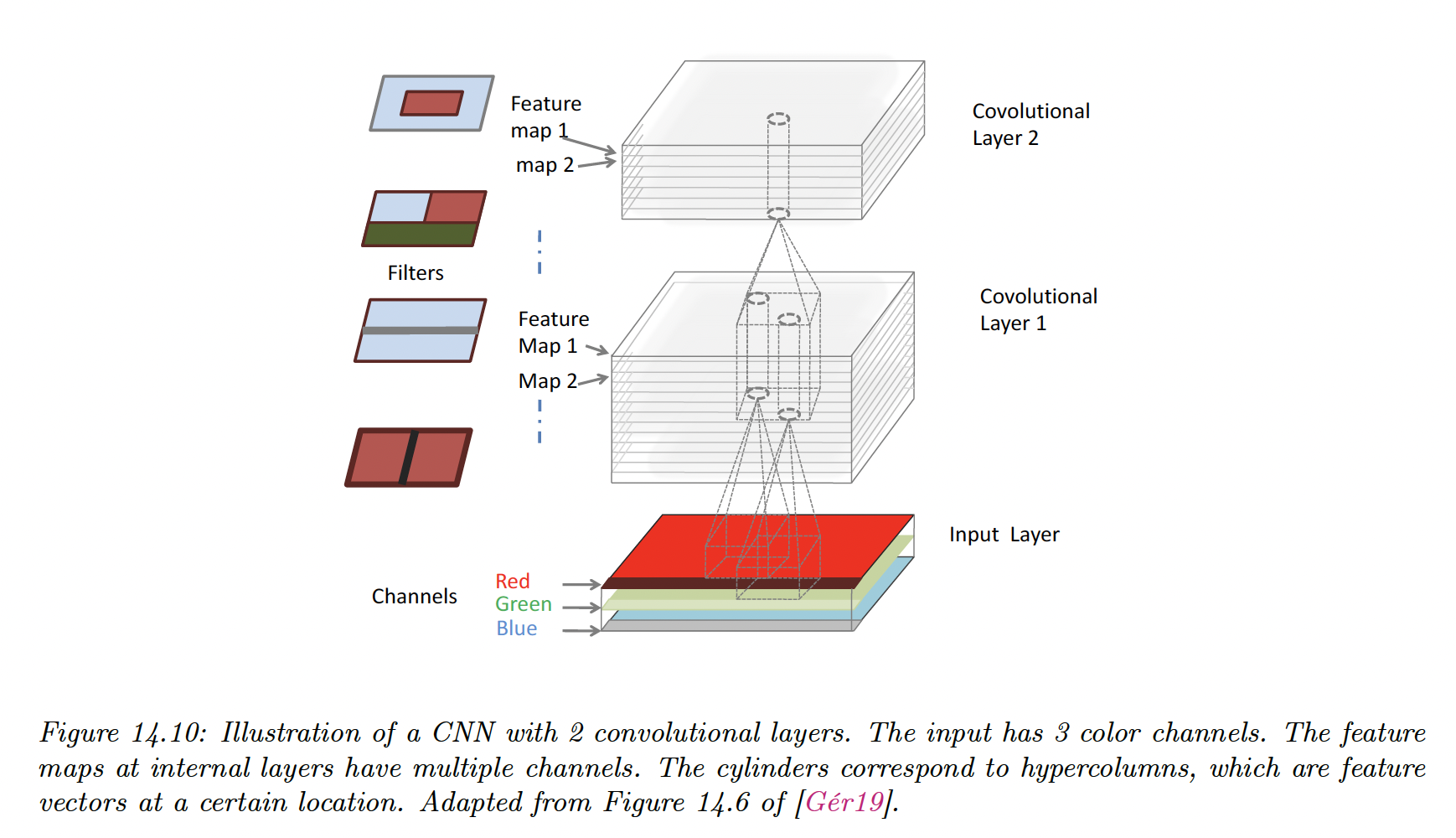
14.2.1.7 Pointwise () convolution
Sometimes, we want to take a weighted combination of the feature at a given location, instead of across locations. This can be achieved with pointwise (or 1x1) convolution.
This changes the number of channels from to and can be thought of as a linear layer applied to a 2D input.
14.2.2 Pooling layers
Convolution preserves spatial information, this property is known as equivariance.
Sometimes, we want to be invariant to the location, e.g. we want to know if an object is inside the image or not, regardless of its location.
This can be achieved using max pooling, which just computes the maximum over its incoming values. An alternative is to use average pooling, replacing the max by the mean.
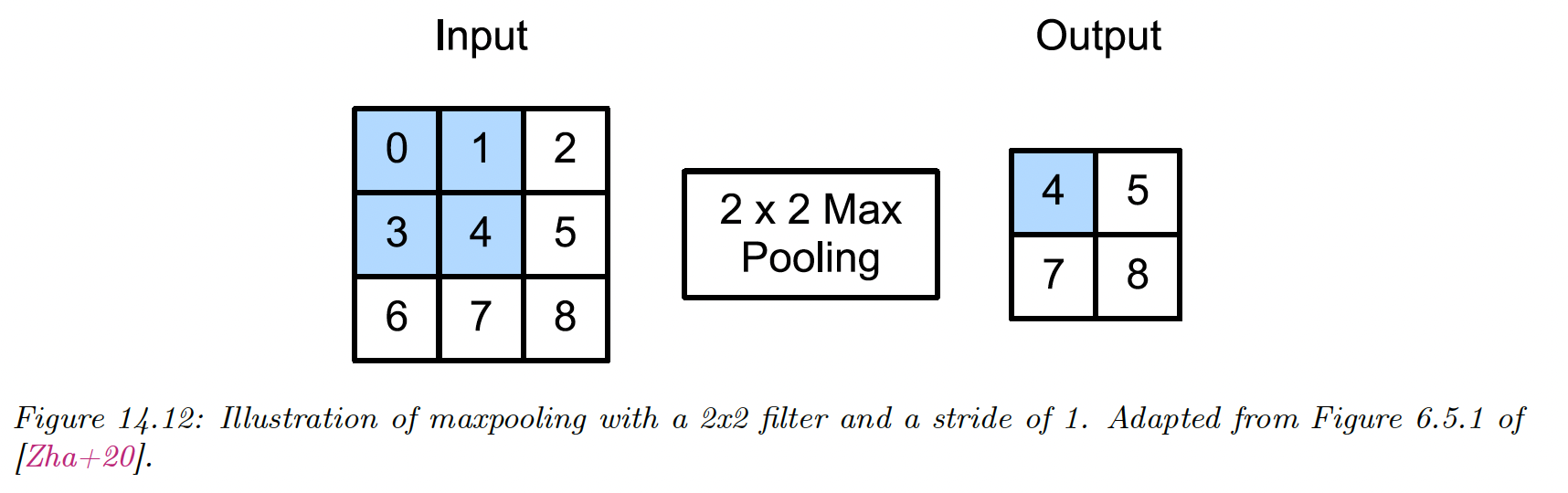
If we average over all locations in the feature map, this is called global average pooling. This converts a feature map dimensions from to .
This can then be reshaped as a -dimensional vector, passed to a fully connected layer to convert it into a -dimensional vector, then finally passed to a softmax output.
The use of global average pooling means we can use images of any size since the final feature map will always be converted to a dimensional vector before being mapped to a distribution over the classes.
This is available under the MaxPool2d operator (opens in a new tab) in PyTorch
14.2.3 Putting it all together
A common design pattern is to create a CNN by alternating convolution layers with max-pooling layers, followed by a linear classification at the end.
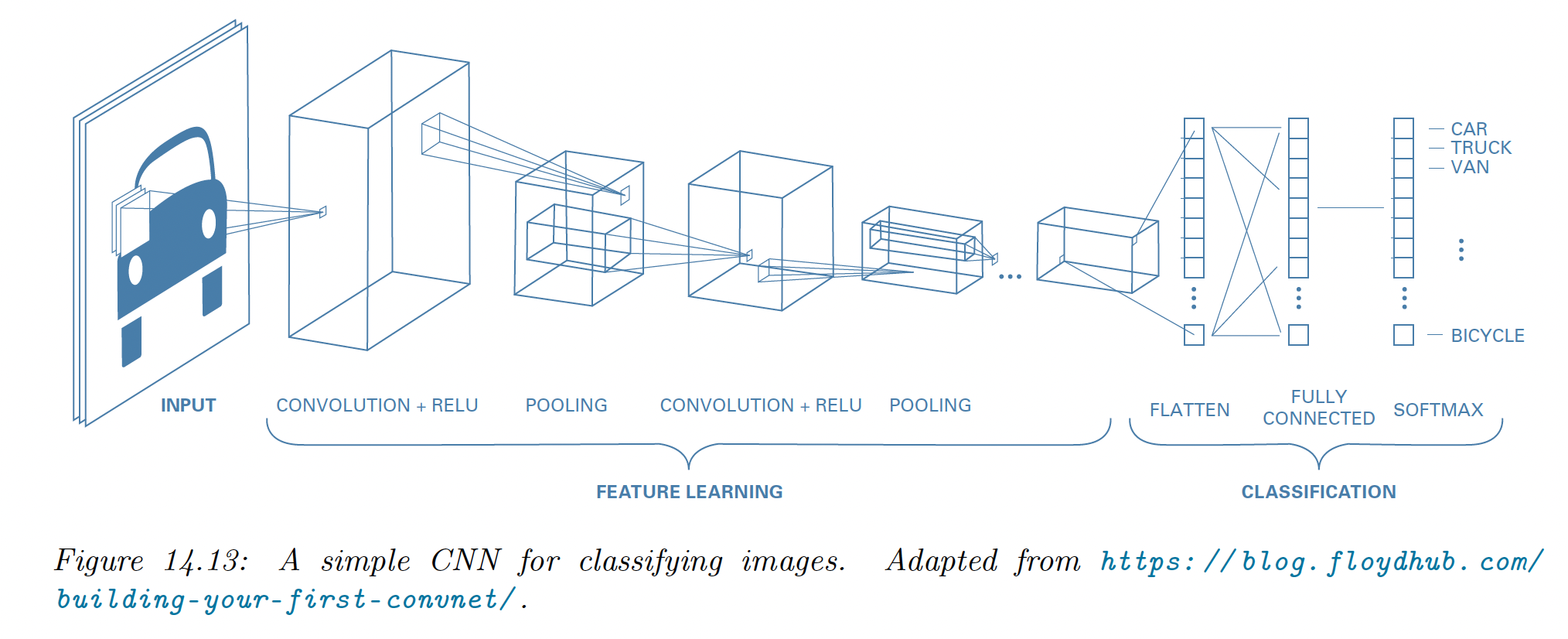
We omit normalization layers in this example since the model is shallow.
This design pattern first appeared in Fukushima’s neocognitron and in 1998 Yann LeCun used it in its eponymous LeNet model, which also used SGD and backprop to estimate its parameters.
14.2.4 Normalization layers
To scale this design to deeper networks and avoid vanishing or exploding gradient issues, we use normalizing layers to standardize the statistics of the hidden units.
14.2.4.1 Batch normalization
The most popular normalization layer is batch normalization (BN). This ensures the distribution of activations within a layer has zero mean and unit variance, when average across the samples in a minibatch:
where is the minibatch containing example , and are learnable parameters for this layer (since this operation is differentiable).
The empirical means and variance of layers keep changing, so we need to recompute and for each minibatch.
At test time, we might have a single input, so we can’t compute batch statistics. The standard solution is to:
- Compute and for each layer using the full batch
- Freeze these parameters and add them along and
- At test time, use these frozen parameters instead of computing the batch statistics
Thus, when using a model with BN, we need to specify if we are using it for training or inference.
PyTorch implements this with BatchNorm2d (opens in a new tab).
For speed, we can combine a frozen batch norm layer with the previous layer. If the previous layer computed , using BN yields:
We can write the combined layers as the fused batch norm:
where and
The benefits of batch normalization for CNN can be quite dramatic, especially for the deeper ones. The exact reasons are still unclear, but BN seems to:
- make the optimization landscape a bit smoother
- reduce the sensitivity to the learning rate (allow a larger one)
In addition to computation advantages, it also has statistical advantages since it plays the role of a regularizer. It can be shown to be equivalent to a form of approximate Bayesian inference.
However, the reliance on a minibatch of data can result in unstable estimates when training with small batch sizes, even though **batch renormalization (opens in a new tab)** partially addresses this using rolling means on batch statistics.
14.2.4.2 Other kinds of normalization layers
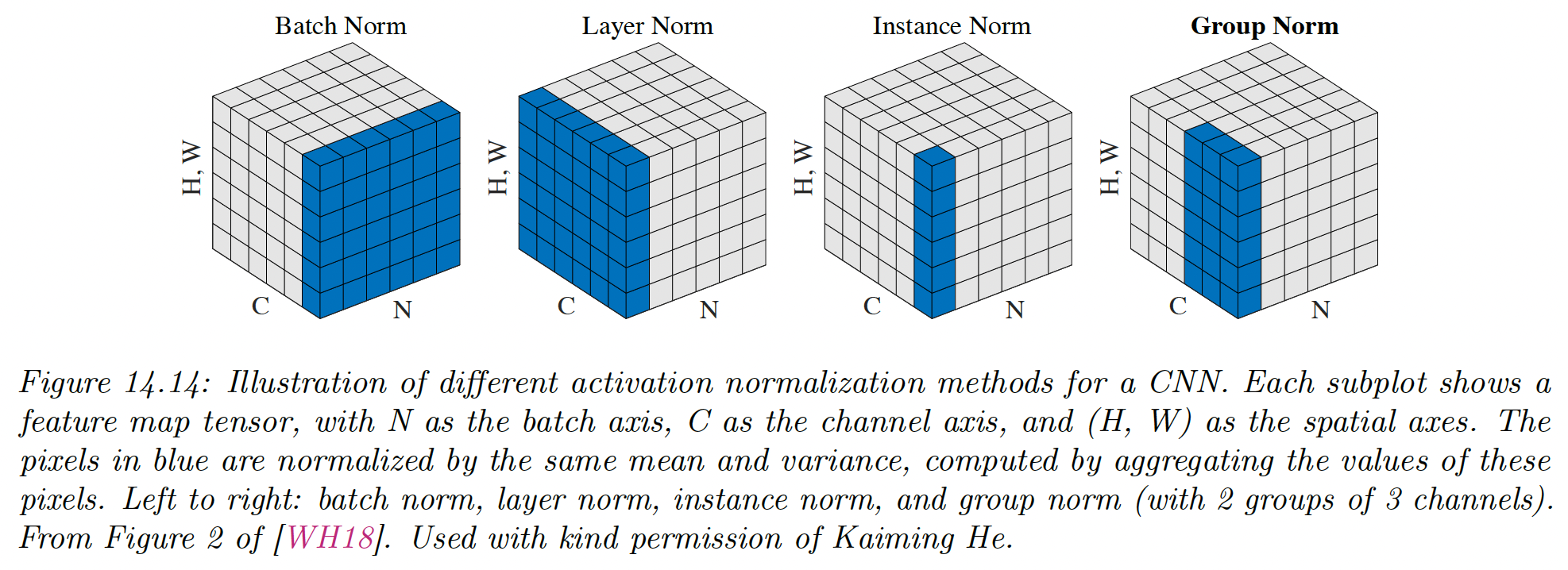
While batch normalization struggles with small batch size, we can pool statistics from other dimensions of the tensor:
- Layer norm pools over channel, height, and width and match on the batch index
- Instance norm pools do the same but for each channel separately
- Grouping norm generalizes this to group of channels
More recently, **filter response normalization (opens in a new tab) (FRN)** has been proposed as an alternative to batch norm that works well on image classification and object detection, even when batch size is 1.
It is applied to each channel and each batch like instance norm, but instead of standardizing it divide by the mean squared norm:
Since there is no mean centering, the output can drift away from 0, which can have detrimental effects, especially with ReLU activations.
To compensate for it, the authors suggest adding a thresholded linear unit (TLU) at the output, that has the form:
where is a learnable offset.
14.2.4.3 Normalization-free networks
Recently, normalizer-free networks (opens in a new tab) have been proposed for residual networks. The key is to replace batch norm with adaptive gradient clipping, as an alternative way to avoid training instabilities.
We therefore use:
but adapt the clipping strength dynamically.
The resulting model is faster to train and more accurate than other competitive models trained with batch norm.