13.6 Other kinds of feedforward networks
13.6.1 Radial basis function networks
Consider a 1-layer neural network where the hidden units are given by:
where are a set of centroids, and is a kernel function (see section 17.1).
We use the simplest kernel function, the Gaussian kernel:
where is called the bandwith. This is called a radial basis function (RBF) kernel.
A RBF network has the form:
where . The centroids can be fixed or learned using unsupervised learning methods like K-means.
Alternatively, we can associate one centroid per datapoint, with . This is an example of non-parametric model, since the number of parameters grow with the size of the data.
If the model can perfectly interpolate the data and overfit. However, by ensuring the weights are sparse, the model will use a finite number of weights and will result in a sparse kernel machine.
Another way to avoid overfitting is to use a Bayesian approach, by marginalizing the weights, this gives rise to the Gaussian process model.
13.6.1.1 RBF network for regression
We can use RBF for regression by defining:
Below, we fit 1d data to a model with uniformly spaced RBF clusters, with the bandwith ranging from low to large.
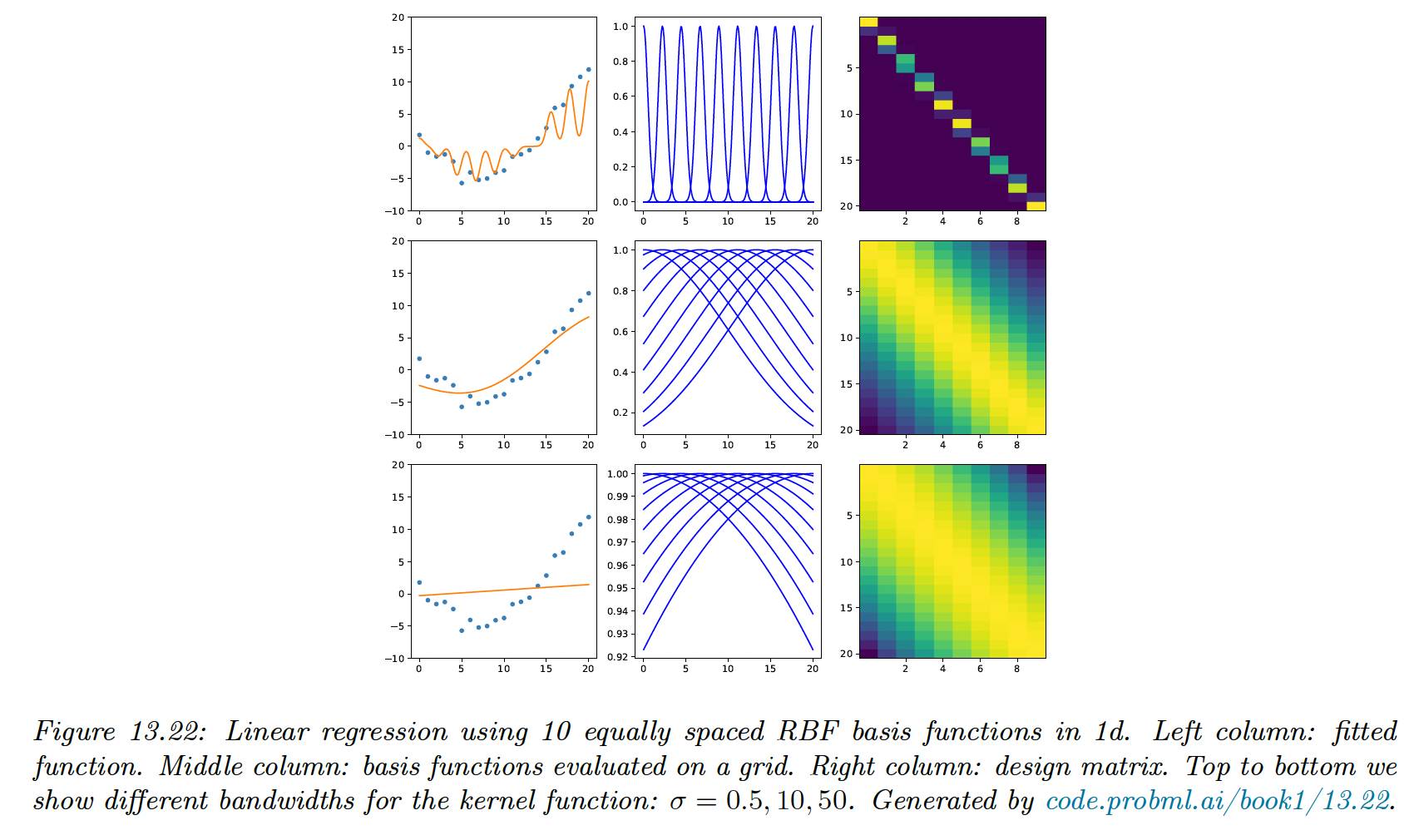
When the bandwidth is small, the predicted function is wiggly since points far from the clusters will lead to predicted value of 0.
On the contrary, if the bandwidth is large, each points is equally close to all clusters, so the prediction is a straight line.
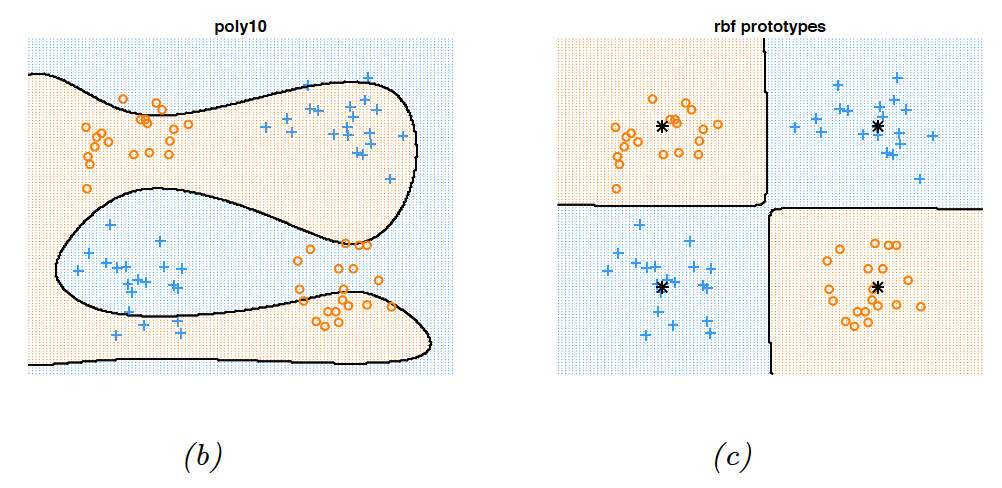
13.6.1.2 RBF network for classification
We can use RBF in classification by considering:
RBF are able to solve the XOR problem.
13.6.2 Mixtures of experts
When considering regression, it is common to assume an unimodal output distribution. However, this won’t work well with one-to-many functions, in which each input is mapped to multiple outputs.
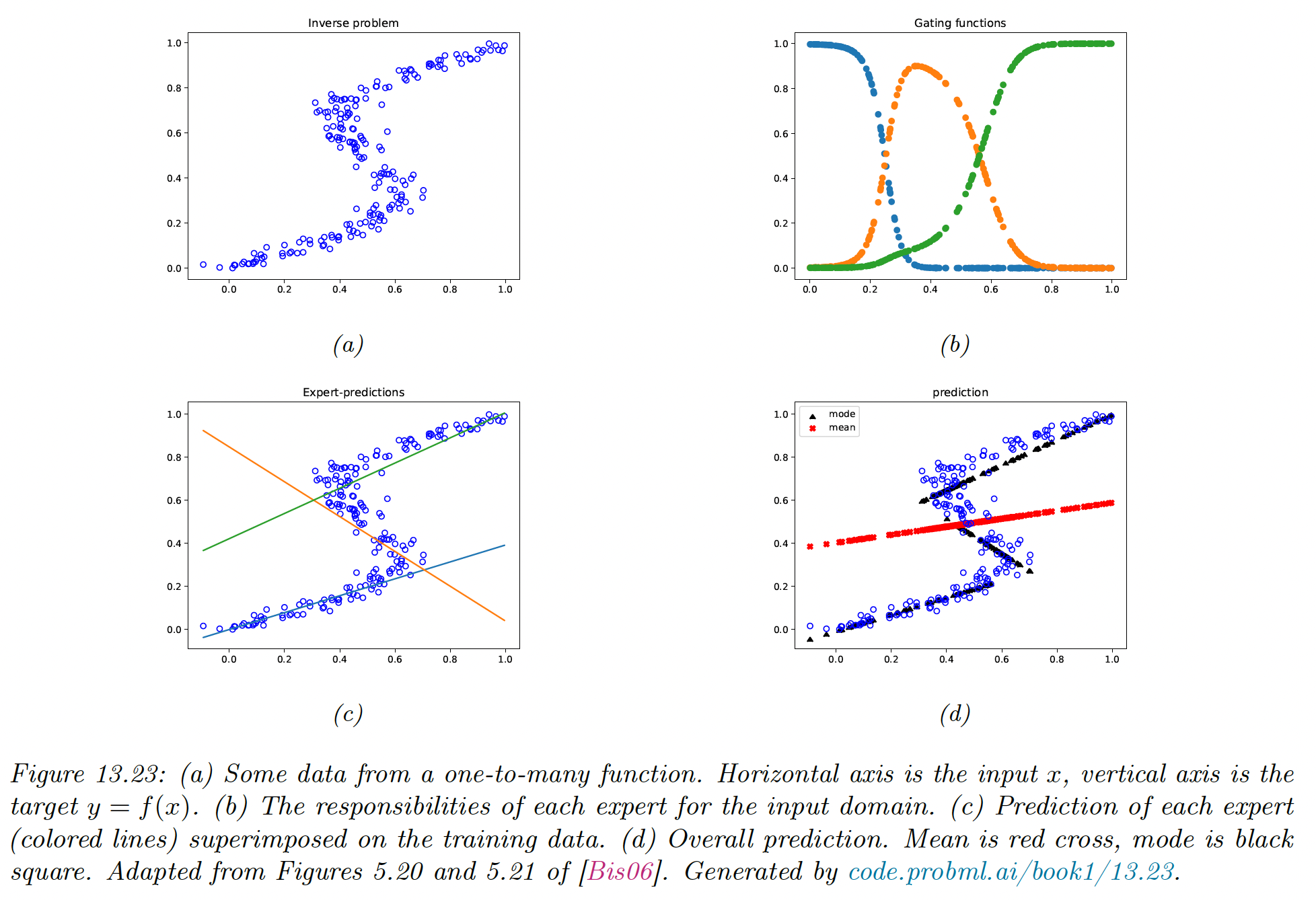
There are many real-world problems like 3d pose estimation of a person given an image, colorization of a black and white image (opens in a new tab), and predicting future frames of a video sequence.
Any model trained to maximize likelihood using a unimodal output density (even non-linear and flexible ones) will have poor performances on one-to-many functions since it will produce a blurry average output.
To prevent this problem of regression to the mean, we can use a conditional mixture model. We assume the output is a weighted mixture of different outputs, corresponding to different modes of the output distribution for each input .
In the Gaussian case, this becomes:
where:
Here, predicts which mixture to use, and predict the mean and the variance of the kth Gaussian.
This is called a Mixture of Expert (MOE), where we choose submodels that are experts on some region of the input space, with a gating function .
By picking the most likely model expert for a given , we can activate a subset of the model. This is an example of conditional computation.
13.6.2.1 Mixture of linear experts
The model becomes:
where is the kth output from the softmax. Each expert corresponds to a linear regression with different parameters.
As we can see in the figure above, if we take the average prediction from all experts, we obtain the red curve, which fits our data poorly. Instead, we only predict using the most active expert to obtain the discontinuous black curve.
13.6.2.2 Mixture density networks
The gating and expert functions can be any kind of conditional probabilistic model, like DNN. In this situation, the model becomes a mixture density network (MDN).
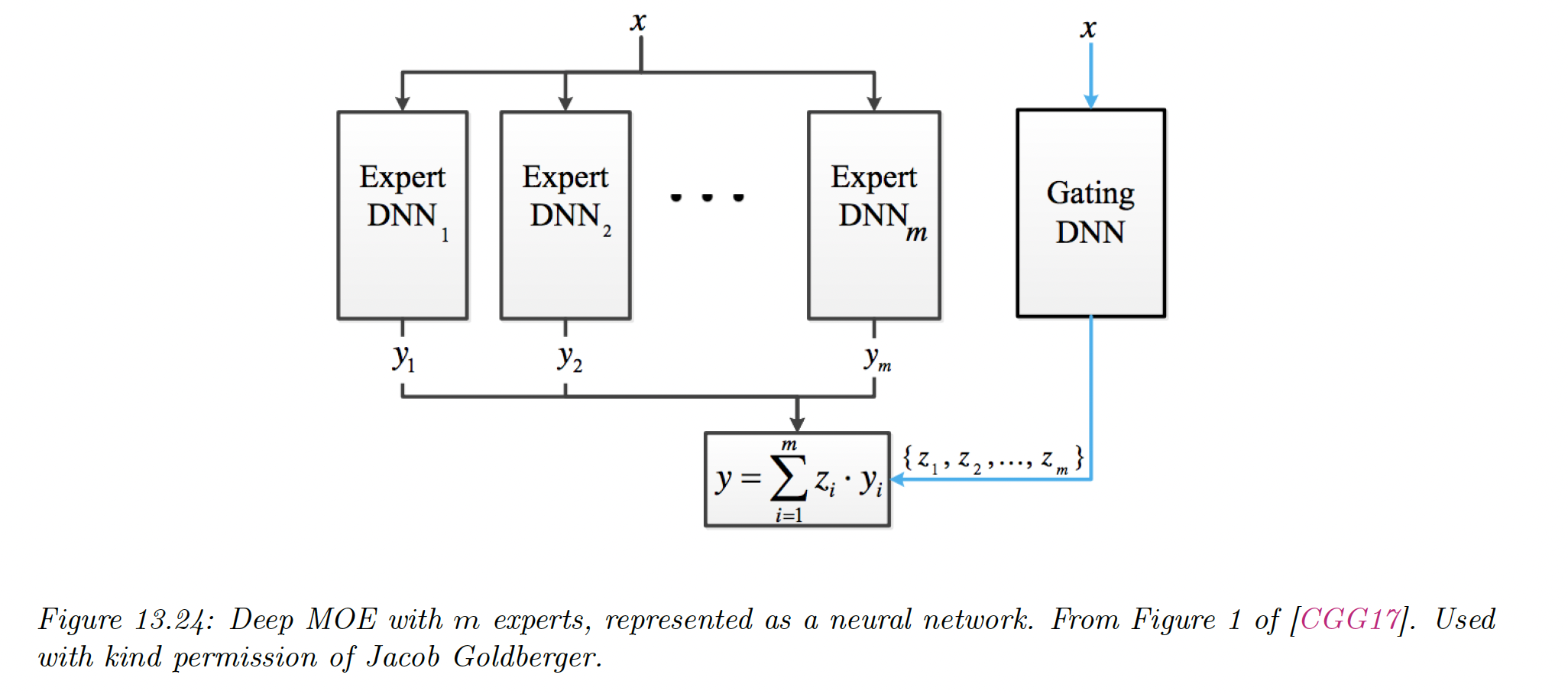
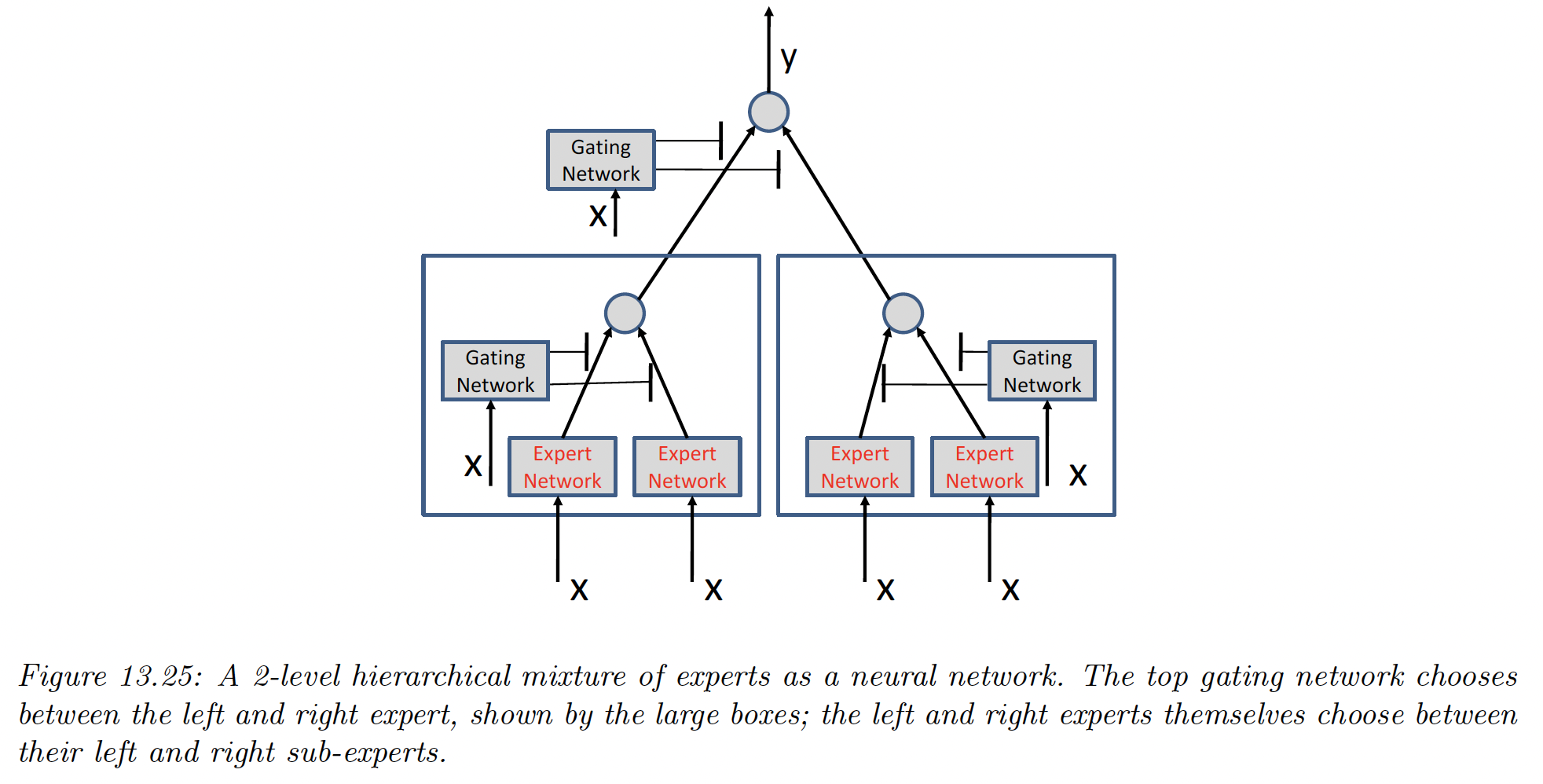
13.6.2.3 Hierarchical MOEs
If each network is a MOE itself, we obtain a hierarchical mixture of experts.
An HME with levels can be thought of as a “soft” decision tree of depth , where each example is passed through every branch of the tree, and the final prediction is the weighted average.