11.6 Robust linear regression
It is common to model the noise in linear regression with a Gaussian distribution , where . In this case, maximizing the likelihood is equivalent to minimizing the sum of squared residuals.
However, if we have outliers in our data, this can result in a bad fit because squared error penalizes deviations quadratically, so points far from the mean have more effect.
One way to achieve robustness is to use a likelihood with a heavy tail, assigning a higher likelihood to outliers without perturbing the straight line to explain them.
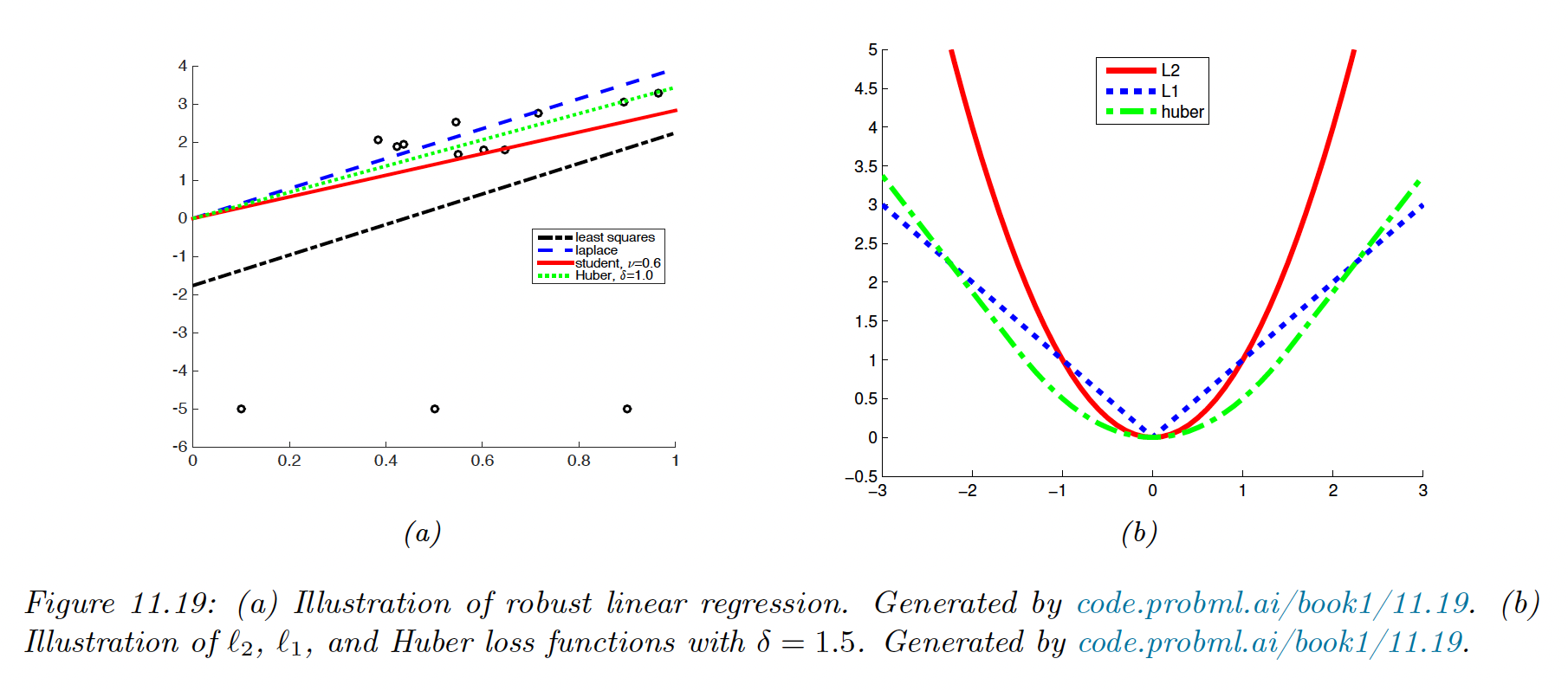
We discuss several alternative probability distributions for the response variable.
11.6.1. Laplace Likelihood
If we use the Laplace distribution as our likelihood, we have:
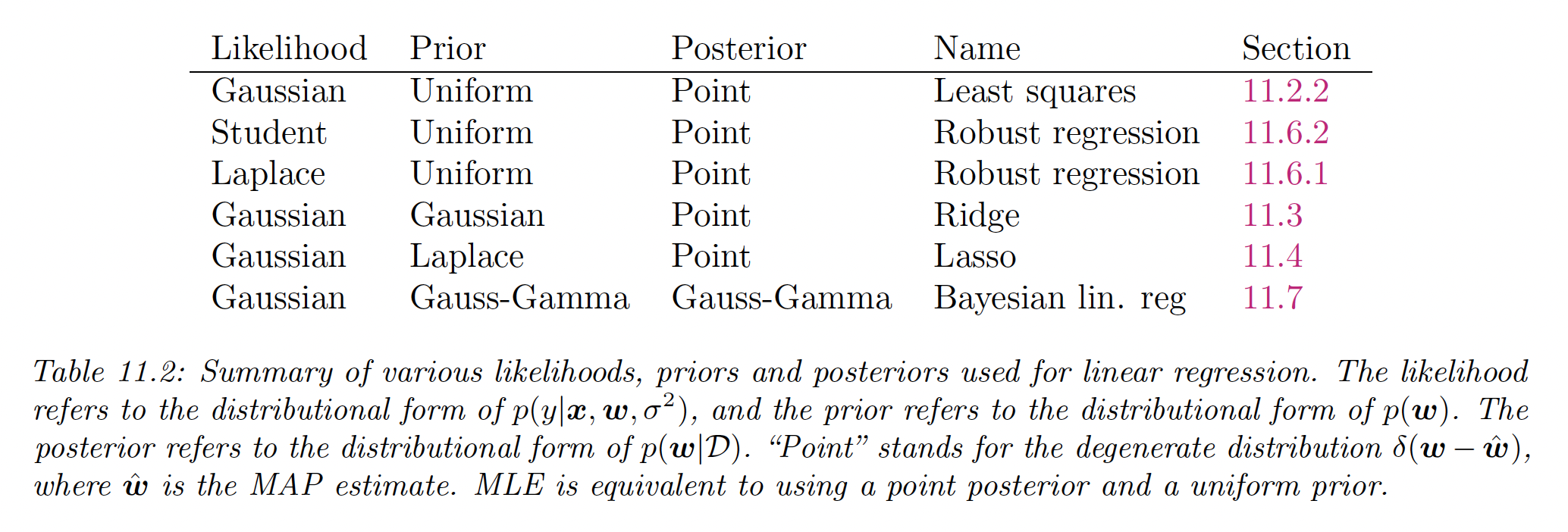
The robustness arises from the replacement of the squared term by an absolute one.
11.6.1.1 Computing the MLE using linear programming
Linear programming solves equations of the form:
where , and is the set of linear constraints we must satisfy.
Let us define , where .
We want to minimize the sum of residuals, so we define .
We need to enforce , but it is sufficient to enforce , which we can encode as two linear constraints:
which we can rewrite as:
where the first entries are filled with .
We can write these constraints in the form , with:
11.6.2 Student-t likelihood
To use the Student distribution in a regression context, we can make the mean a linear function of the inputs:
where we use the location-scale t-distribution pdf:
We can fit this model using SGD or EM.
11.6.3 Huber loss
An alternative to minimize the NLL using Laplace or Student distribution is using the Huber loss:
This is the equivalent of using the loss for errors smaller than and the loss for larger errors.
This is differentiable everywhere, consequently using it is much faster than using the Laplace likelihood, since we can use standard smooth optimization methods (like SGD) instead of linear programming.
The parameter controls the degree of robustness and is usually set by cross-validation.
11.6.4 RANSAC
In the computer vision community, a common approach to regression is to use random sample consensus (RANSAC).
We sample a small set of points, fit the model to them, identify outliers (based on large residuals), remove them, and refit the model on inliers.
We repeat this procedure for many iterations before picking the best model.
A deterministic alternative to RANSAC is fitting the model on all points to compute , then iteratively remove the outliers and refit the model with remaining inliers to compute .
Even though this hard thresholding makes the problem non-convex, this usually rapidly converges to the optimal estimate.