14.1 Introduction
This chapter considers the case of data with a 2d spatial structure.
To see why MLP isn’t a good fit for this problem, recall that the th element of a hidden layer has value . We compare to a learned pattern , and the resulting activation is high if the pattern is present.
However, this doesn’t work well:
- If the image has a variable dimension , where is the width, is the height and is the number of channels (e.g. 3 if the image is RGB).
- Even if the image is of fixed dimension, learning a weight of parameters (where is the number of hidden units) would be prohibitive.
- A pattern occurring in one location may not be recognized in another location. The MLP doesn’t exhibit translation invariance, because the weights are not shared across locations.
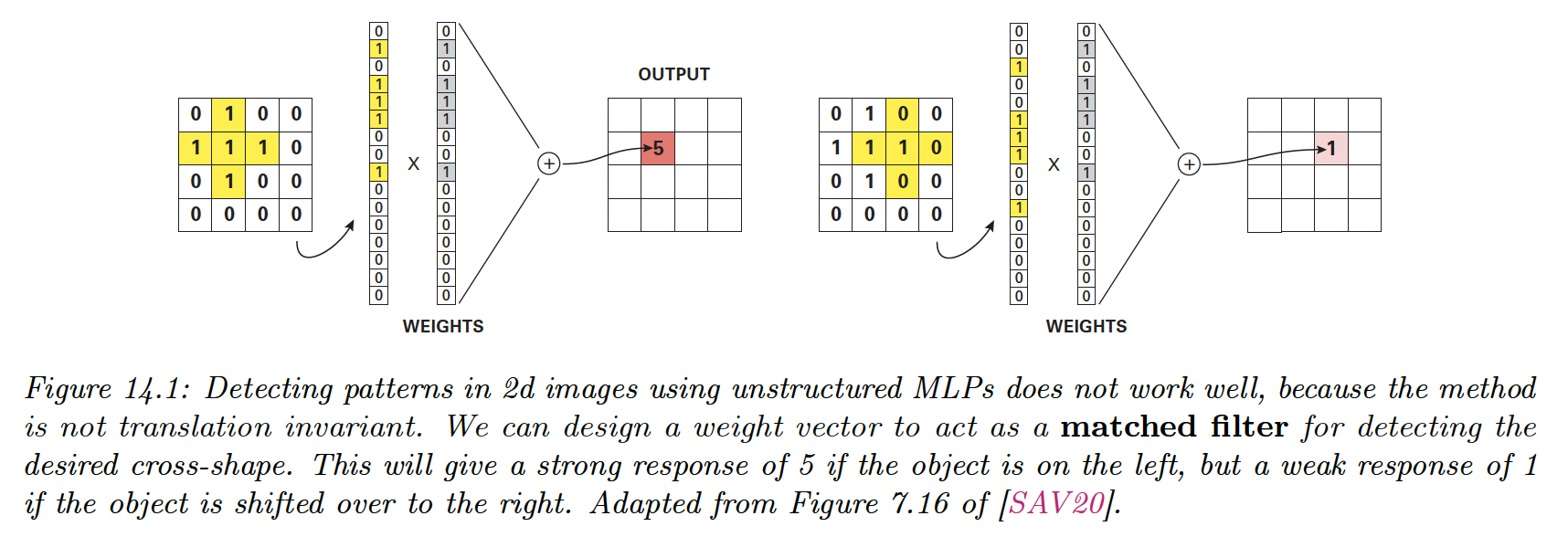
To solve these problems, we use convolutional neural nets (CNN), which replace matrix multiplications with convolutions.
The basic idea is to chunk the image into overlapping patches and compare its patch with a set of small weight matrices or filters that represent parts of an object.
Because the matrices’ weights are small (usually or ), the number of learned parameters is considerably reduced.
And because we use convolution to perform template matching, the model will be translationally invariant.