13.3 Backpropagation
In this section, we’ll cover the famous backpropagation algorithm which can be used to compute the gradient of a loss function applied to the output of the network w.r.t to the parameters in each layer.
13.3.1 Forward vs reverse mode differentiation
Consider a mapping of the form , where and
We can compute the Jacobian using the chain rule:
Recall that the Jacobian can be written as:
means the output is a scalar.
If (i.e. the number of features in the input is smaller than the dimension of the output), it is more efficient to compute the Jacobian for each column of using a Jacobian vector product (JVP), in a right to left manner:
This can be computed using forward mode differentiation. Assuming and , the cost of computation is .

If (this is the most frequent scenario, e.g. if the output is a scalar), it is more efficient to compute the Jacobian for each row using a vector Jacobian product (VJP), in a left to right manner:
This can be done using reverse mode differentiation. Assuming and , the cost of computation is .

Both algorithms 5 and 6 can be adapted to compute JVPs and VJPs of any collection of input vectors by accepting or as input.
Initializing these vectors to the standard basis is only useful to produce the complete Jacobian as output.
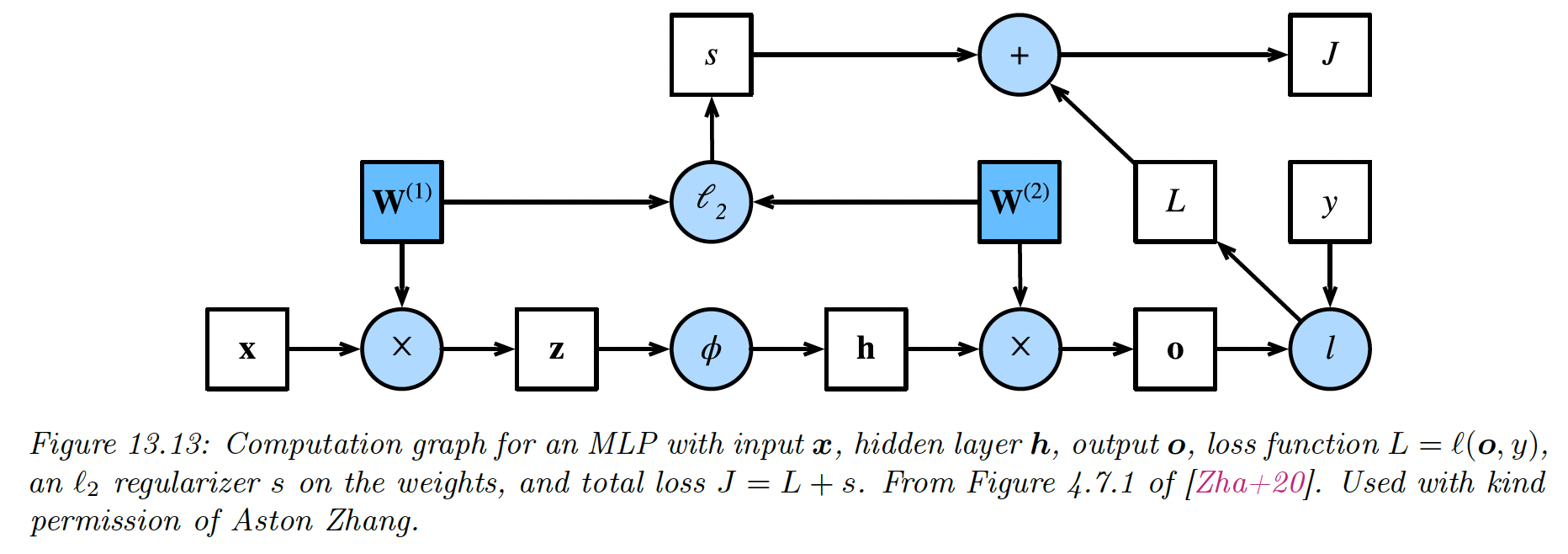
13.3.2 Reverse mode differentiation for MLP
Let’s now consider layers with learnable parameters. We consider the example of a scalar output, so that the mapping has the form .
For example, consider a loss for a MLP with one hidden layer:
We can represent this as the following feedforward model:
with:
We can compute the gradient wrt the parameters in each layer using the chain rule:
where each is a -dimensional gradient row vector, being the number of parameters of the layer .
Each Jacobian is an matrix and can be computed recursively:

We now have to define the VJP of each layer.
13.3.3 VJP of common layers
13.3.3.1 Cross entropy layer
where is the predicted probability for class :
and is the true label for class .
The Jacobian is:
13.3.3.2 Element wise non-linearity
Since it is element wise, we have
The element of the Jacobian is given by:
In other words, the Jacobian wrt the input is:
The VJP becomes
For example, if , we have:
The subderivative at 0 is any value in , but we often take .
13.3.3.3 Linear layer
where
i) The Jacobian wrt the input is:
since:
Then the VJP is:
ii) The Jacobian wrt the parameters is:
which is complex to deal with.
Instead, taking a single weight:
Hence:
where occurs on the th location.
Therefore we have:
So the VJP can be represented by a matrix:
13.3.3.4 Putting all together
And
13.3.4 Computation Graph
MLP are simple kind of DNN with only feed forward passes. More complex structures can be seen as DAGs or computation graphs of differentiable elements.
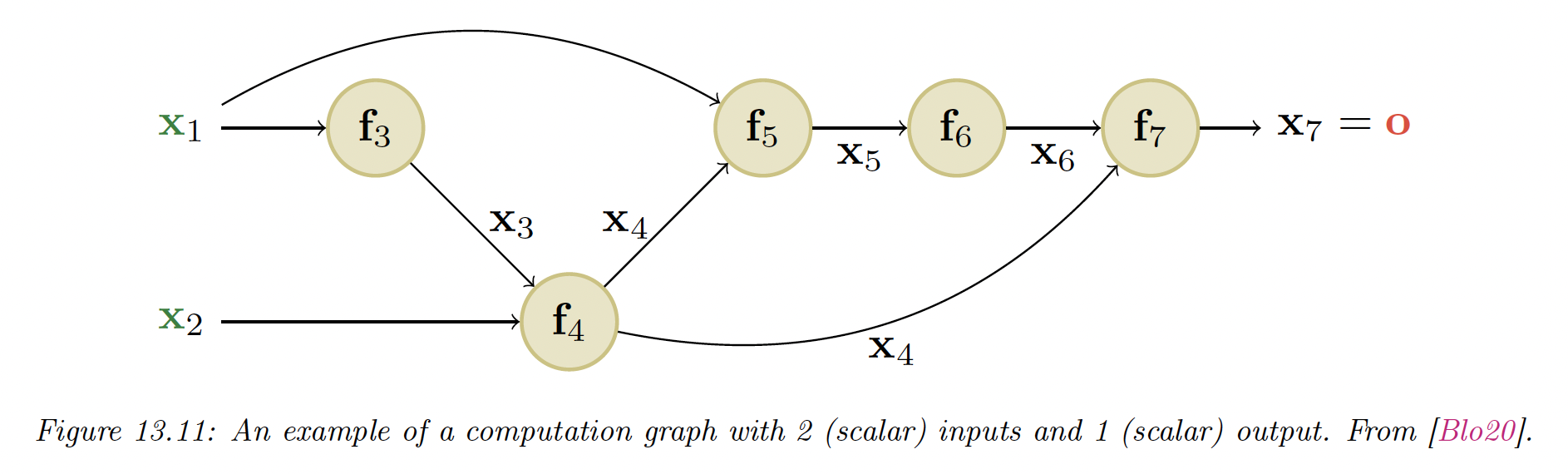
For example, here we have:
The is computed once for each child , this quantity is called the adjoint. This then gets multiplied by the Jacobian of each child.
The graph can be computed ahead of time, by using a static graph (this is how Tensorflow 1 worked), or it can be computed just in time by tracing the execution of the function on a input argument (this is how Tensorflow eager mode, Jax, and PyTorch works).
The later approach makes it easier to work on a dynamic graph, where the paths can change wrt the inputs.