19.6 Few-shot learning
People can learn to predict from very few labeled example. This is called few-shot learning (FSL).
In the extreme where we only have one labeled example of each class, this is one-shot learning, and if no label are given, this is called zero-shot learning.
A common way to evaluate methods for FSL is to use -way, -shot classification, in which we expect the system to learn to classify classes from labeled examples for each class.
Typically, and are very small.

Since the amount of labeled data per domain is so scarce, we can’t expect to learn from scratch. Therefore, we turn to meta-learning.
During training, a meta-algorithm trains on a labeled support set from group and returns a predictor , which is then evaluated on a disjoint query set also from group .
We optimize over the groups. Finally, we can apply to our new labeled support set to get , which is then applied to the test query set.
We see on the image above that there is no overlap of classes between groups, therefore the model has to learn to predict classes in general rather than any specific set of labels.
We discuss some approach to FSL below.
19.6.1 Matching networks
On approach to FSL is to learn a distance metric on some other dataset, and then use inside a nearest-neighbor classifier.
Essentially, this defines a semi-parametric model of the form where is the small labeled dataset (known as the support set) and are the parameters of the distance function.
This approach is widely used for fine-grained classification tasks, where there are many different but visually similar categories, such as products in a catalogue.
An extension of this approach is to learn a function of the form:
where is some kind of adaptive similarity kernel.
For example, we can use an attention kernel of the form:
where is the cosine distance. and can be the same function.
Intuitively, the attention kernel compares to in the context of all the labeled example, which provides an implicit signal about which feature dimension are relevant. This is called matching network (opens in a new tab).
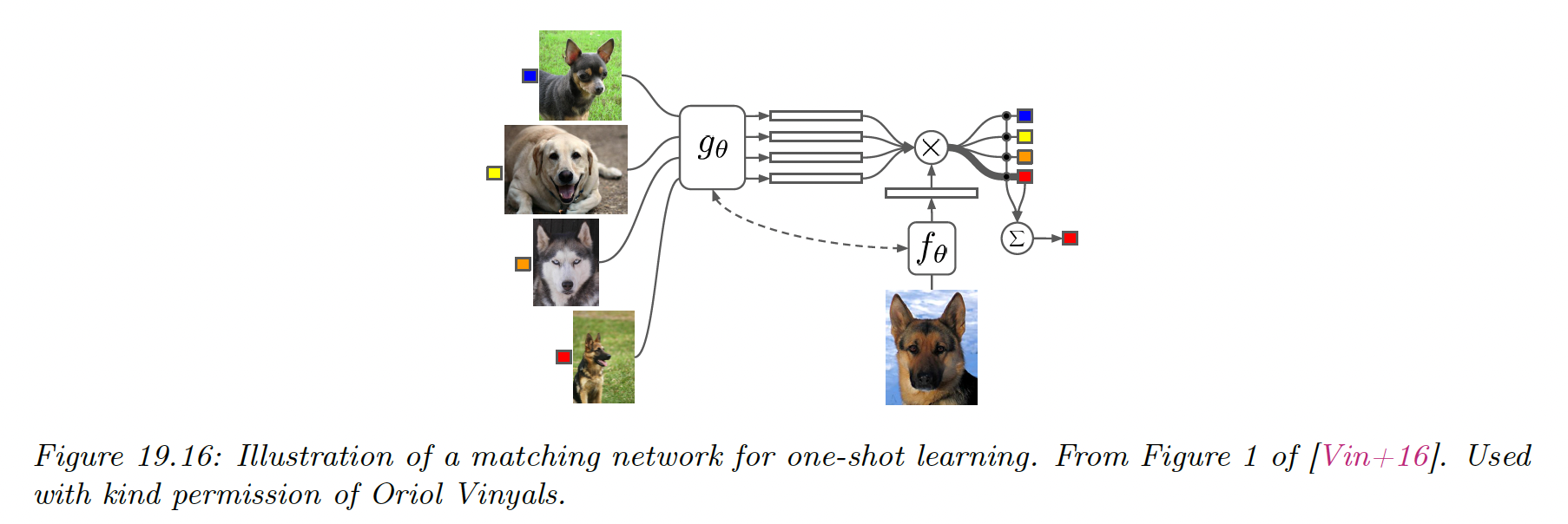
We can train and using multiple small datasets, as in meta-learning.
Let be a large labeled dataset (e.g. ImageNet), and let be its distributions of labels. We create a task by sampling a small number of labels (say 25) , and then sample a small support set of examples from with those labels and finally sampling a small test set with those same labels .
We then train the model to optimize the objective:
After training we freeze and predict on a test support set .