8.1 Intro
Optimization is at the core of machine learning: we try to find the values of a set of variable that minimizes a scalar-valued loss function :
with the parameter space .
An algorithm minimizing this loss function is called a solver.
8.1.1 Local vs Global Optimization
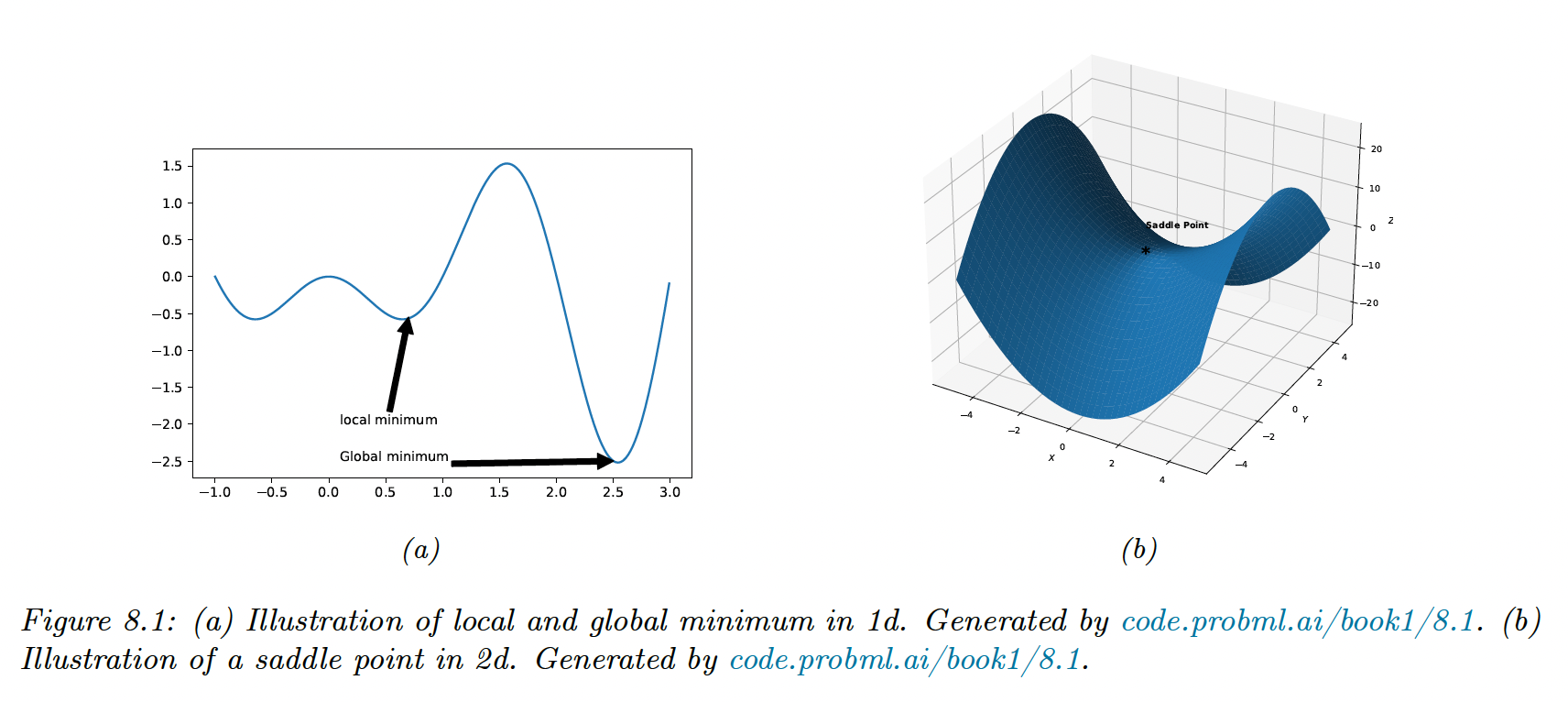
The global optimum is the point that satisfies the general equation, but finding it is computationally intractable.
Instead, we will try to find a local minimum. We say that is a local minimum if:
A local minimum can be flat (multiple points of equal objective value) or strict.
A globally convergent algorithm will converge to a stationary point, although that point doesn’t have to be the global optimum.
Let and hessian matrix.
- Necessary condition: is a local minimum and is positive semi-definite
- Sufficient condition: and positive definite is a local minimum
The condition on is necessary to avoid saddle points —in this case, the eigenvalues of the Hessian will be both positive and negative, hence non-positive definite.
8.1.2 Constrained vs Unconstrained Optimization
In unconstrained optimization, we minimize the loss with any value in the parameter space .
We can represent inequality constraints as for and equality constraints as for
The feasible set is then:
And the constraint optimization problem becomes:
Adding constraints can create new minima or maxima until the feasible set becomes empty.

A common strategy for solving constrained optimization is to combine penalty terms, measuring how much we violated the constraints, with the unconstrained objective. The Lagrangian is a special case of this combined objective.
8.1.3 Convex vs Nonconvex Optimization
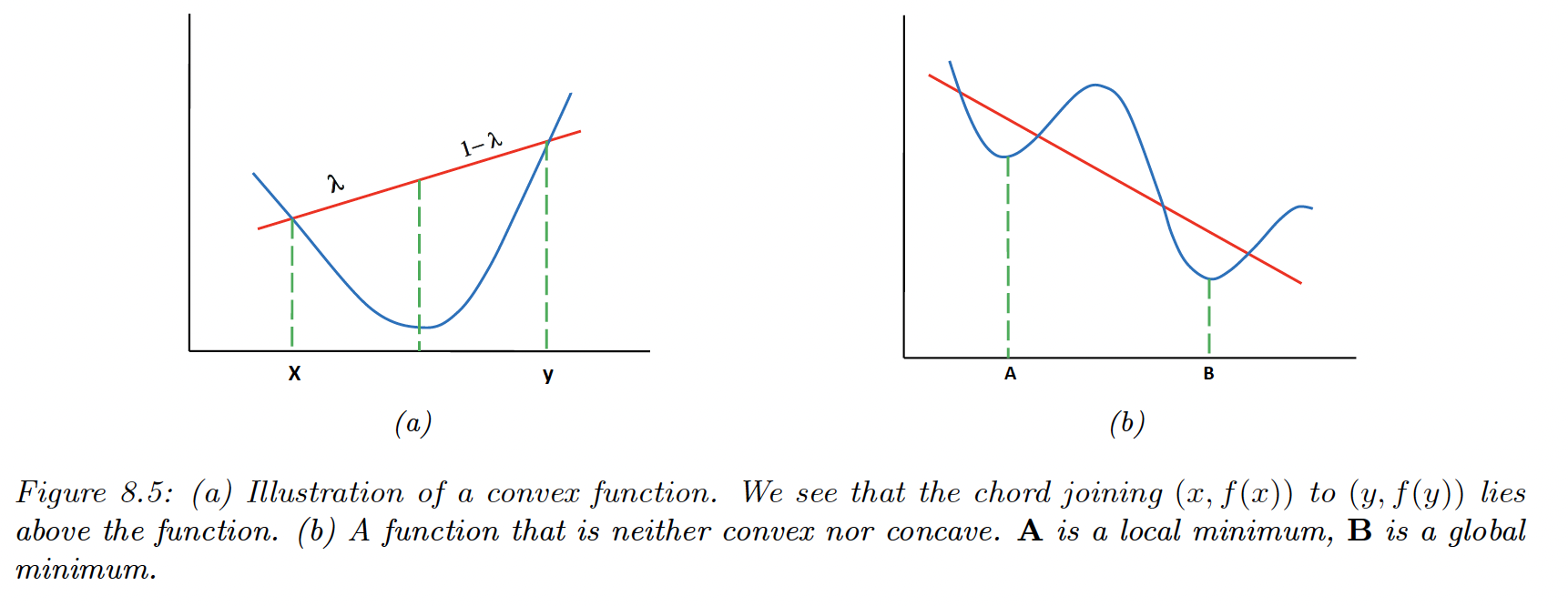
In convex optimization, every local minimum is a global minimum, therefore many machine learning models are designed so that their training objective is convex.
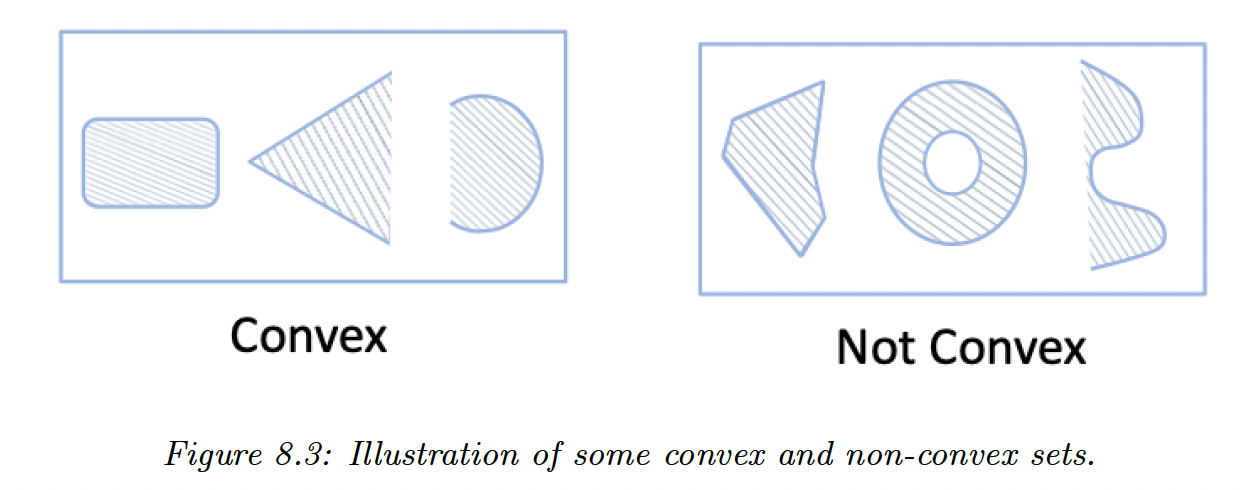
is a convex set if for any and we have:
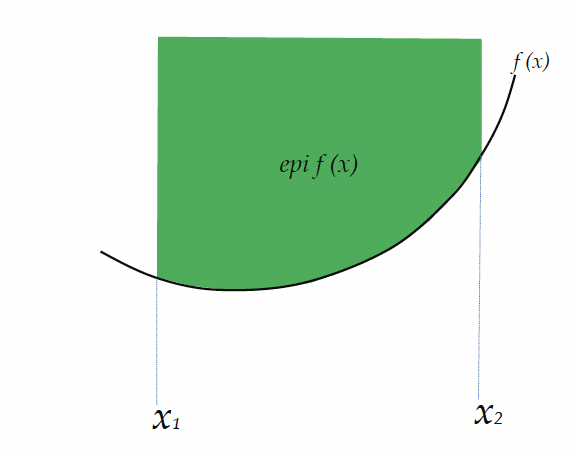
We say is a convex function if its epigraph (the set of points above the function) defines a convex set.
Equivalently, is convex if it is defined on a convex set, and for any and :
is concave if is convex.
Suppose is twice differentiable, then:
-
is convex iff is positive semi definite.
-
is strictly convex iff is positive definite
For example, let’s consider the quadratic form . It is convex if is positive definite.

Furthermore, is strongly convex with parameter if for any in its subspace:
If is twice differentiable, then it is strongly convex with parameter iff —meaning is positive definite.
In the real line domain, this condition becomes .
In conclusion:
- is convex iff
- is strictly convex if
- is strongly convex with parameter iff
8.1.4 Smooth vs Non-smooth Optimization
In smooth optimization, the objective function is continuously differentiable, and we quantify the smoothness using the Lipschitz constant. In the 1d case:
The function output can’t change by more than if we change the input by unit.
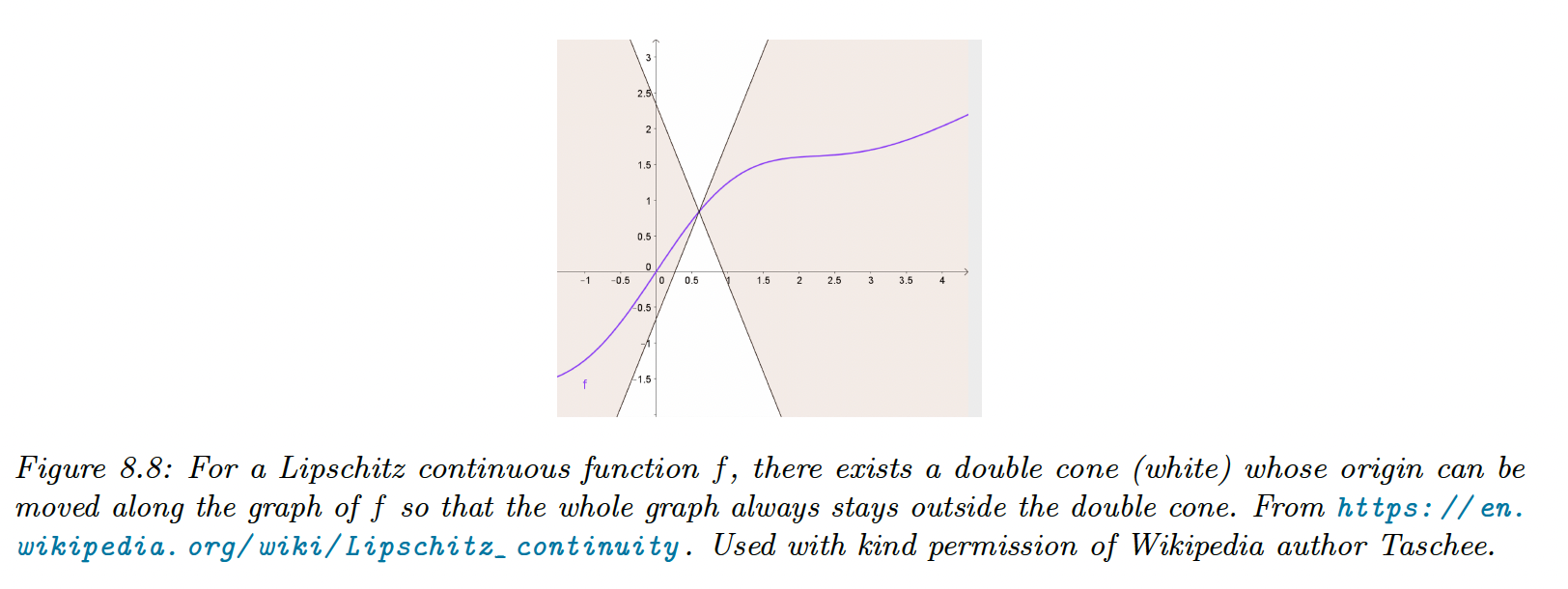
Non-smooth functions have at least some functions in the gradient that are not defined:
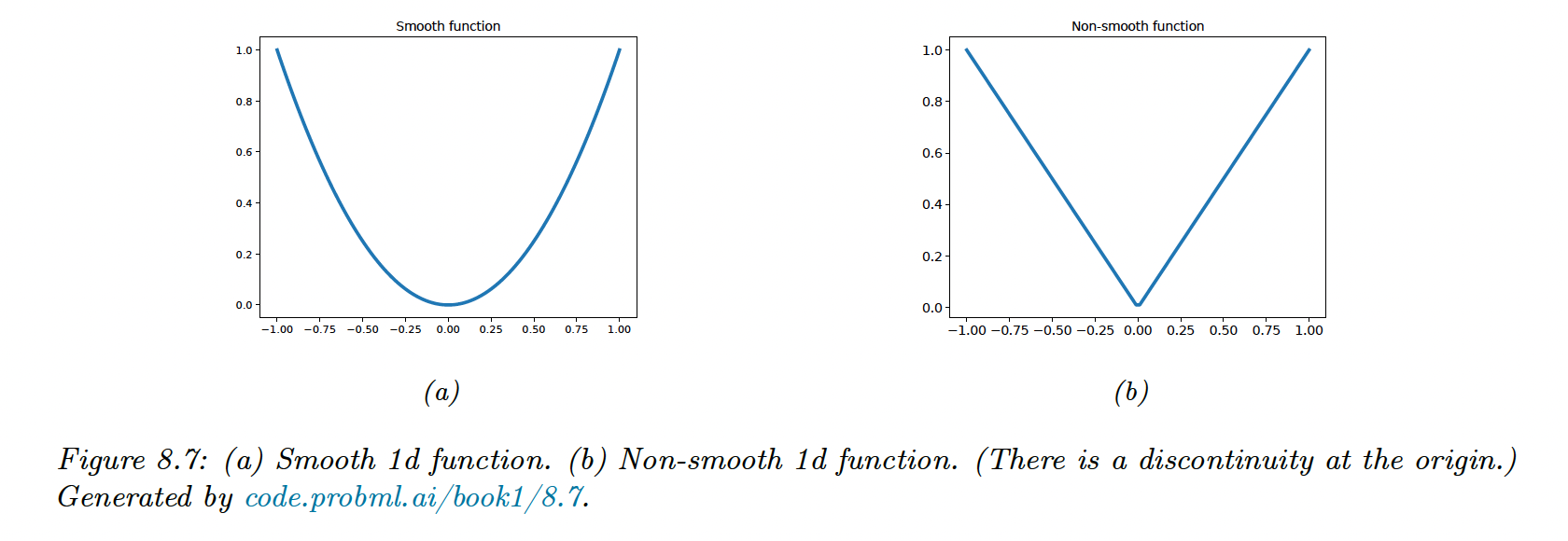
In some problems we can partition the objective into a part containing only smooth terms and a part with nonsmooth (rough) terms:
In machine learning, these composite objectives are often formed with the training loss and a regularizer such as the norm of .
8.1.4.1 Subgradients
We generalize the notion of derivative to function with local discontinuities.
For , is the subgradient of at :
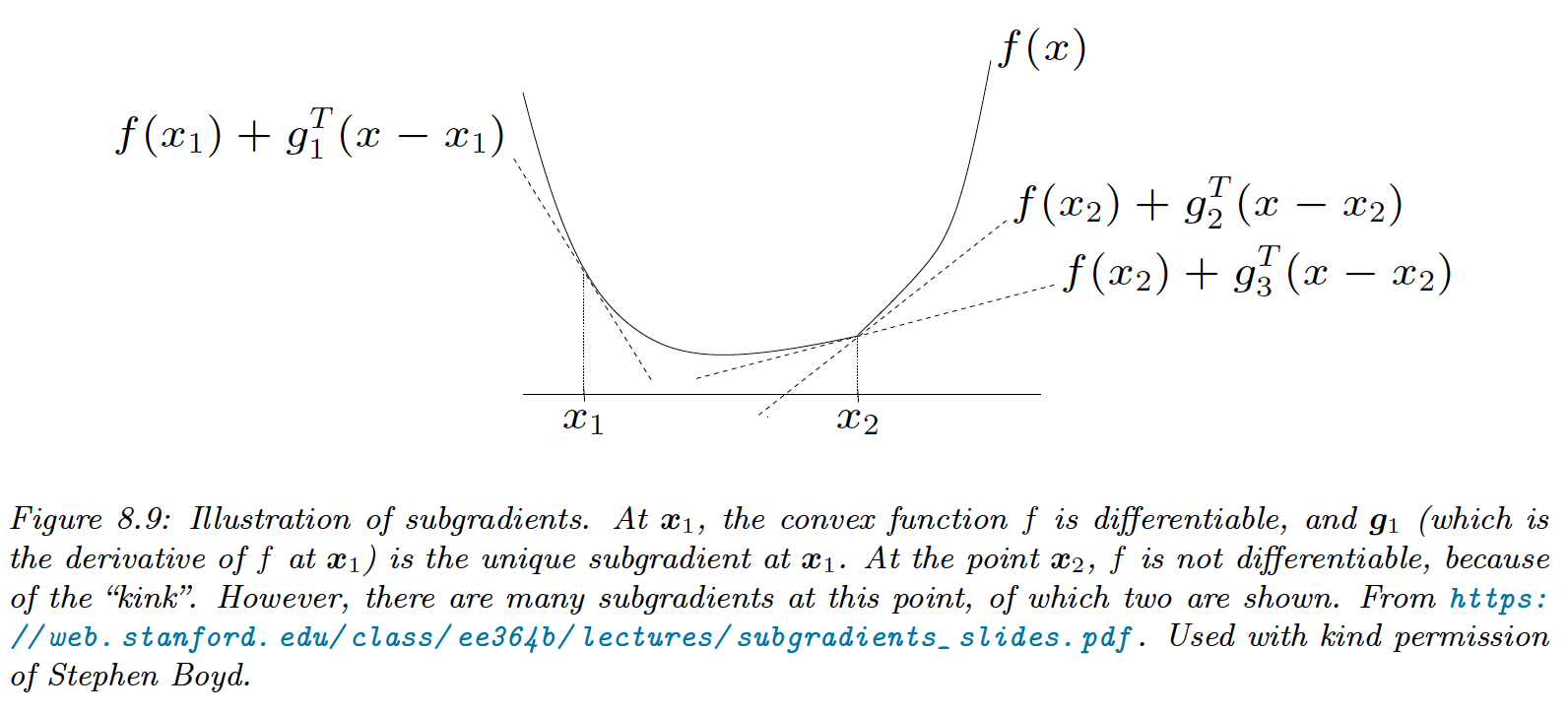
For example, the subdifferential of is:
