21.2 Hierarchical agglomerative clustering (HAC)
Hierarchical agglomerative clustering is a common form of clustering.
The input to the algorithm is an dissimilarity matrix and the output is a tree structure in which groups and with small dissimilarity are grouped together in a hierarchical fashion.
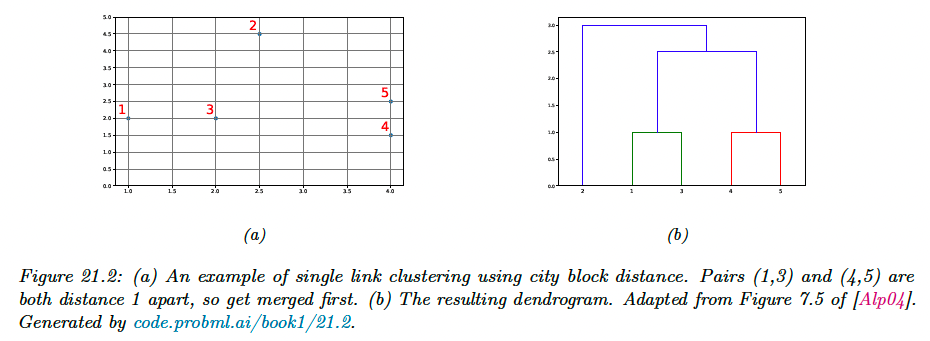
We will use city block distance to define the dissimilarity:
21.2.1 The algorithm
Agglomerative clustering starts with groups, each initially containing one object, and then at each step it merges the two most similar groups until there is a single group containing all the data.
The result is a binary tree known as dendogram. By cutting the tree at different heights, we can induce a different number of (nested) clusters.

Since picking the two most similar groups takes and there are steps in the algorithm, the total running time is .
However, by using a priority queue, this can be reduced to .
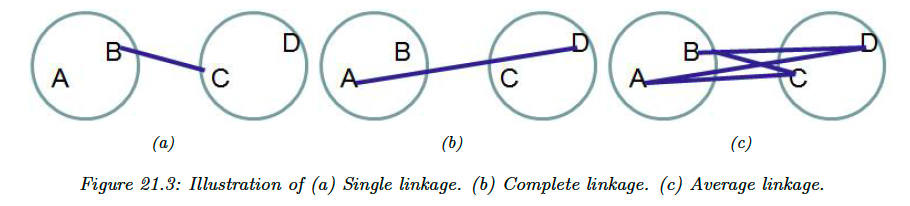
There are three variants of agglomerative clustering, depending on how we define the dissimilarity between groups of objects.
21.2.1.1 Single link
In single link clustering, also called nearest neighbor clustering, the distance between two groups and is defined as the distance between the closest members of each groups:
The tree built using single link clustering is a minimum spanning tree of the data, connecting all objects in a way that minimize the sum of the edge weights (distance).
As a consequence of this, we can implement single link clustering in time, whereas the naive form of other variants take time.
21.2.1.2 Complete link
In complete link clustering, aka furthest neighbor clustering, the distance between two groups is defined as the distance between the two most distant pairs:
Single linkage only requires that a single pairs of object to be close for the two groups to be considered a cluster, regardless of the similarity of other members of the group.
Thus, clusters can be formed that violate the compactness property, which says that all observations within a group should be similar to each other.
If we define the diameter of a group as the largest dissimilarity of its members, then we can see that the single link can produce clusters with large diameters.
Complete linkage represents the opposite extreme: two groups are considered close if all of the observations in their union are relatively similar. This tends to produce compact clusterings, with small diameters.
In scipy, this is implemented using nearest neighbor chain, and takes time.
21.2.1.3 Average link
In practice, the preferred method is average link clustering, which measures the average distance between all pairs:
where and are the number of elements in each groups.
Average link clustering represent a compromise between single and complete link clustering. It tends to produce compact clusters that are relatively far apart.
However, since it involves averaging of the distances, any change to the measurement scale can change the result. In contrast, single linkage and complete linkage are invariant to monotonic transformations of , since they leave the relative ordering the same.
In scipy, this is also implemented using nearest neighbor chain, and takes time.
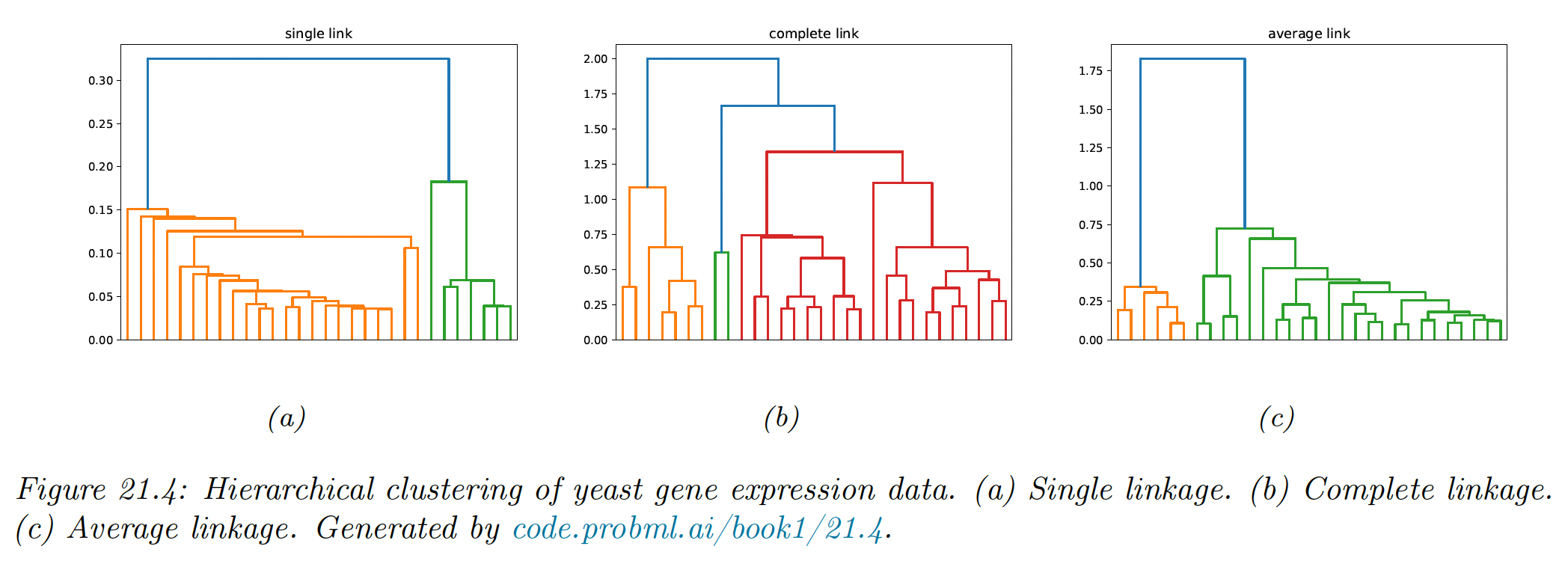
21.2.2 Example
Suppose we have a set of time series measurements of the expression levels for genes at points, in response to a given stimulus. Each data sample is a vector .
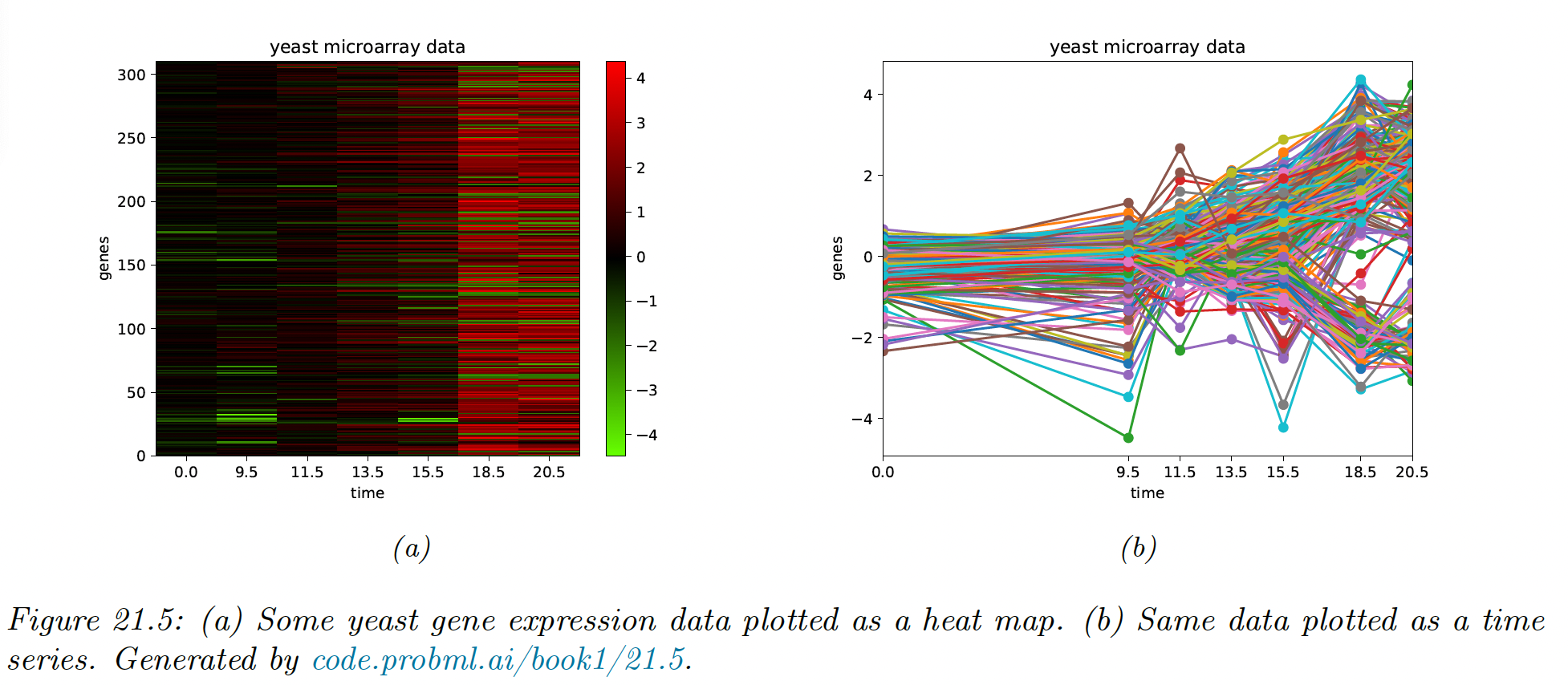
We see that there are several kind of genes, some goes up monotonically over time, some goes down, and some exhibit more complex response patterns.
Suppose we use Euclidean distance to compute a pairwise distance matrix , and apply HAC using average linkage. We get the following dendogram:
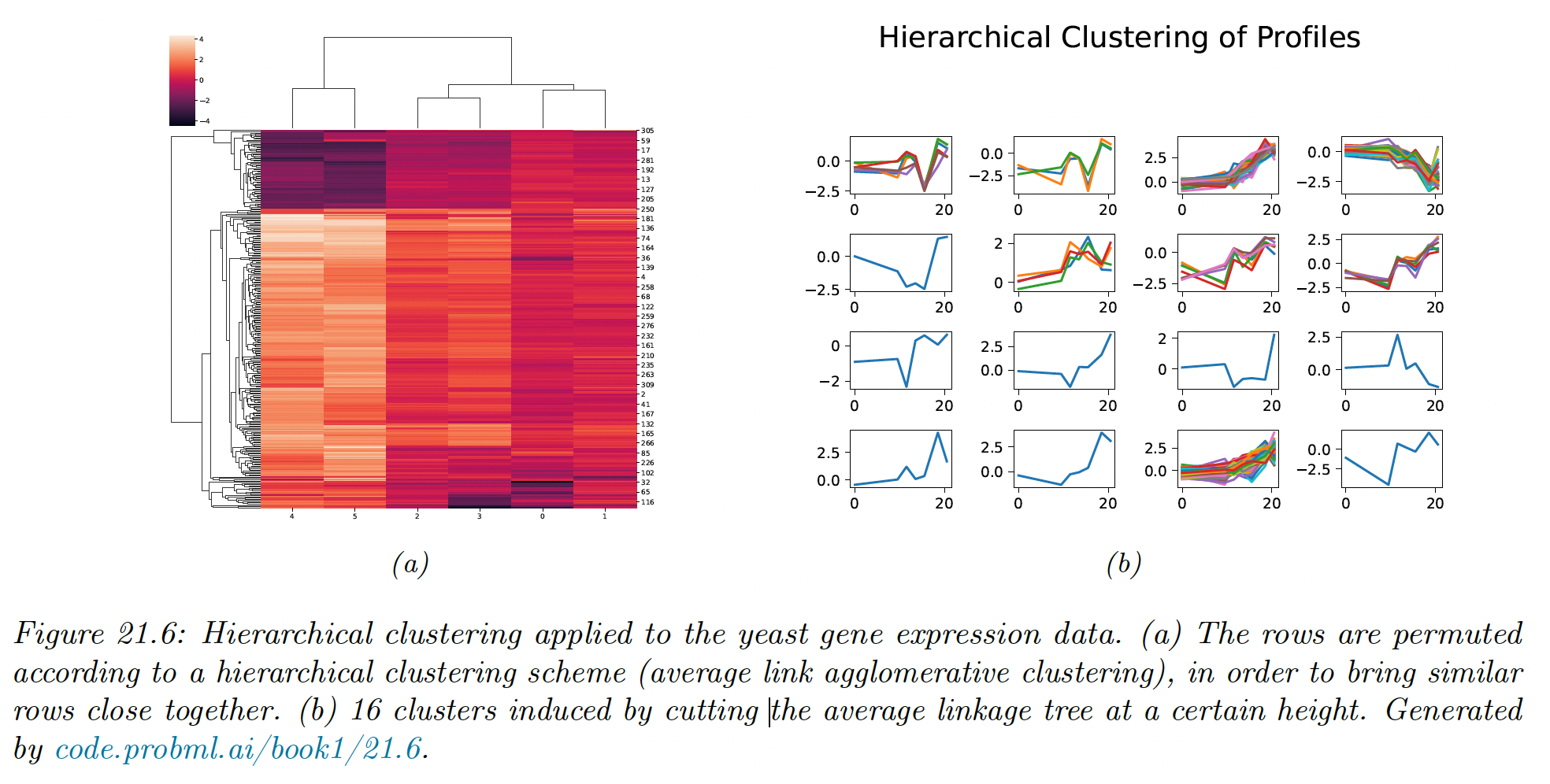
The time series assigned to each cluster of the cut do indeed “look like” each other.