8.2 First-Order Methods
First-order methods compute first-order derivatives of the objective function but they ignore the curvature information.
All these algorithms required the user to choose a starting point before iterating:
where is the learning rate and is the descent direction, such as the negative of the gradient .
These update steps are performed until reaching a stationary point.
8.2.2 Step size
The sequence of steps is the learning rate schedule. We describe some methods to pick this.
8.2.2.1 Constant step size
The simplest method is to consider . However, if set too large the method will fail to converge, and if set too small, the method will converge very slowly.
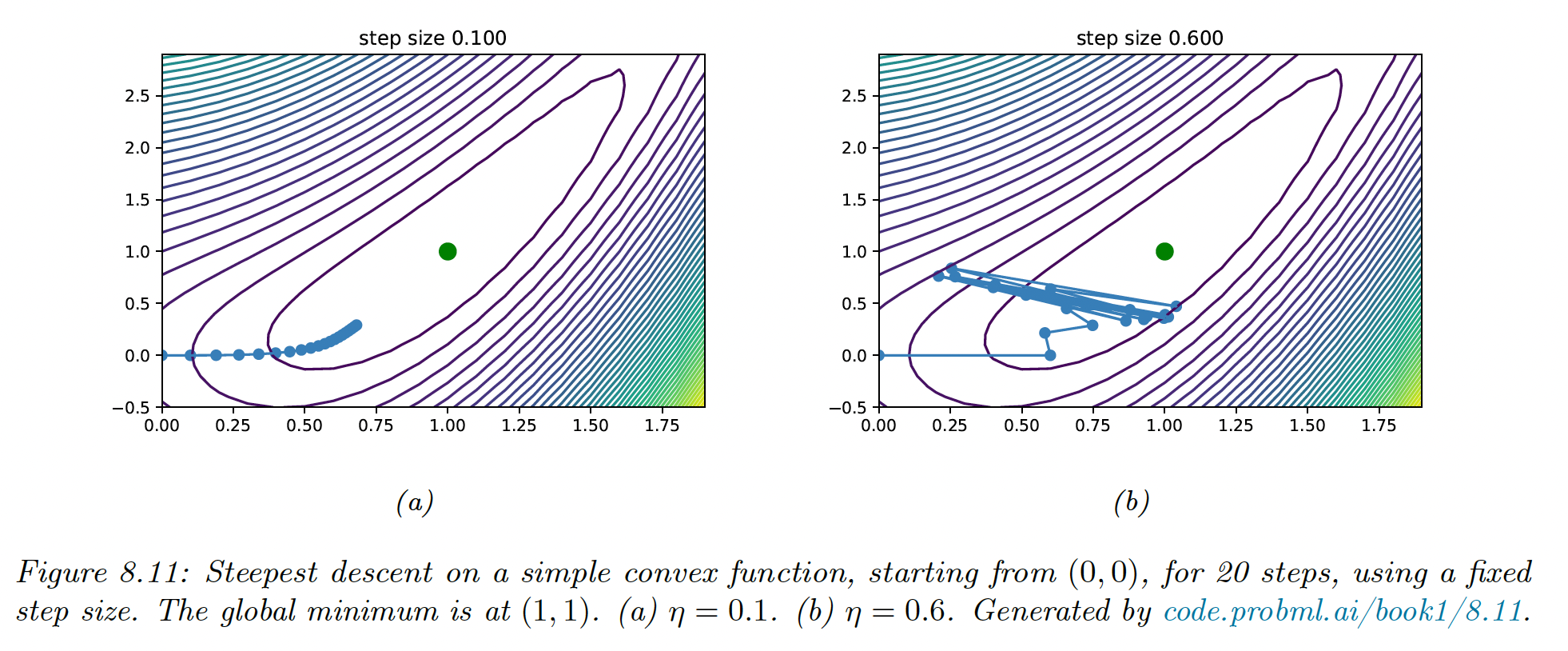
We can derive a theoretical upper bound for the step size. For a quadratic objective function:
with positive semi-definite, the steepest descent will converge iff the step size satisfies:
This ensures that the step is lower than the slope of the steepest direction, which the eigenvalue measures.
More generally:
where is the Lipschitz constant of the gradient —but this constant is usually unknown.
8.2.2.2 Line search
The optimal step size can be found by solving the optimization:
If the loss is convex, this subproblem is also convex because the update term is affine.
If we take the quadratic loss as an example, we solve:
and find:
However, it is often not necessary to be so precise; instead, we can start with the current step size and reduce it by a factor at each step until it satisfies the Armijo-Goldstein test:
where , typically .
8.2.3 Convergence rates
In some convex problems where the gradient is bounded by the Lipschitz constant, gradient descent converges at a linear rate:
where is the convergence rate.
For simple problems like the quadratic objective function, we can derive explicitly. If we use the steepest gradient descent with line search, the convergence rate is given by:
Intuitively, the condition problem represents the skewness of the space —i.e. being far from a symmetrical bowl.
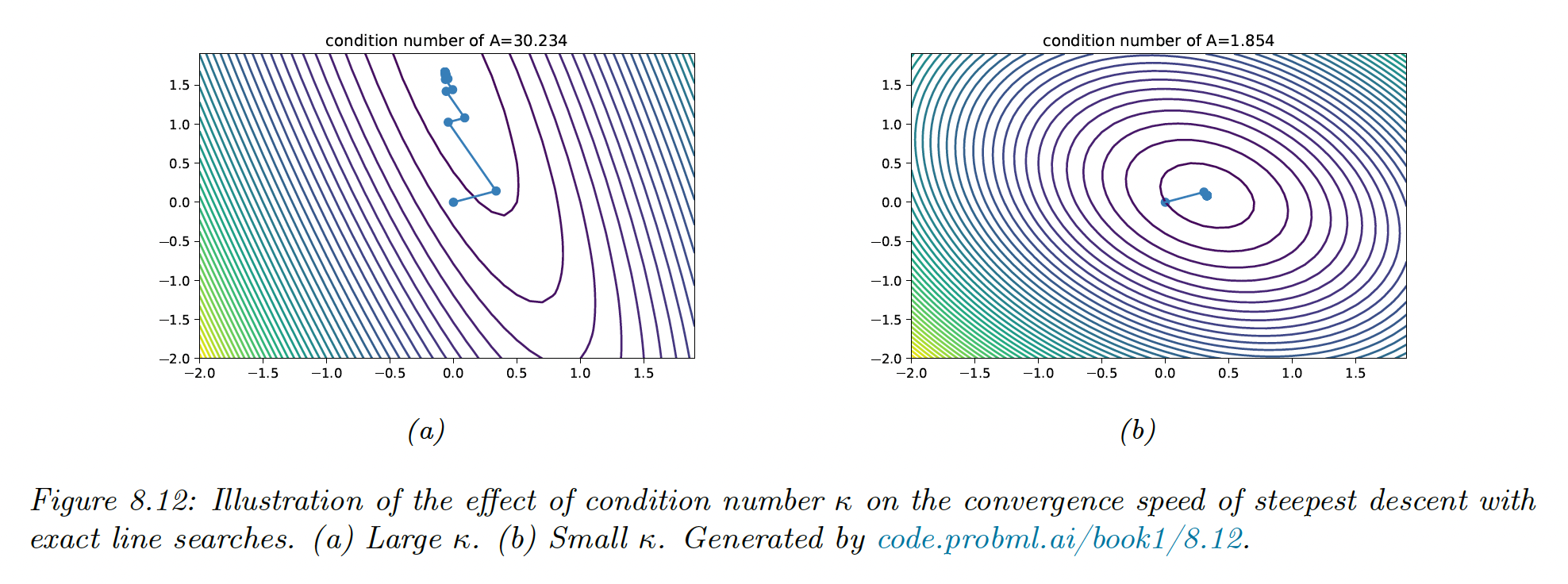
More generally, the objective around the optimum is locally quadratic, hence the convergence rate depends on the condition number of the Hessian at that point: . We can improve the speed of convergence by using a surrogate model that has a Hessian close to the Hessian of the objective.
Line search often exhibits zig-zag paths that are inefficient, instead, we can use conjugate gradient descent.
8.2.3.1 Conjugate gradient descent
are conjugate vectors w.r.t iff:
Let is a set of mutually conjugate vectors, i.e. for .
forms a basis for , and we can write:
The gradient of the quadratic objective function is:
thus we choose our first vector as:
and we will find other vectors as conjugates with the following update:
8.2.4 Momentum methods
8.2.4.1 Momentum
This can be implemented as follow:
with , usually .
Where the momentum plays the role of an exponentially weighted moving average of the gradient:
8.2.4.2 Nesterov momentum
The standard momentum issue is that it may not slow down enough at the bottom of the valley and causes oscillations.
To mitigate this, Nesterov accelerated gradient adds extrapolation steps to the gradient descent:
This can be rewritten in the same format as the momentum:
This method can be faster than standard momentum because it measures the gradient at the next location.
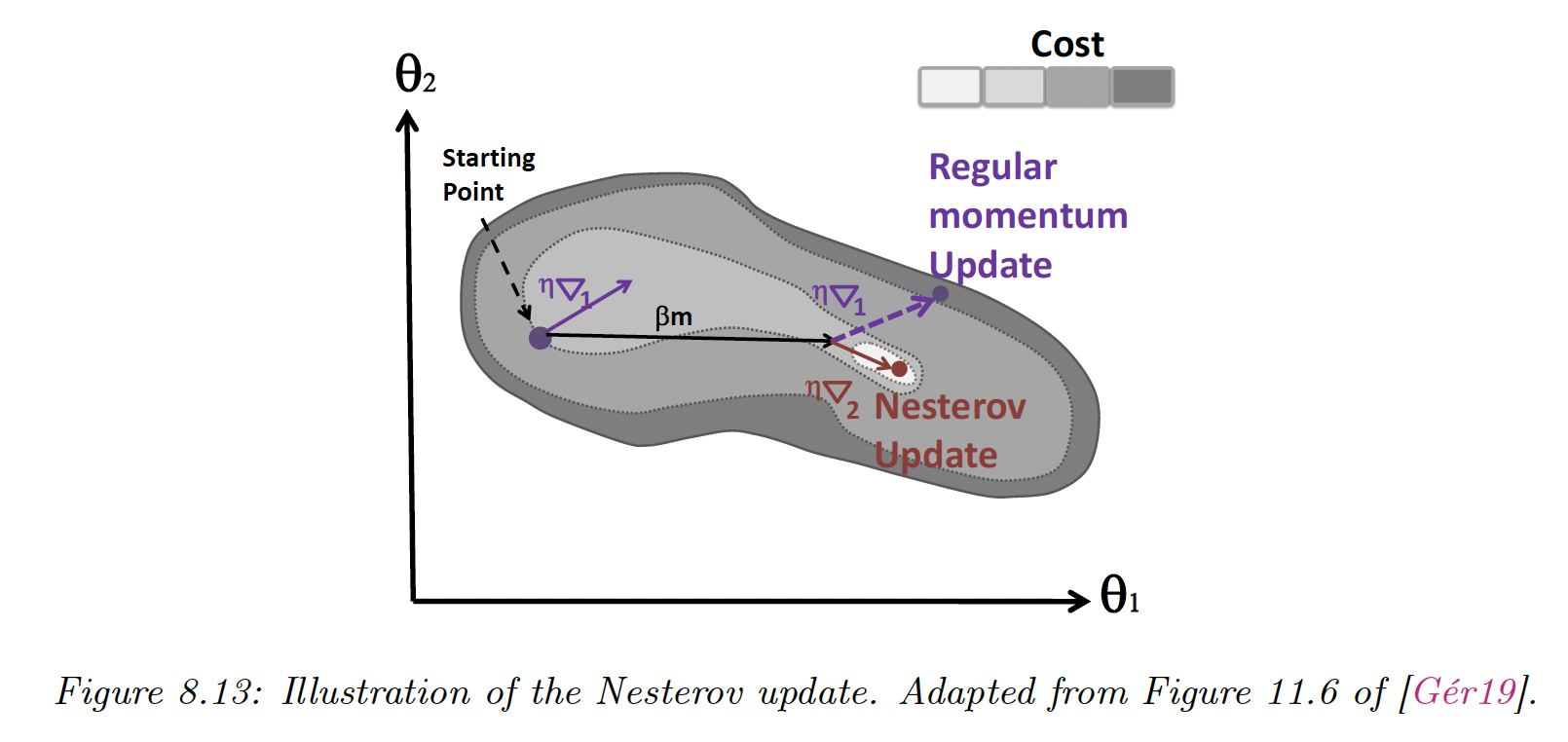
In practice, using the Nesterov momentum can be unstable if or are misspecified.