20.4 Manifold learning
We discuss the problem of recovering the underlying low-dimensional structure of a high-dimensional dataset. This structure is often assumed to be a curved manifold so this problem is called manifold learning or nonlinear dimensionality reduction.
The key difference from methods like AE is that we will focus on non-parametric methods, in which we compute an embedding for each point in the training set, as opposed to learning a generic model that can embed any input vector.
This is, the methods we discuss don’t (easily) support out-of-sample generalization. However, they can be easier to fit and are quite flexible.
Such methods can be useful for unsupervised learning, data visualization, and as a preprocessing step for supervised learning.
20.4.1 What are manifolds?
Roughly speaking, a manifold is a topological space that is locally Euclidean. One of the simplest examples is the surface of the earth, which is a curved 2d surface embedded in a 3d space. At each local point on the surface, the earth seems flat.
More formally, a -dimensional manifold is a space in which each point has a neighborhood which is topologically equivalent to a -dimensional Euclidean space, called the tangent space, denoted .
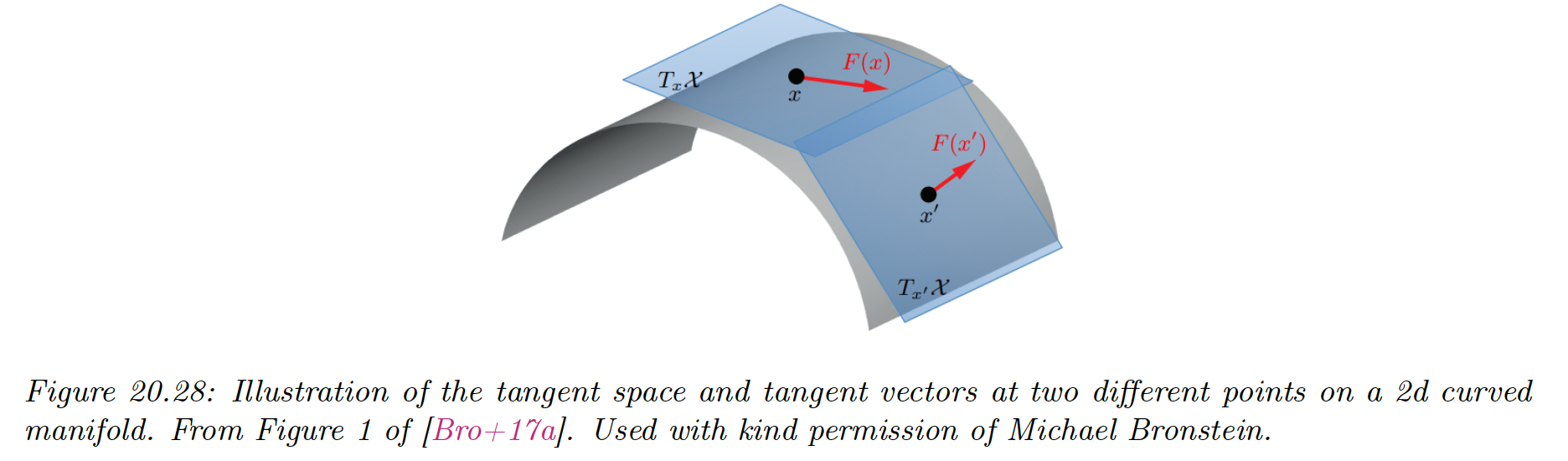
A Riemannian manifold is a differentiable manifold that associates an inner product operator at each in tangent space. This is assumed to depend smoothly on the position .
The collection of these inner product is called a Riemannian metric. It can be shown that any sufficiently smooth Riemannian manifold can be embedded in any Euclidean space of potentially higher dimension. The Riemannian inner product at a point becomes Euclidean inner product in the tangent space.
20.4.3 Approaches to manifold learning
The manifold methods can be categorized as:
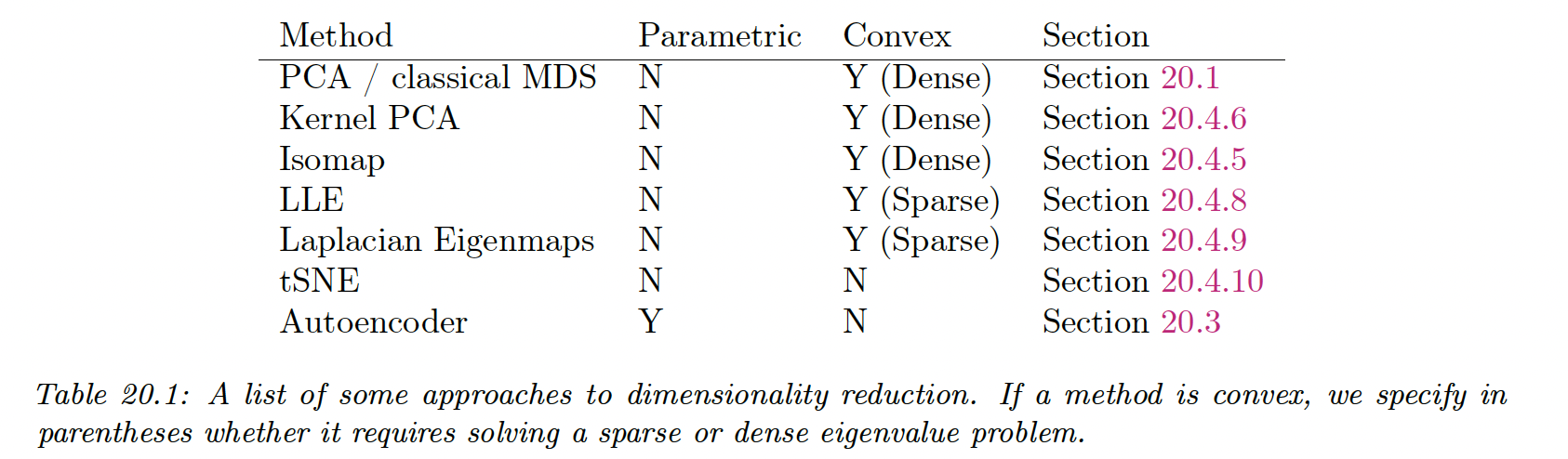
The term “nonparametric” refers to methods that learn a low dimensional embedding for each datapoint , but do not learn a mapping function that can be applied to out-of-sample example.
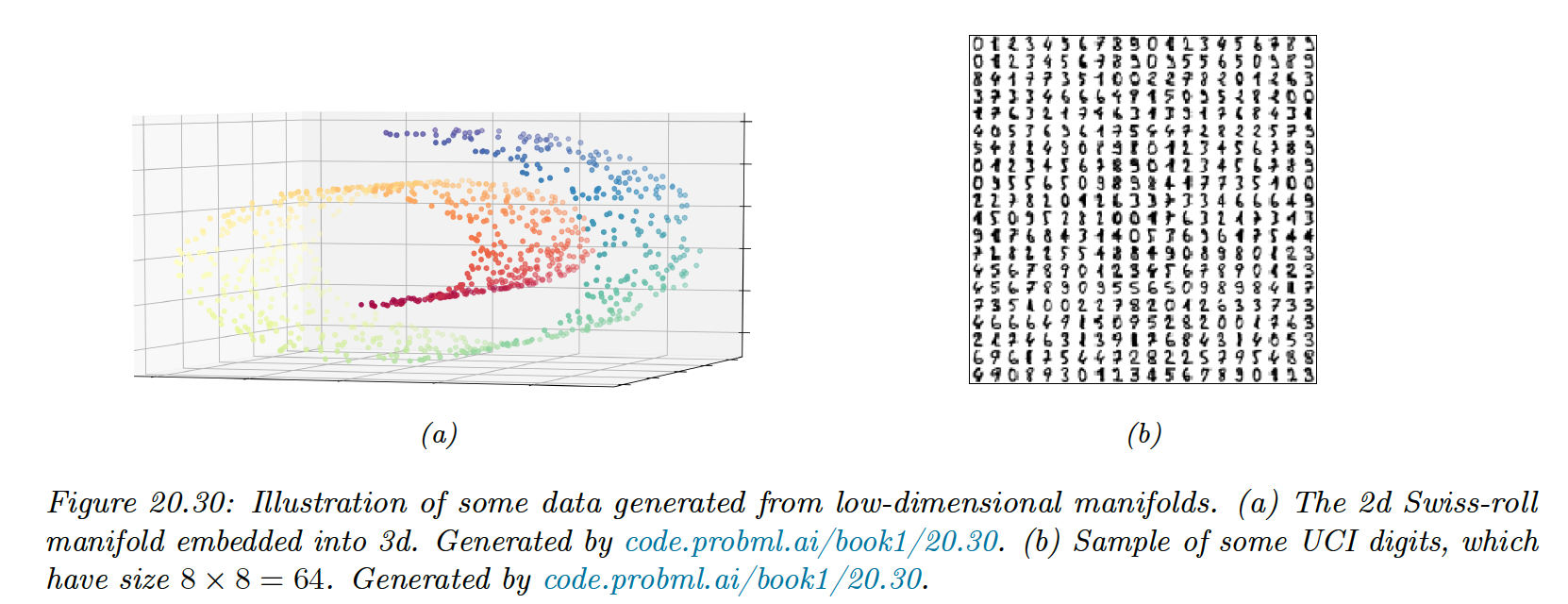
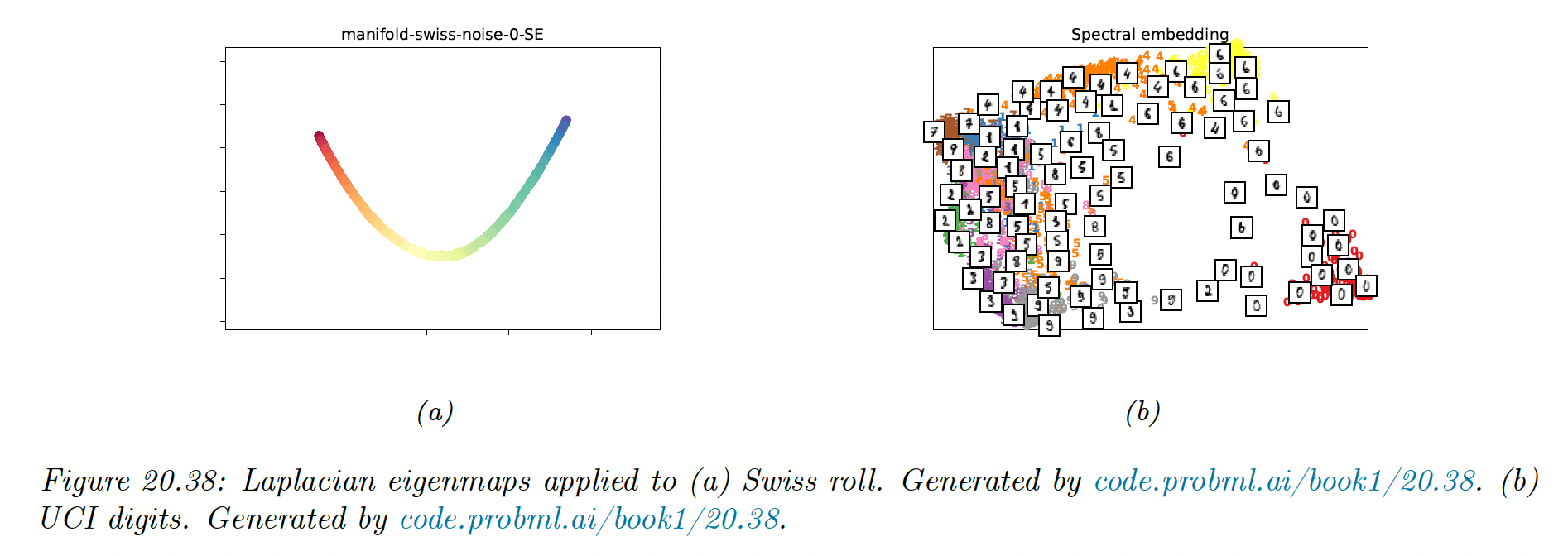
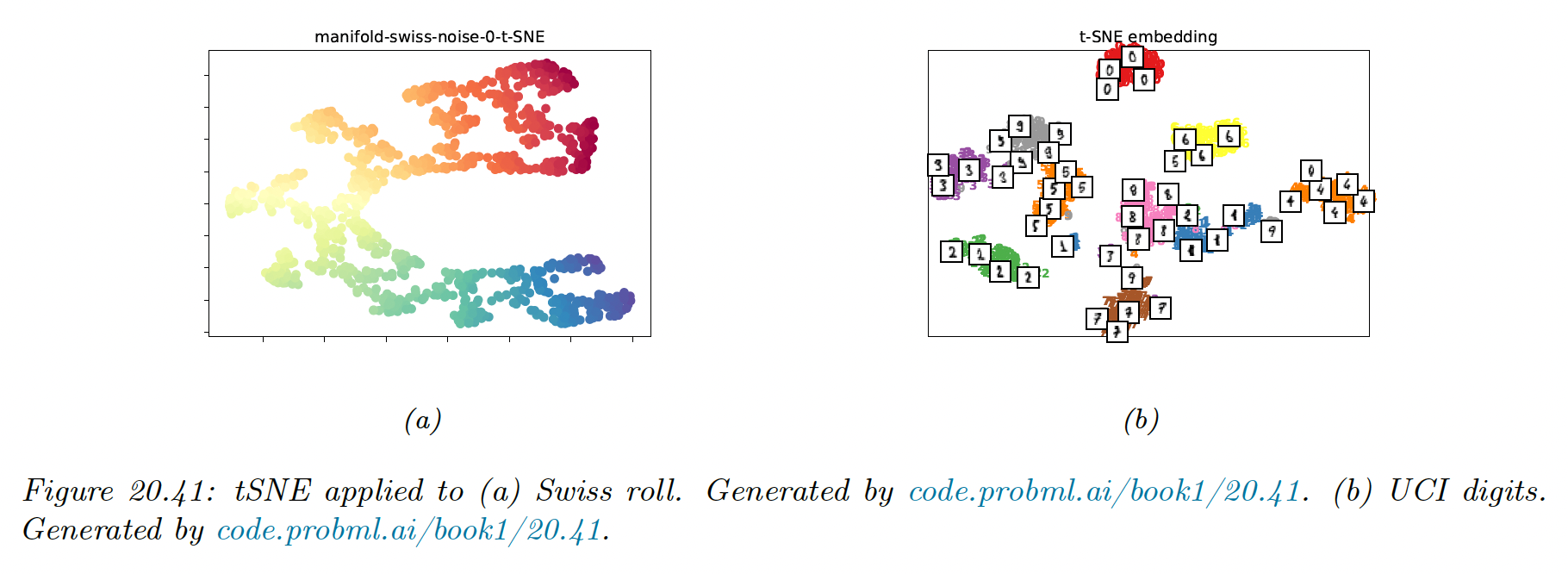
To compare methods, we use 2 different datasets: a set of 1000 3d-points sampled from the 2d “Swiss roll” manifold, and a set of 1797 points from the UCI digit datasets.
We will learn a 2d manifold to visualize the data.
20.4.4 Multi-dimensional scaling (MDS)
The simplest approach to manifold learning is multi-dimensional scaling (MDS). This tries to find a set of low dimensional vectors .
20.4.4.1 Classical MDS
We start with . The centered Gram (similarity) matrix is:
In matrix notation, we have with and
Now define the strain of a set of embeddings:
where is the centered vector.
Intuitively, this measures how well similarities in the high-dimensional space are preserved in the low-dimensional space. Minimizing this loss is called classical MDS.
We know that the best rank approximation to a matrix is its truncated SVD representation . Since is positive semi-definite, we have .
Hence the optimal embeddings satisfies:
Thus we can set the embedding vectors to be the rows of .
We can still apply the MDS when we just have the Euclidean distance instead of the raw data .
First, we compute the squared Euclidean matrix:
So, we see that only differs from a factor and some rows and columns constants. Thus, we can apply the double centering trick on to obtain :
or equivalently:
We can then compute the embeddings as before.
It turns out the classical MDS is equivalent to PCA.
To see this, let be the rank truncated SVD of the centered kernel matrix.
The MDS embeddings are given by .
Now consider the rank SVD of the centered data matrix The PCA embedding is .
Now:
Therefore, , and .
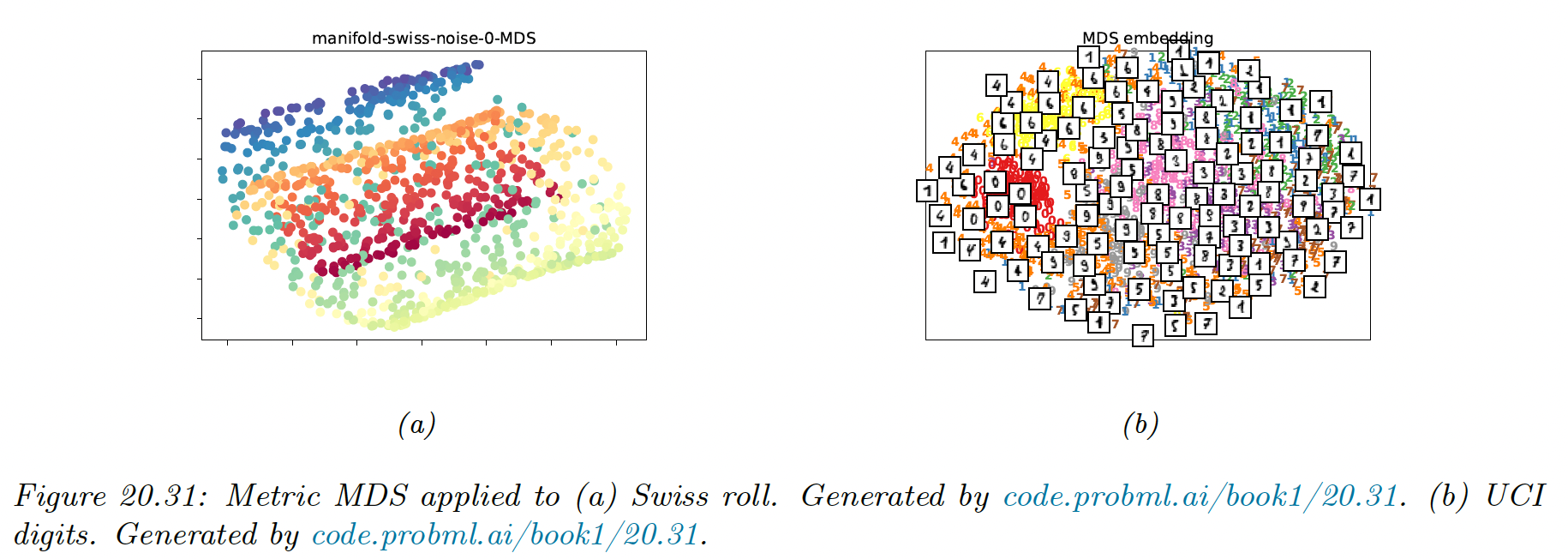
20.4.4.2 Metric MDS
Classical MDS assumes Euclidean distances. We can generalize it using any dissimilarity measure by defining the stress function:
where .
Note that this is a different objective than the one used with classical MDS, so even using Euclidean distances the results will be different.
We can use gradient descent to solve the optimization problem, however it’s better to use a bound algorithm problem called Scaling by Majorizing a Complication Function (SMACOF).
This is the method implemented in scikit-learn.
20.4.4.3 Non-metric MDS
Instead of trying to match the distance between points, we can instead try to match the ranking of how similar points are. Let be a monotonic transformation from distances to ranks.
The loss is:
where . Minimizing this is known as non-metric MDS.
This objective can be optimized iteratively.
First, the function is approximated using isotonic regression; this finds the optimal monotonic transformation of the input distance to match the current embedding distances.
Then, the embeddings are optimized, using a given , using gradient descent, and the process repeats.
20.4.5 Isomap
If the high-dimensional data lies on or near a curved manifold, such as the Swiss roll example, then MDS might consider the two points to be close even if their distance along the manifold is large.
One way to capture this is to create the -nearest neighbor graph (by using scikit-learn (opens in a new tab)) between datapoints and then approximate the manifold distance between a pair of points by the shortest distance on the graph.
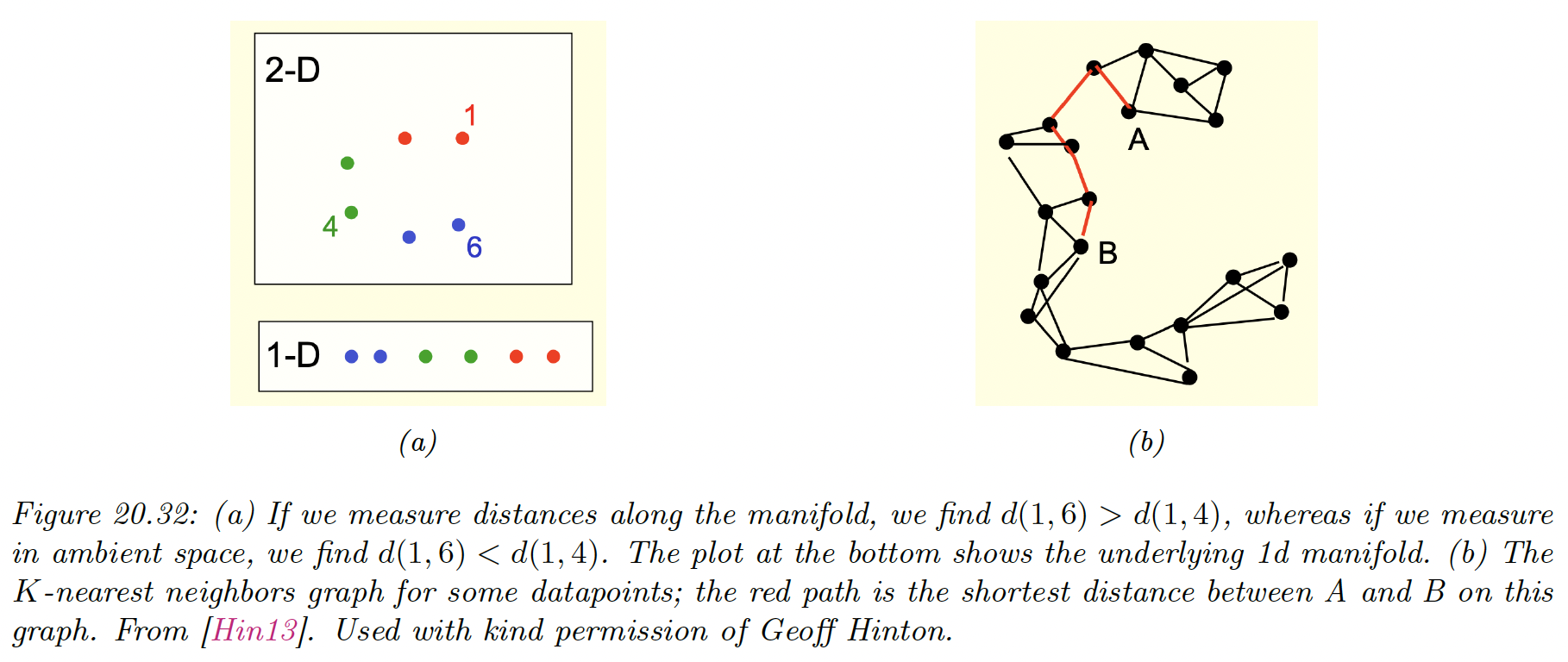
This can be computed efficiently using Dijkstra’s shortest path algorithm. Once we have computed this new distance metric, we use classical MDS (i.e. PCA).
This is a way to capture local structure while avoiding local optima. The overall method is called Isometric mapping (Isomap).
The results are quite reasonable.

However, if the data is noisy, there can be “false“ edges in the nearest neighbor graph, which can result in “short circuits”, which significantly distort the embedding.
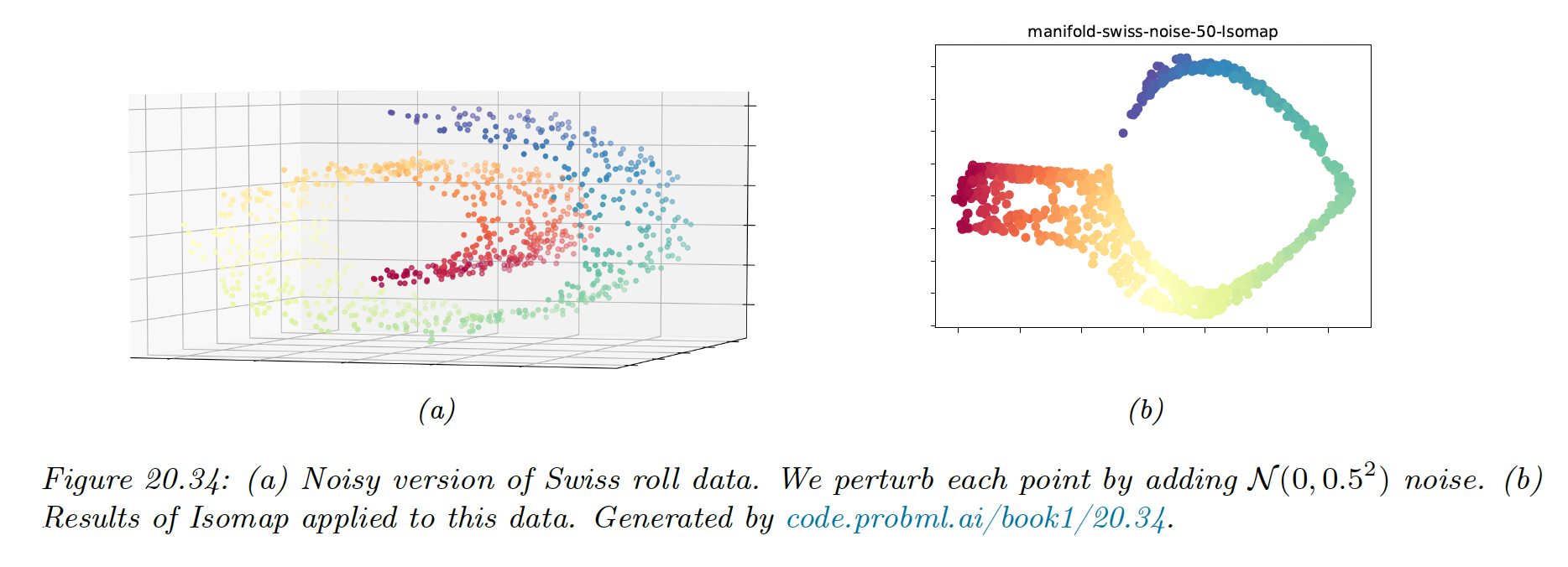
This problem is known as topological instability. Choosing a very small neighborhood doesn’t solve the problem since this can fragment the manifold into a large number of disconnected regions.
See more details on scikit-learn documentation (opens in a new tab).
20.4.6 Kernel PCA
We now consider nonlinear projections of the data. The key idea is to solve PCA by finding the eigenvectors of the inner product (Gram) matrix and then to use the kernel trick, which lets us replace inner product with kernel function . This is known as kernel PCA.
Recall from Mercer’s theorem that the use of kernel implies some underlying feature space, we are implicitly replacing by .
Let be the corresponding (notional) design matrix, and be the covariance matrix in feature space (we assume are centered)
From section 20.1.3.2, we know:
where and contains the eigenvectors and eigenvalues of .
We can’t compute directly since the might be infinite dimensional. However, we can compute the projection of the test vector on the feature space:
where
If we apply kPCA with a linear kernel we recover the regular PCA. This is limited to using embedding dimensions. If we use a non-degenerate kernel, we can use up to components, since where is the dimensionality of embedded feature vectors (potentially infinite).
The figure below gives an example of the method with using a RBF kernel.
We obtain the blue levels using the following method: for each plot, we project points in the unit grid onto each component by computing and its product with , obtained from the data points. We obtain a “density map” for the points in the grid, and then draw a contour plot.
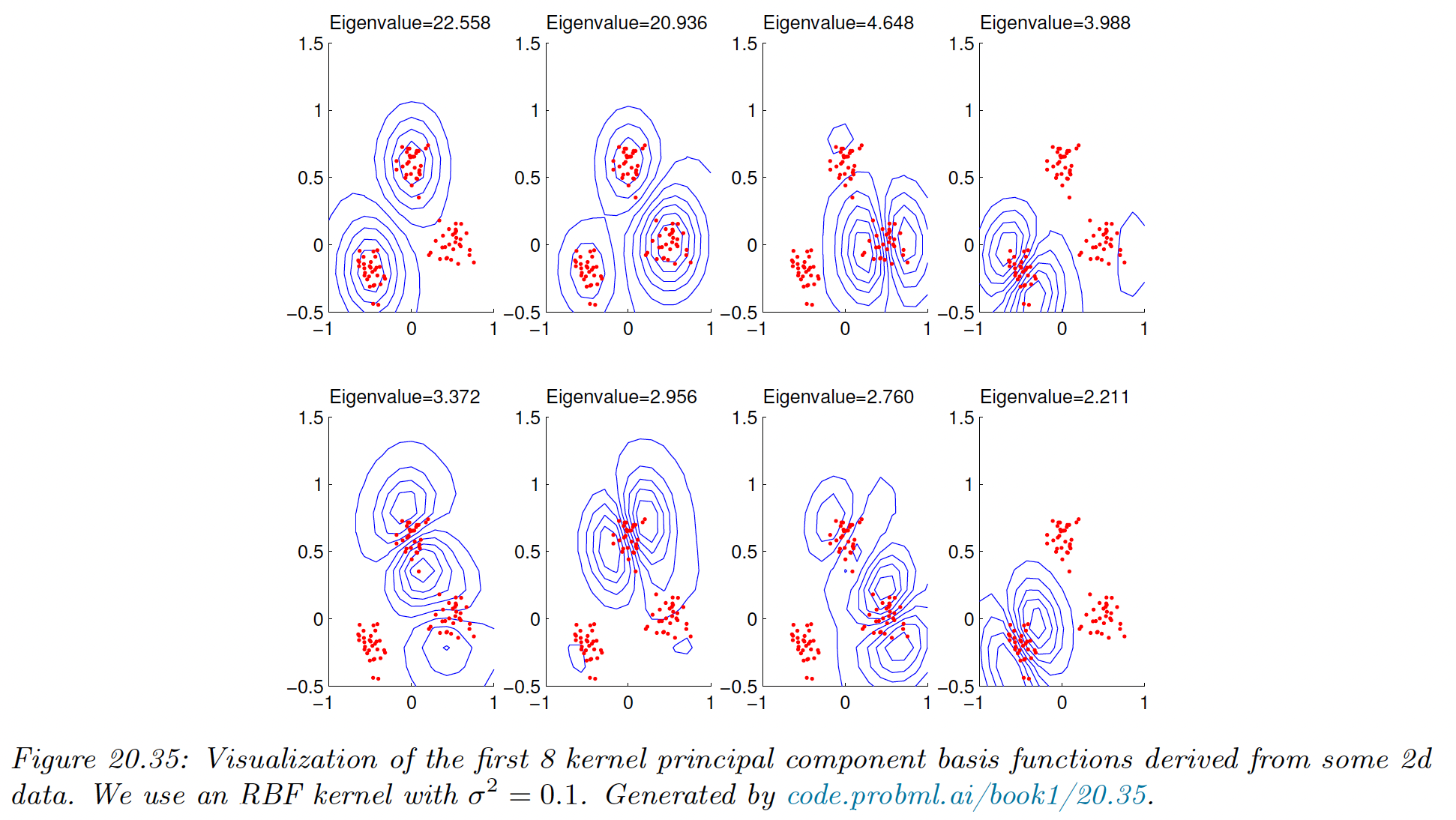
We see that the first two components separate the three clusters, while the other split the clusters.
The figure below show that the kPCA is not very useful for our dimension reduction problem. It can be shown that kPCA expand features instead of reducing it.

20.4.7 Maximum variance unfolding (MVU)
kPCA with RBF kernel might not result in low dimensional embedding. This observation led to the development of the semidefinite embedding algorithm, aka maximum variance unfolding, which tries to learn an embedding such that:
when is the nearest neighbor graph (as in Isomap).
This approach tries to “unfold” the manifold while respecting its nearest neighbor constraints.
This can be reformulated as a semidefinite programming (SDP) problem by defining the kernel matrix and maximizing:
The resulting kernel is then passed to kPCA, and the resulting eigenvectors give the low dimensional embedding.
20.4.8 Local linear embedding (LLE)
The techniques discussed so far relied on the eigenvalue decomposition of a full matrix of pairwise similarities, either in the input space (PCA), in the feature space (kPCA) or along the KNN graph (Isomap).
In this section we discuss local linear embedding (LLE), a technique that solves a sparse eigenproblem, by focusing on local structure in the data.
LLM assumes the data manifold around each point is locally linear. The best linear approximation can be found by predicting as a linear combination of its nearest neighbors using reconstruction weights (aka the barycentric coordinate of :
Any linear mapping of this hyperplane to a lower dimensional space preserves the reconstruction weights, and thus the local geometry.
Thus we can solve for the low dimensional embeddings for each point by solving:
with the same constraints.
We can rewrite this loss as:
As shown in section 7.4.8, the solution is given by the eigenvectors of corresponding to the smallest non-zero eigenvalues.
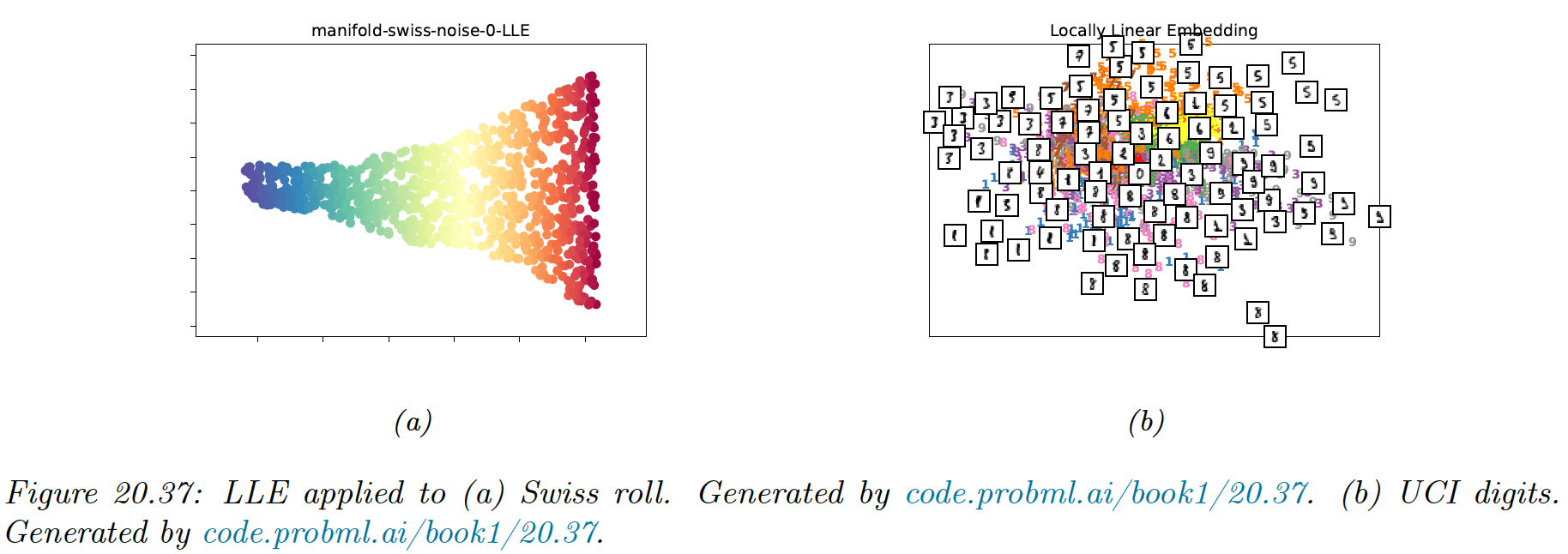
The results do not seem as good as the one obtained with the Isomap, however this method tend to be more robust to short-circuiting (noise).
20.4.9 Laplacian eigenmaps (Spectral embeddings)
The key idea of Laplacian eigenmaps is to find a low-dimensional representation of data in which the weighted distances between a datapoint and its nearest neighbors are minimized.
We put more weight on the first nearest neighbor than the second, etc.
20.4.9.1 Using eigenvectors of the graph Laplacian to compute embeddings
We want to find the embeddings that minimizes:
where if are neighbors on the KNN graph, 0 otherwise.
We add the constraint to avoid the degenerate solution where , where is the diagonal weight matrix storing the degree of each node
We can rewrite the objective as follows:
where is the graph Laplacian.
One can show that minimizing this graph is equivalent to solving the (generalized) eigenvalue problem:
for the smallest nonzero eigenvalues.
20.4.9.2 What is the graph Laplacian?
We saw above that we need to compute the eigenvectors of the graph Laplacian to compute a good embedding of the high dimensional points. We now give some intuitions on why this works.
We saw that the elements of can be computed as:

Suppose we associate a value to each node of the graph:
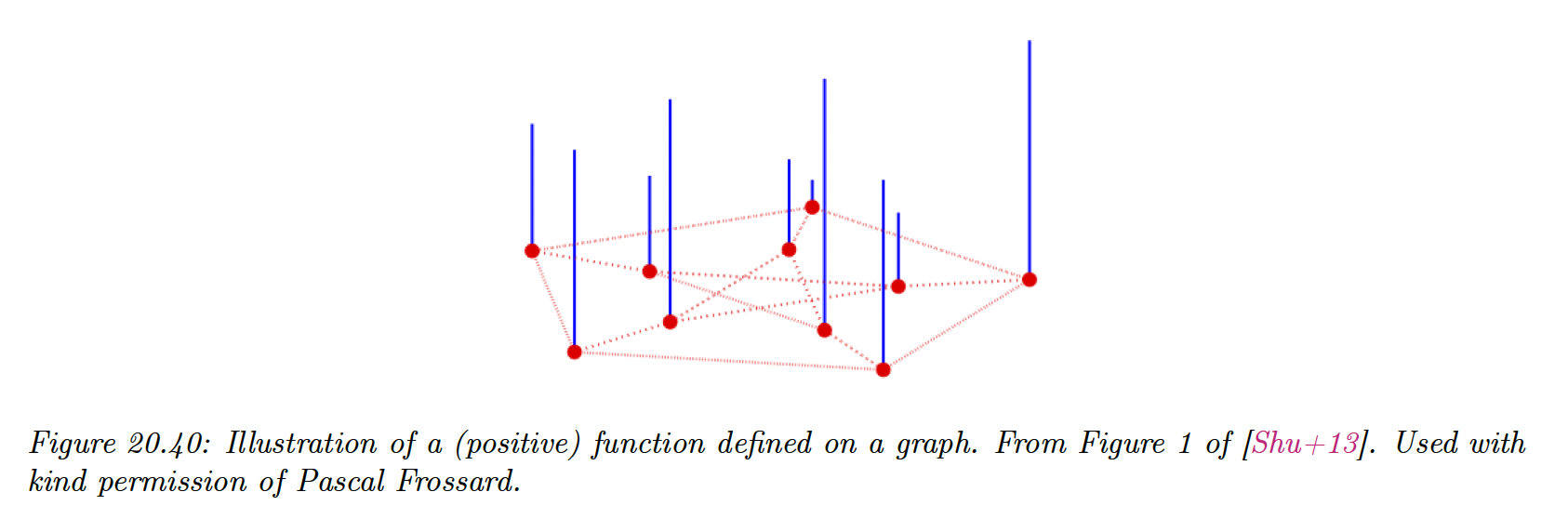
Then we can use the graph Laplacian as a difference operator, to compute a discrete derivative of a function at a point:
where refers to the set of neighbors of node .
We can also compute an overall measure of smoothness of the function by computing its Dirichlet energy:
Applying linear algebra to study the adjacency matrix of a graph is called spectral graph theory.
For example, we see that is semi-positive definite, since for all .
Consequently, has nonzero, real-valued eigenvalues .
The corresponding eigenvectors form an orthogonal basis for the function defined on the graph, in order of decreasing smoothness.
There are many applications of the graph Laplacian in ML, like normalized cuts (which is way of learning a clustering based on pairwise similarity) and RL where the eigenvectors of the state transition matrix are used.
20.4.10 t-SNE
We describe a very popular nonconvex technique for learning low dimensional embeddings, called t-SNE. This is an extension of the earlier stochastic neighbor embedding (SNE) (opens in a new tab).
20.4.10.1 Stochastic neighbor embedding (SNE)
The basic idea is to convert a high-dimensional Euclidean distance into a conditional probability. More precisely, we define to be the probability that point would pick point as its neighbor:
Here is the variance of data point , which can be used to magnify the scale of points in dense regions of input space, and diminish the scale in sparser regions.
Let be the low-dimensional embedding representing . We define similarities in the low-embedding space in a similar way:
If the embedding is good, then should match . Therefore, SNE defines the objective:
where is the conditional distribution over all other data points given .
Note that this is an asymmetric objective: the cost is high if a small is used to model a large . This objective will prefer pulling distance point together rather than pushing nearby point apart.
We can get a better sense of the geometry by computing the gradient of the objective at :
Thus points are pulled together if the ’s are bigger than the ’s, and repelled otherwise.
This objective is not convex, but it can be minimized using SGD nevertheless. In practice, it is helpful to add Gaussian noise to the embeddings and anneal the amount of noise.
20.4.10.2 Symmetric t-SNE
We can simplify SNE by minimizing a single KL between the joint distribution and :
This is called symmetric SNE.
We can define as:
This corresponds to the gradient:
Which gives similar results than regular SNE when .
20.4.10.3 t-SNE
A fundamental problem with SNE and many other embedding techniques is that they tend to squeeze points that are far in the high dimensional space close together in the low dimensional embedding space, this is called the crowding problem. This is due to the use of squared errors (or Gaussian probabilities).
One solution to this is to use a probability distribution in latent space that has heavier tails, which eliminates the unwanted force of attraction between distant points in the high dimensional space.
We can choose the Student-t distribution. In t-SNE, they set the degree , so the distribution is equivalent to a Cauchy:
This uses the same objective as the symmetric SNE, and the gradient turns out to be:
The new term acts like an inverse square law. This means data points is the embedding space act like stars and galaxies, forming well separated clusters each of which has many stars tightly packed inside.
This can be useful to separate different classes of data in a unsupervised way.
20.4.10.4 Choosing the length scale
The local bandwidth is an important parameter in t-SNE, and is usually chosen so that has a perplexity chosen by the user, defined as where:
This can be interpreted as smooth measure of the effective number of neighbors.
Unfortunately, the results of t-SNE can be quite sensitive to the perplexity parameter, so it is often advised to run the algorithm with different values.

If the perplexity is too small, the algorithm will find structure within the cluster which is not present. At perplexity 30 (the default for scikit-learn), the clusters seem equidistant in the embedding space.
20.4.10.5 Computational issues
The Naive implementation of t-SNE takes time. A faster version can be created by leveraging an analogy to the -body simulation in physics.
In particular, the gradient requires computing the forces of points on each of points. However, points that are far away can be grouped into clusters (computationally speaking), and their effective force can be approximated by a few representatitve points per cluster.
We can then approximate the forces using the Barnes-Hut algorithm, which takes .
Unfortunately, this only works well for low dimensional embeddings, such as (which is adapted to data visualization).
20.4.11 UMAP
Various extension of t-SNE have been proposed to improve its speed, the quality of its embedding space or the ability to embed into more than 2 dimensions.
Uniform Manifold Approximation and Projection (UMAP) is a popular recent extension. At a high level, it is similar to t-SNE, but it tends to preserve global structure better, and it is much faster. This makes it easier to try different hyperparameters.