13.2 Multilayer perceptrons (MLP)
In section 10.2.5, we explained that the perception is a deterministic version of logistic regression:
where is the Heaviside step function.
Since the decision boundaries of the perceptron are linear, they are very limited in what they can represent.
13.2.1 The XOR problem
One of the most famous problems of the perceptron is the XOR problem. Its truth table is:
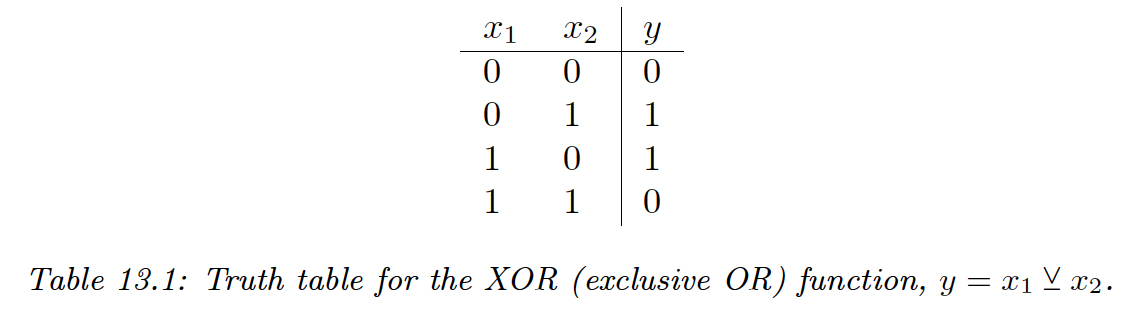
We visualize this function and see that this is not linearly separable, so a perception can’t represent this mapping.
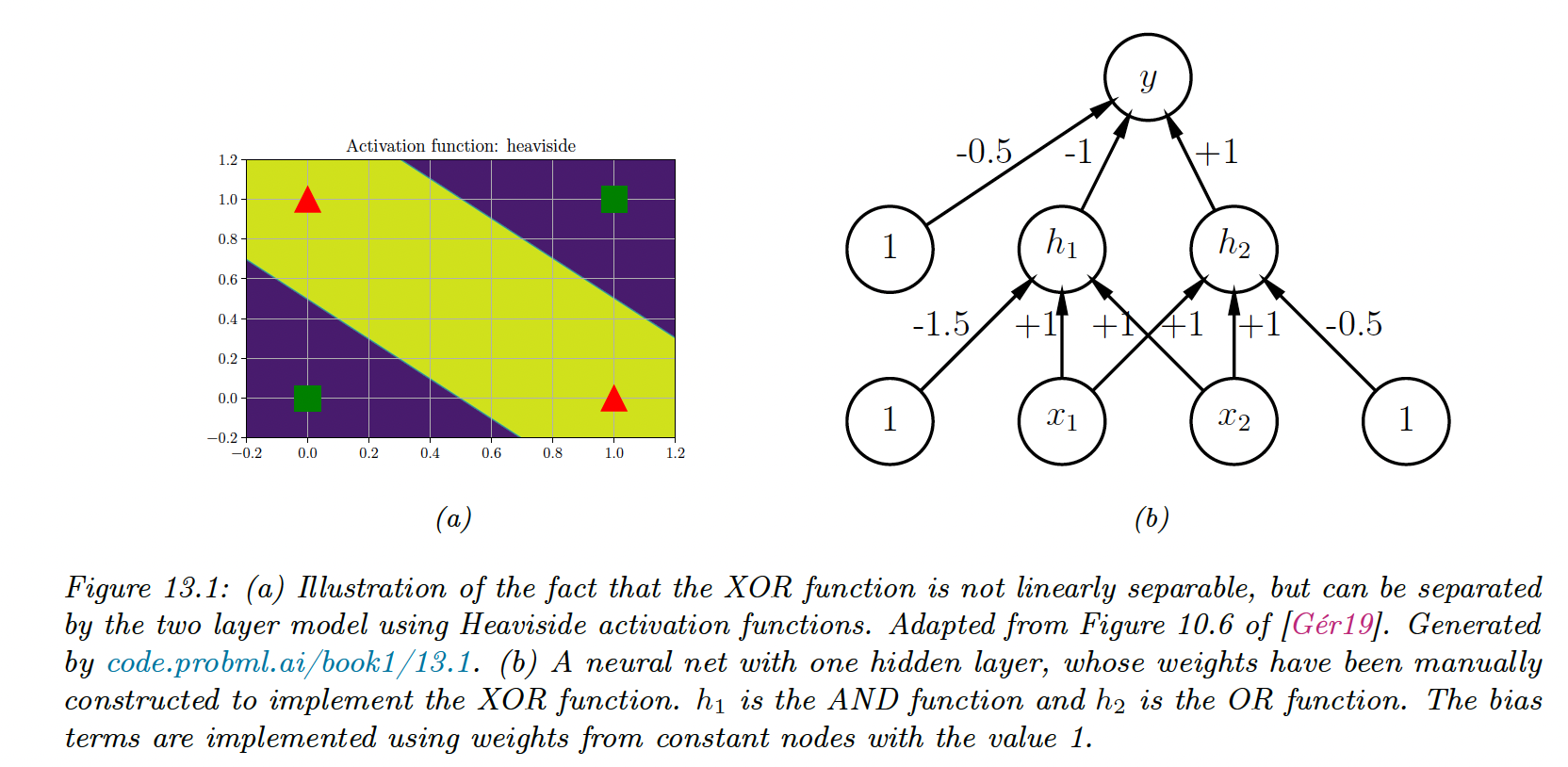
However, we can solve this problem by stacking multiple perceptrons together, called a multilayer perceptron (MLP).
Above, we use 3 perceptions (, and , where the first two layers are hidden units since their output is not observed in the training data.
This gives us:
where the activation are , the overline is the negative operator, is OR, and is AND.
By generalizing, we see the MLP can represent any logical function.
However, we obviously want to avoid learning the weights and biases by hand and learn these parameters from the data.
13.2.2 Differentiable MLPs
The MLP we discussed involves the non-differentiable Heaviside function, which makes it difficult to learn. This is why the MLP under this form was never widely used.
We can replace the Heaviside with a differentiable activation function
The hidden units at layer are defined by the linear transformation of the previous hidden units passed element-wise through an activation function:
If we now compose of these functions together, we can compute the gradient of the output w.r.t the parameters in each layer using the chain rule. This is called backpropagation.
We can then pass the gradient to any optimizer and minimize some training objectives.
13.2.3 Activation functions
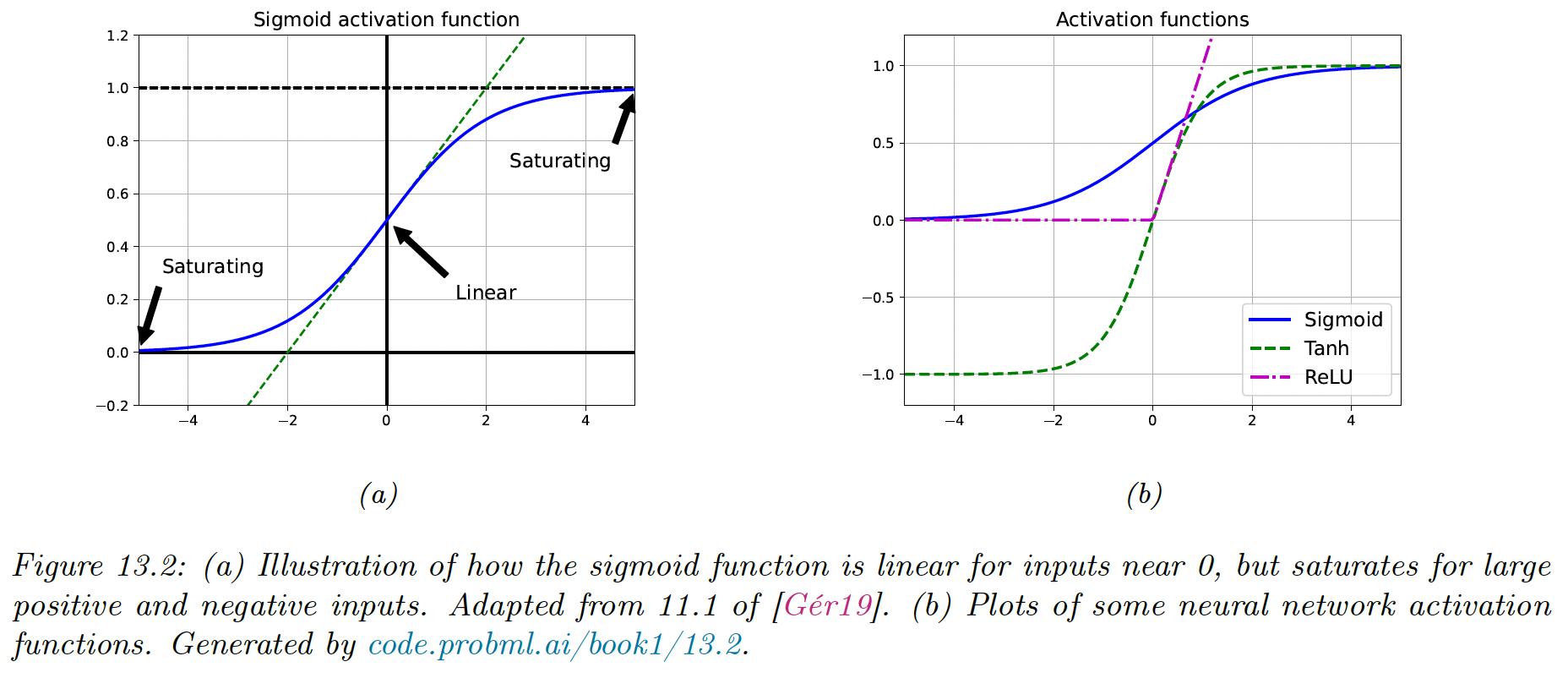
If we use a linear activation function, then the whole model is equivalent to a regular linear model. For this reason, we need to use non-linear activation functions.
Sigmoid and tanh functions were common choice, but they saturate for large positive or negative values, making the gradient close to zero, so any gradient signal from higher layers won’t be able to propagate back to earlier layers.
This is known as the vanishing gradient problem and makes it hard to train models with gradient descent.
The most common non-saturating activation function is rectified linear unit (ReLU):
13.2.4 Example models
13.2.4.1 MLP for classifying 2d data into 2 categories
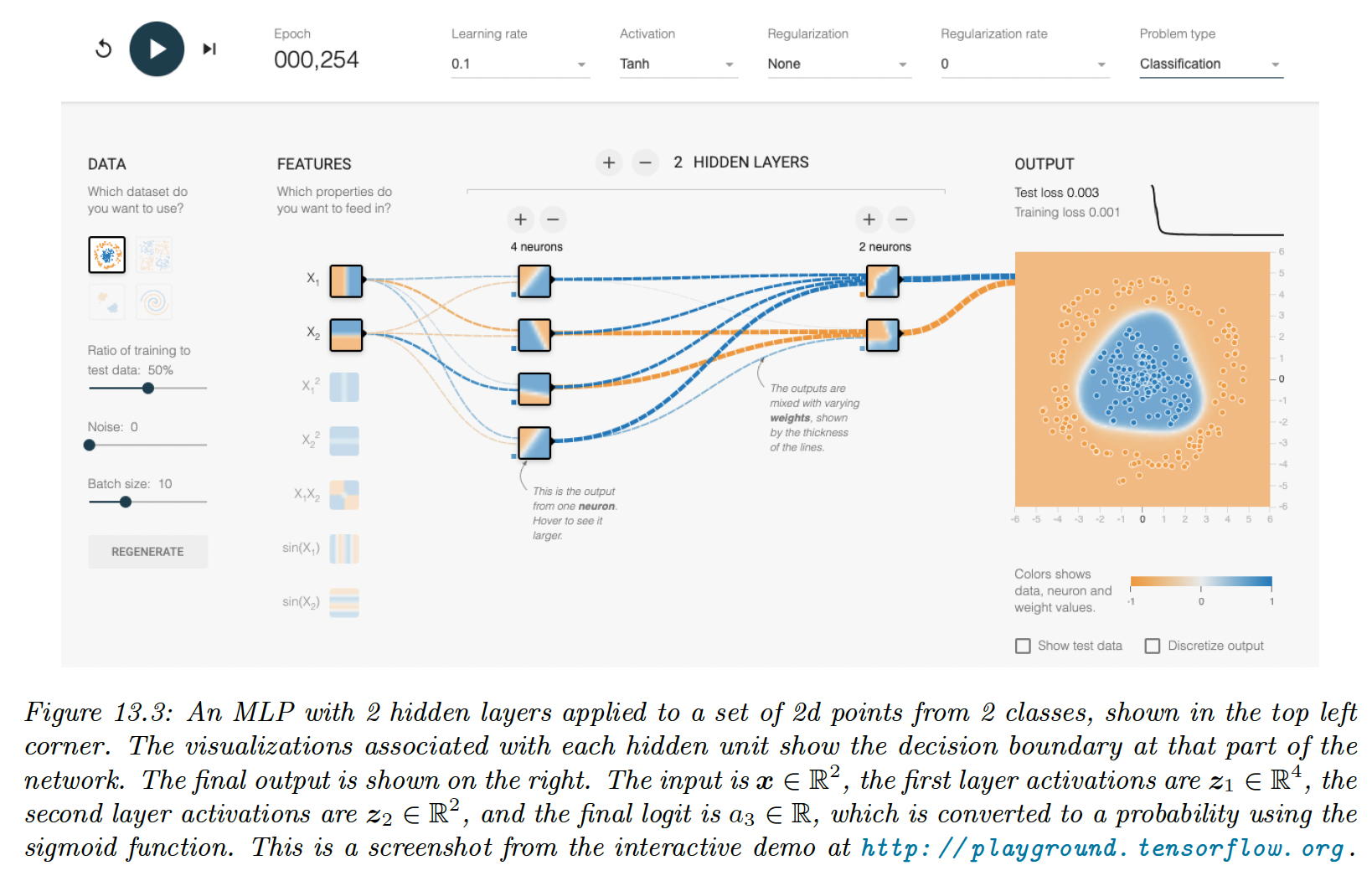
The model has the following form:
13.2.4.2 MLP for image classification
To apply MLP to 2d images (), we need to flatten them to 1d vectors (). We can then use a feedforward architecture.
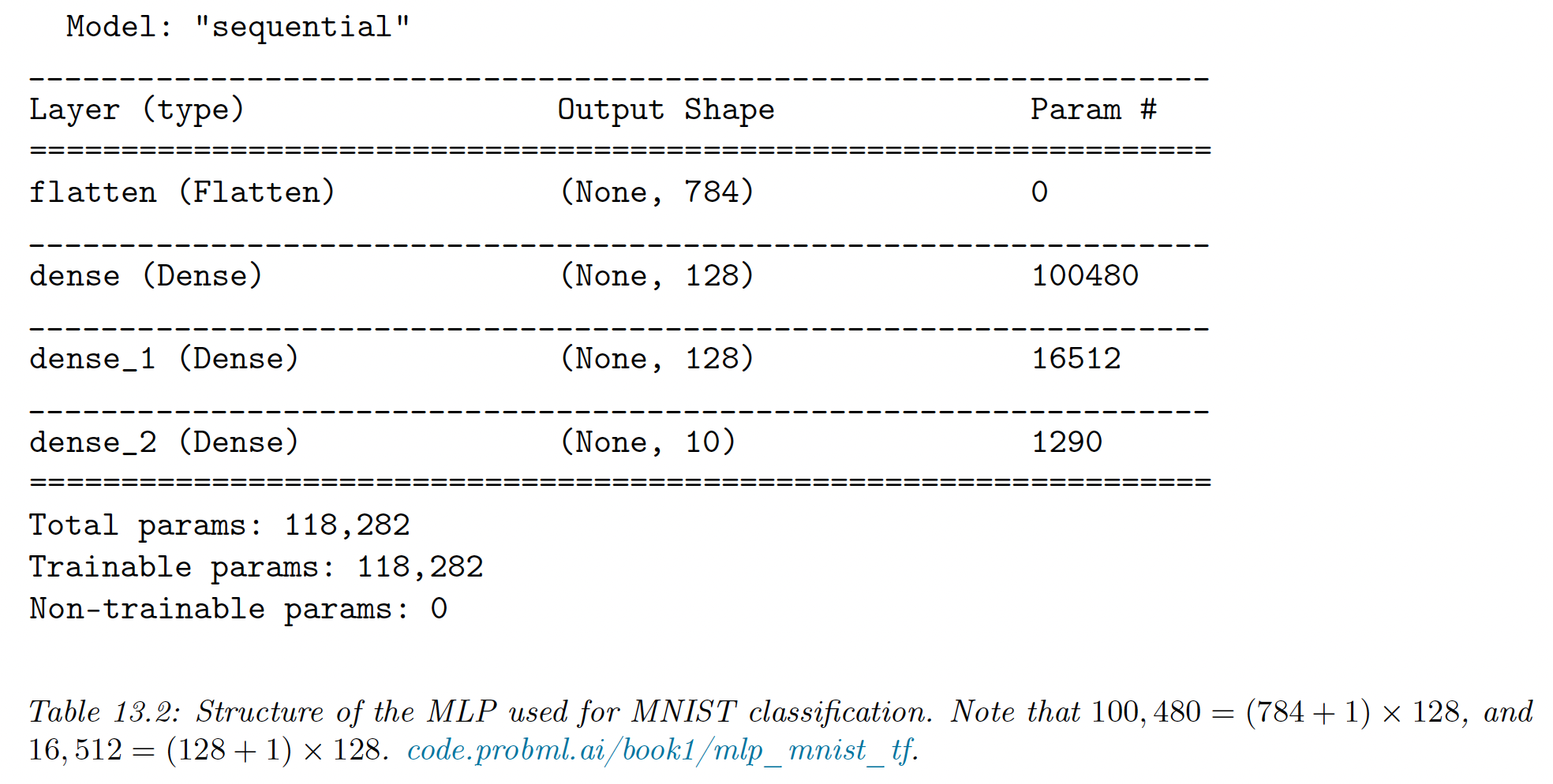
On MNIST, the model achieves a test set accuracy of 97%.
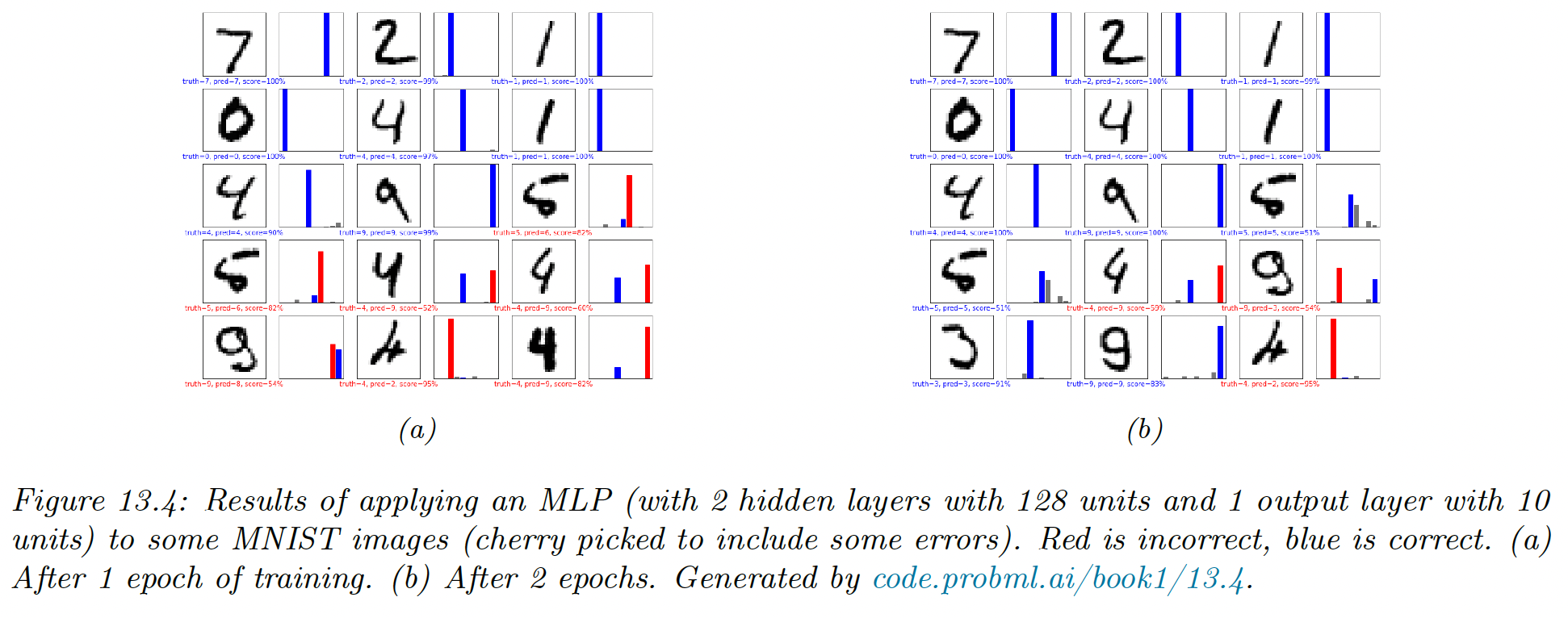
CNNs are better suited to handle images by exploiting their spatial structure, with fewer parameters than the MLP.
By contrast, with a MLP we can randomly shuffle the pixels without affecting the output.
13.2.4.3 MLP for text classification
We need to convert a variable-length sequence of words into a fixed dimensional vector , where is the vocabulary size and are one-hot-encoding vectors.
The first layer is an embedding matrix , which converts a sparse dimensional vector into a dimensional embedding.
Next, we convert this set of embeddings into a fixed-size vector using global average pooling.
Then we can pass it to an MLP.
This has the form:
If we use , an embedding size of , and a hidden layer of size , and apply this model to the IMDB movie review sentiment classification dataset, we get an accuracy of 86% on the validation set.

The embedding layer has the most parameters, and with a training set of only 25k elements, it can easily overfit.
Instead of learning these parameters in a supervised way, we could reuse unsupervised pre-training of word-embedding models. If is fixed, we have much fewer parameters to learn.
13.2.4.4 MLP for heteroskedastic regression
We can also use MLP for regression. “Heteroskedastic” means the output-predicted variance is input-dependent.
This function has two outputs to compute and .
We can share most of the layers with these two functions by using a common “backbone” and two outputs “heads”
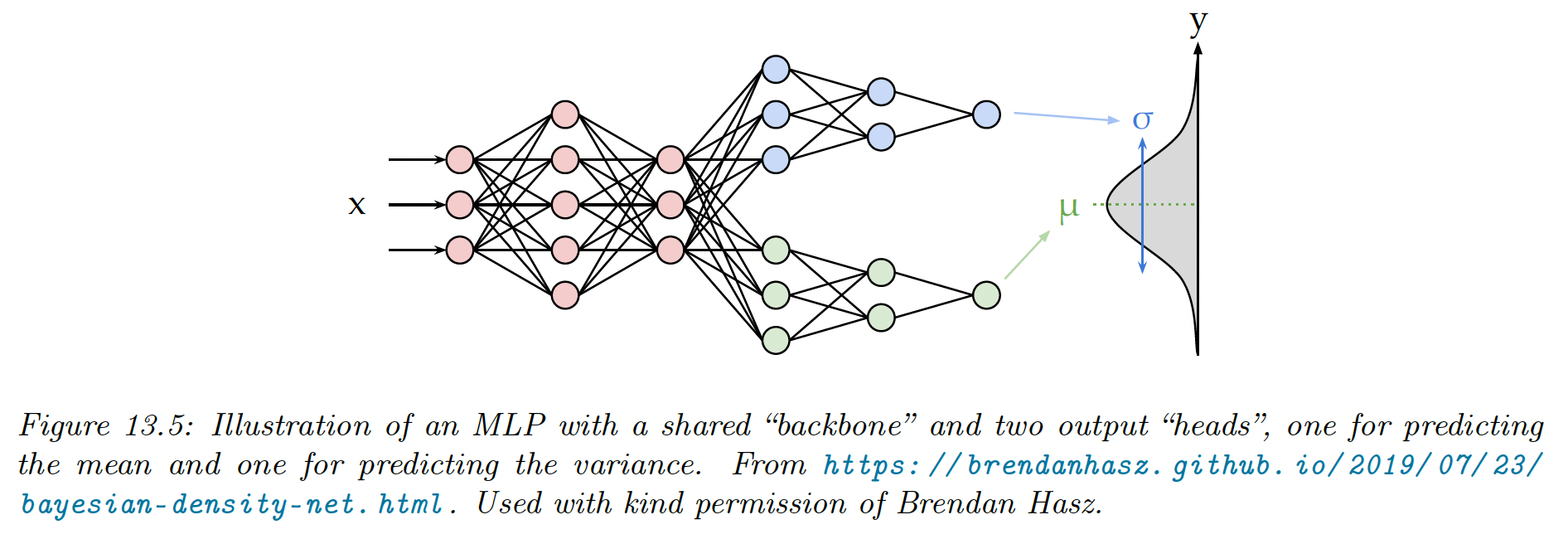
For the head, we use a linear activation , and for the , we use the soft-plus activation .
If we use linear heads and a non-linear backbone, the model is given by:
This model suits datasets where the mean grows linearly over time, with seasonal oscillations, and the variance quadratically. This is a simple example of stochastic volatility, as can be seen in financial or temperature data with climate change.
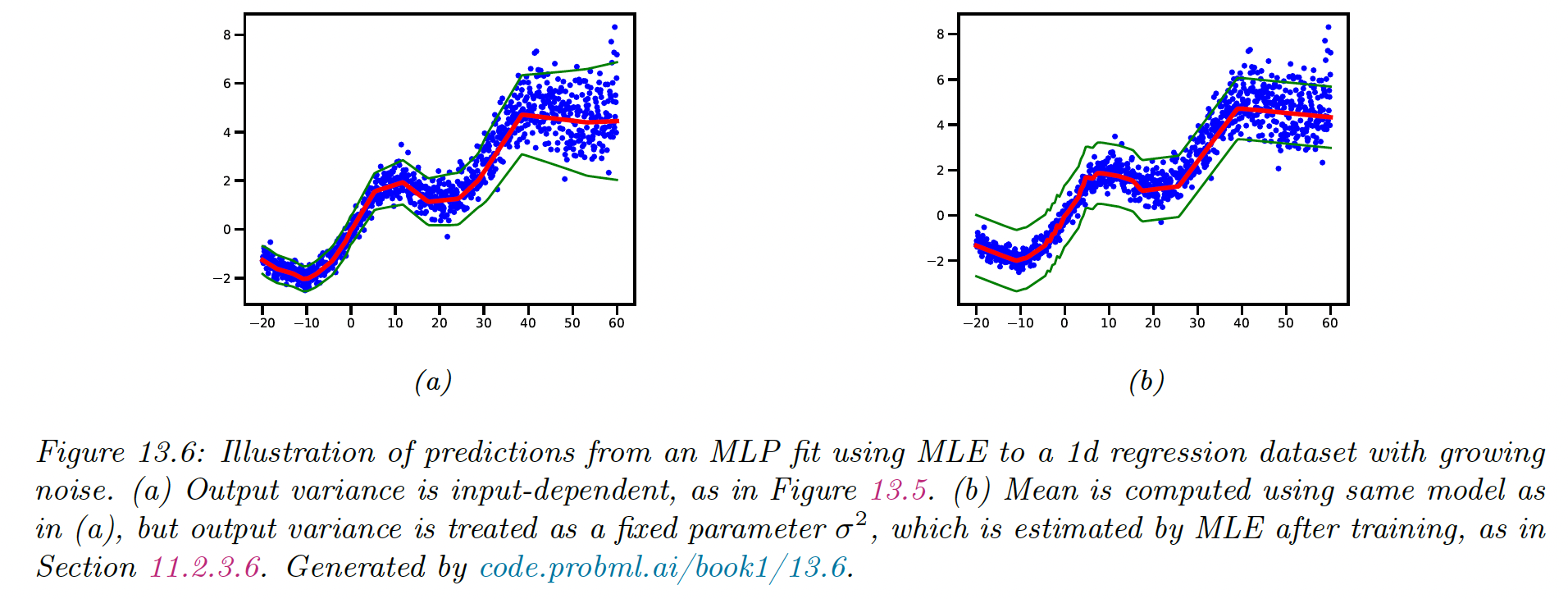
The model is underconfident at some points when it considers a fix since it needs to adjust the overall noise model and can’t make adjustments.
13.2.5 The importance of depth
One can show that an MLP with one hidden layer can approximate any smooth function, given enough hidden parameters, to any desired level of accuracy.
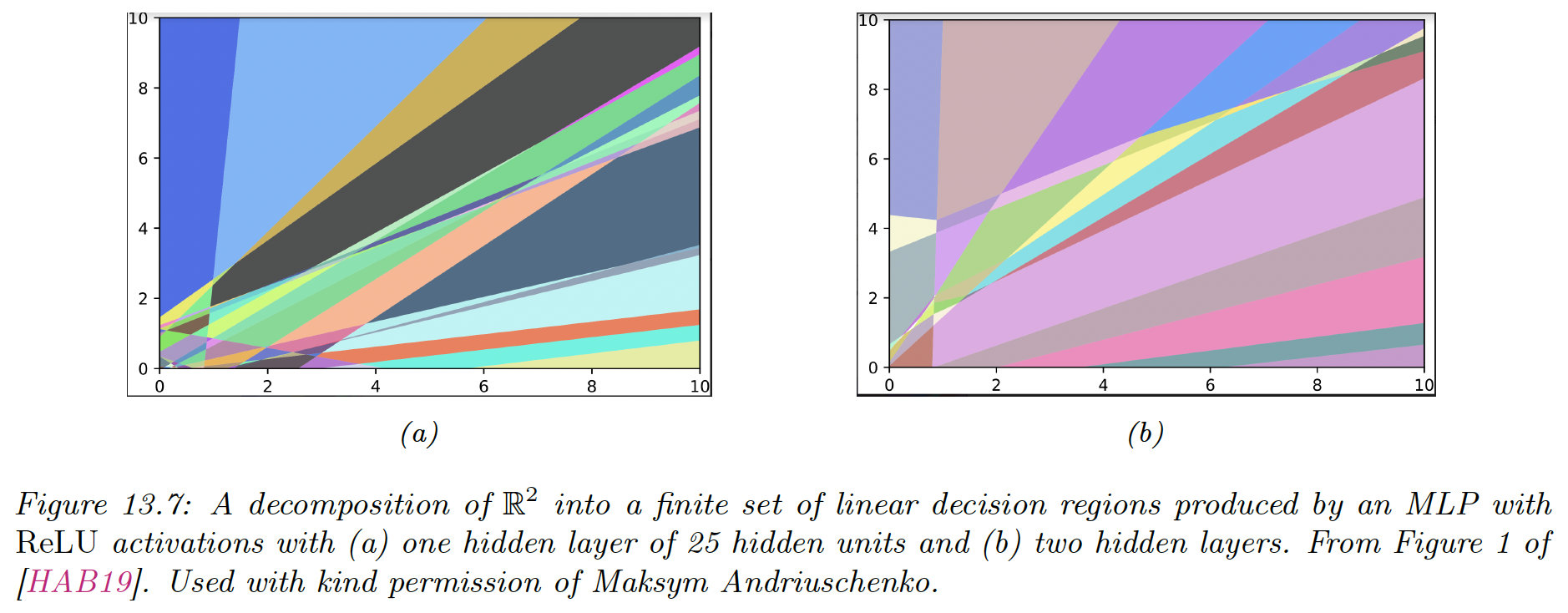
The literature has shown that deep networks work better than shallow ones. The idea is that we can build compositional or hierarchical models, where later layers can leverage the feature extracted by earlier layers.
13.2.6 The deep learning revolution
Although the idea behind DNN date back several decades ago, they started to become widely used only after the 2010s. The first area to adopt these methods was the field of automatic speech recognition (ASR).
The moment that got the most attention was the introduction of deep CNN to the ImageNet challenge in 2012, which significantly improve the error rate from 26% to 16%. This is was a huge jump since the benchmark only improved by 2% every year.
The explosion in the usage of DNNs has several factors:
- The availability of cheap GPUs, that can massively reduce the fitting time for CNNs
- The growth of large, labeled datasets, allows models to gain in complexity without overfitting (ImageNet has 1.3M of labeled images)
- High-quality open-source software like Tensorflow (by Google), PyTorch (by Facebook), and MXNet (by Amazon). These libraries support automatic differentiation and scalable gradient-based optimization.