4.3 Empirical risk minimization (ERM)
We can generalize the MLE by replacing the loss loss term with any other loss to get:
4.3.1 Misclassification rate
Let our true label and our prediction
We can define the loss as the misclassification rate
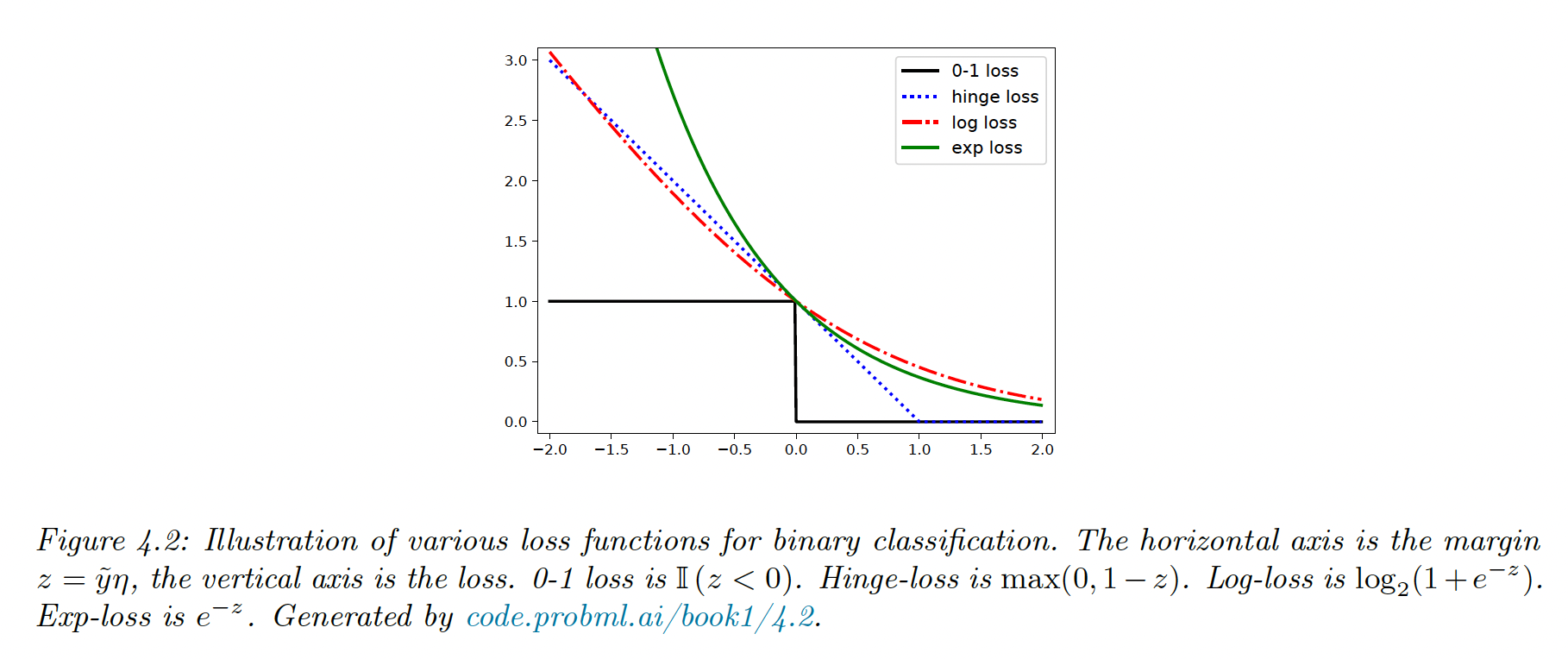
4.3.2 Surrogate loss
Unfortunately, the 0-1 loss is non smooth, making it NP-hard to optimize. Here we use a surrogate loss function, a maximally tight convex upper bound, easy to minimize.
For exemple, let
where is the logs odds
The log loss is
This is a smooth upper bound to the 0-1 loss where is the margin (it defines a “margin of safety” away from the threshold at 0)