5.1 Bayesian decision theory
Bayesian inference allows us to update our belief about hidden quantities based on observed data . To convert this inference into an action, we use Bayesian decision theory.
5.1.1 Basics
We assume an agent has a set of possible actions . Each of these actions have a cost and benefits, depending on some state .
We can encode this information using a loss function , specifying the cost of taking action with state .
In medical circles, a common measure to quantify the benefits of a drug is the quality-adjusted life years (QALY)

Once we have the loss function, we can compute the posterior expected loss or risk
The optimal policy specifies what action to take given observed data
In the case of Covid, let say that is the age of each patient. We can convert test results into a distribution over disease states, and by combining it with the loss matrix above we can compute the optimal policy for each observation.
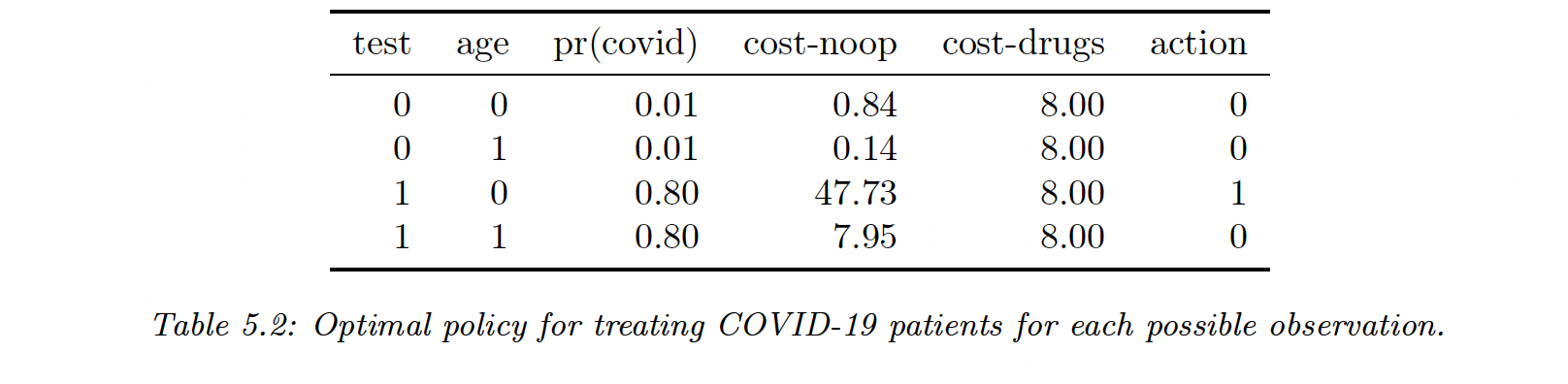
Let say we improve the precision of the test, the probability that a positive test is correct increases and the cost of no-op for elderly increases as well, thus changing the action to take into 1.
5.1.2 Classification problems
Given an observed input , what is the optimal class label to predict?
Zero-one loss
Suppose the states are some classes , and the action correspond to class labels .
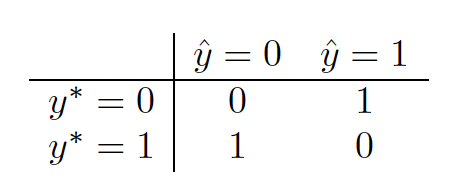
Which corresponds to
In this case the posterior expected loss is
Hence the action that minimize the risk is the most probable label, that is the mode of the posterior distribution, aka the MAP estimate
Cost sensitive classification
Let’s now have the following loss function
Let and . We select iff
when that simplifies to
And we have
So if a false negative cost 2 times as much as a false positive, our positive threshold is .
The reject option
In some cases we would like to be able “I don’t know” instead of answering: that’s the reject option. The actions are where 0 is the reject option.
The loss function is
And we choose the reject action whenever the highest probability is below . Otherwise choose the most probable class.
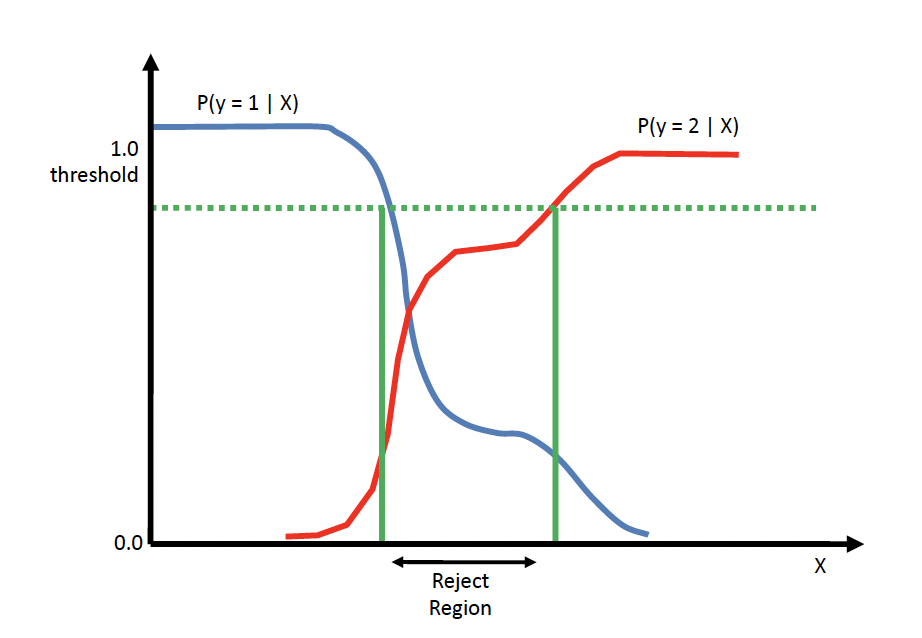
5.1.3 ROC curve
For any fixed threshold we consider the following
We can compute the number of false positives
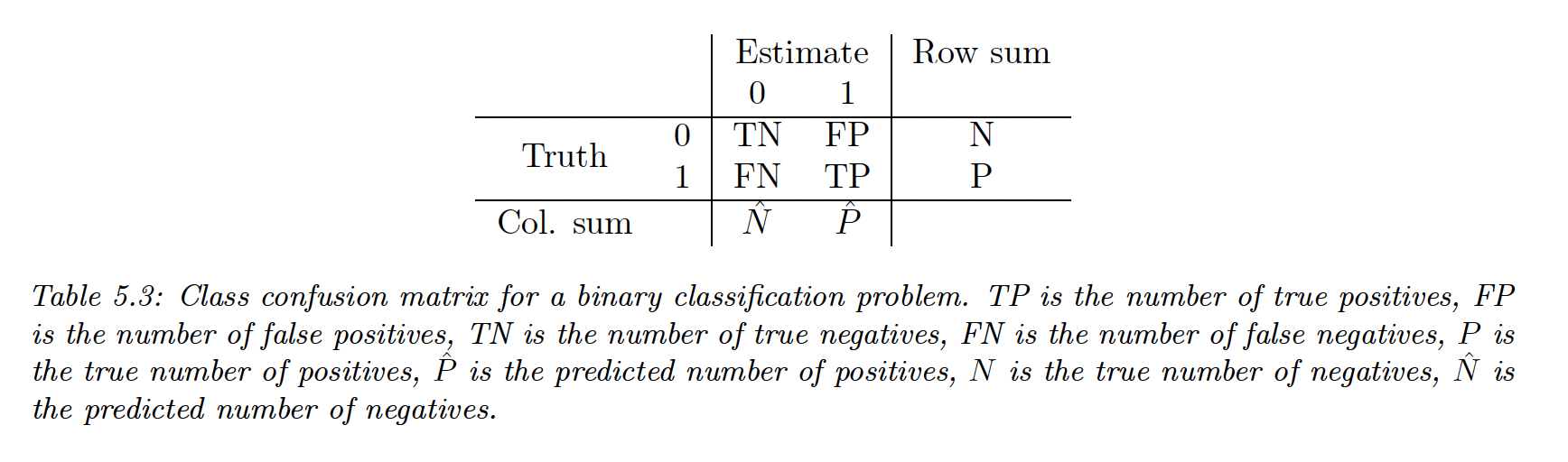
By normalizing by row or by columns we can derive various summary statistics.
We can plot the and as a function of (ROC curve) and the PR curve.
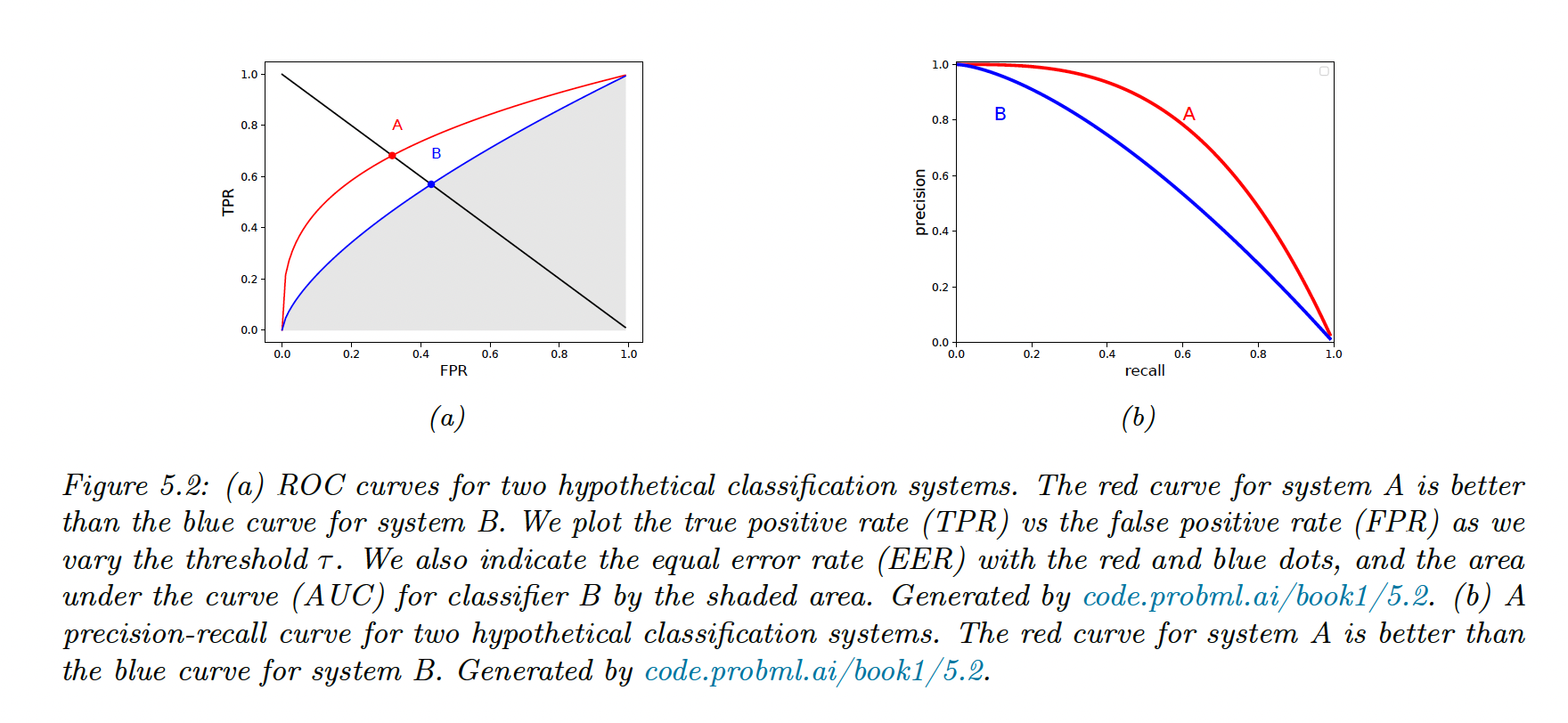
We summarize the ROC curve using its area under the curve (AUC), the best being 1 and the worst being 0.5 (random prediction).
PR curve can be summarized by taking the precision of the first recalled elements: this is the precision at score (P@k).
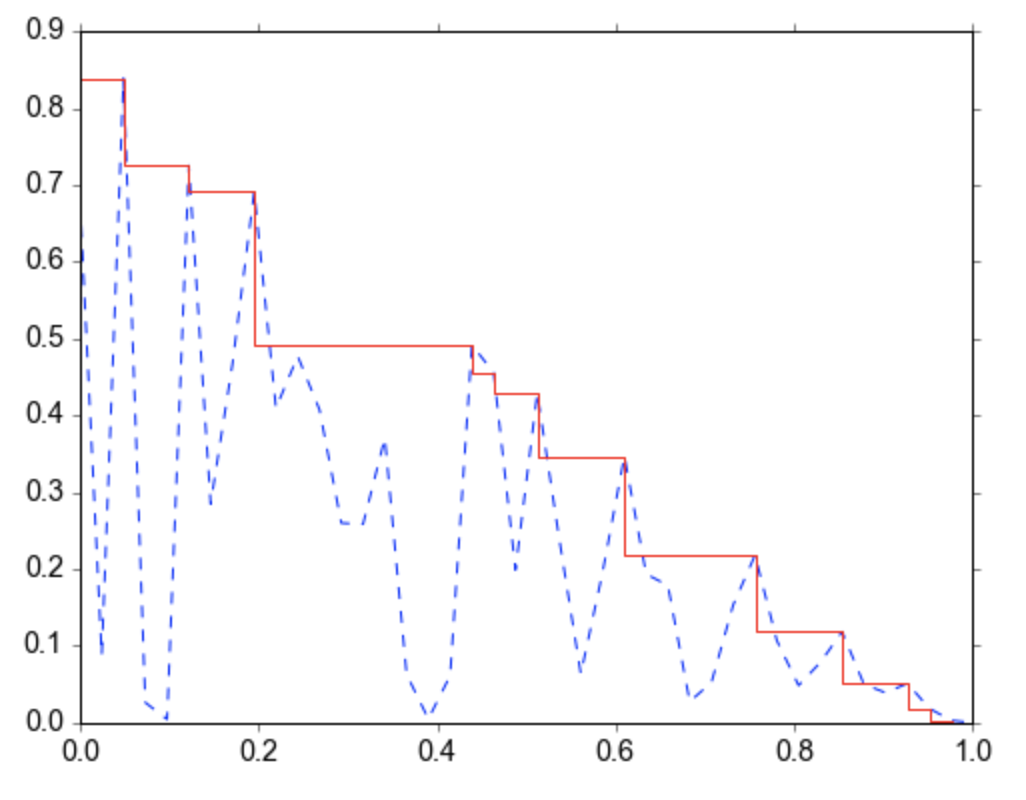
5.1.4 PR Curve
In rank retrieval problems, a PR curve can be non-monotonic (opens in a new tab). Suppose a classifier has a precision of 90% with recall of 10%, and a precision of 96% with a recall of 20%. We can compute the maximum precision (96%) we can achieve with at least a recall of (10%): this is the interpolated precision.
The average of the interpolated precisions (AP) is the area under the interpolated PR curve.
The mean average precision (mAP) is the mean of the AP over a set of different PR curves.
The score can be defined as follow for :
Or
If we set we got the harmonic mean of the precision and recall:
The harmonic mean is more conservative than the arithmetic mean and it requires both precision and recall to be high.
Suppose the recall is very high and the precision is very low, we would have
whereas
Using the score weights precision and recall equally. If recall is more important we may use , and if precision is more important we may use .
Class imbalance doesn’t affect ROC curve, since the TPR and FPR are a class ratio.
However the RC curve is affected, since the precision can be written:
with , so that when and when
The F1 score is also affected, since:
5.1.5 Regression problems
In regression settings, the set of state and action space is
L2 loss
The most common loss is the loss:
In this case, the risk is given by:
The optimal action reduce the risk at that point to 0, in this case the posterior mean:
L1 loss
loss is less sensitive to outliers than loss:
The optimal action is the posterior median, such that:
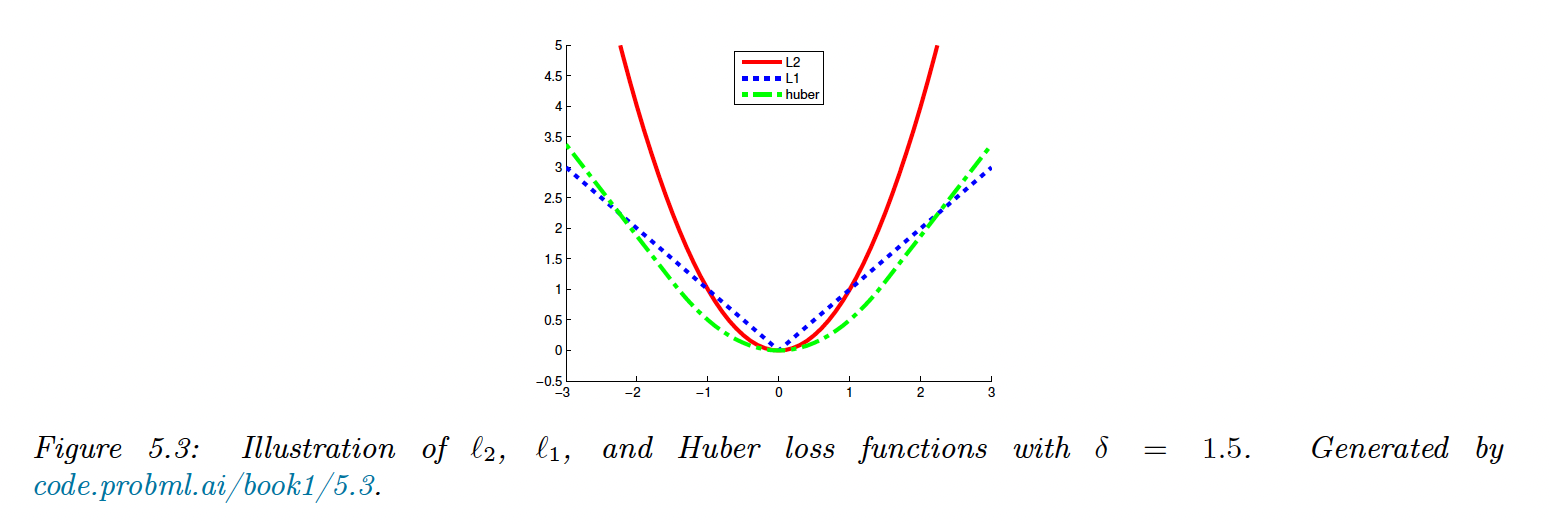
Huber loss
Another robust loss function:
where
5.1.6 Probabilistic prediction problems
We now assume the set of possible actions is to pick a probability distribution over some value. The state is a distribution and the action is another .
We want to pick to minimize for a given .
Kullback Leibler divergence
and are the entropy and cross-entropy.
is discrete, but this can be generalized to continuous values.
To find the optimal distribution to use, we minimize and as is constant wrt , we only minimize the cross-entropy term:
If the state is degenerate and puts all its mass on a single outcome i.e. , the cross entropy becomes:
This is the log loss of the predictive distribution when given target label .
Proper scoring rule
The key property we desire is that the loss function is minimized iff the chosen distribution matches the true distribution , ie $$, is the proper scoring rule.
The cross-entropy is a proper scoring rule since , but the term is sensitive to errors for low probability events
A common alternative is the Brier score:
See this discussion on scikit-learn (opens in a new tab) about the benefit and drawbacks of Log loss vs Brier score.