11.2 Least squares linear regression
11.2.1 Terminology
We consider models of the form:
The vector is known as weights. Each coefficient specifies the change in output we expect if we change the corresponding input by 1 unit.
is the bias and corresponds to the output when all inputs are 0. This captures the unconditional mean of the response
By assuming to be written as , we can absorb the term in .
If the input is multi-dimensional , this is called multivariate linear regression:
Generally, a straight line will underfit most datasets, but we can apply nonlinear transformations to the input features .
As long as the parameters of are fixed, the model remains linear in the parameters, even if it’s not linear in the raw inputs.
Polynomial expansion is an example of non-linear transformation: if the input is 1d and we use an expansion of degree , we get
11.2.2 Least square estimation
To fit a linear regression model to the data, we minimize the negative log-likelihood on the training set:
If we only focus on optimizing and not , the NLL is equal to the residual sum of square (RSS):
11.2.2.1 Ordinary least square
We can show that the gradient is given by:
We set it to zero and obtained the ordinary least square solution:
The quantity is the left pseudo-inverse of the (non-square) matrix .
We check that the solution is unique by showing that the Hessian is positive definite:
If is full rank (its columns are linearly independent) then is positive definite, hence the least square objective has a global minimum.
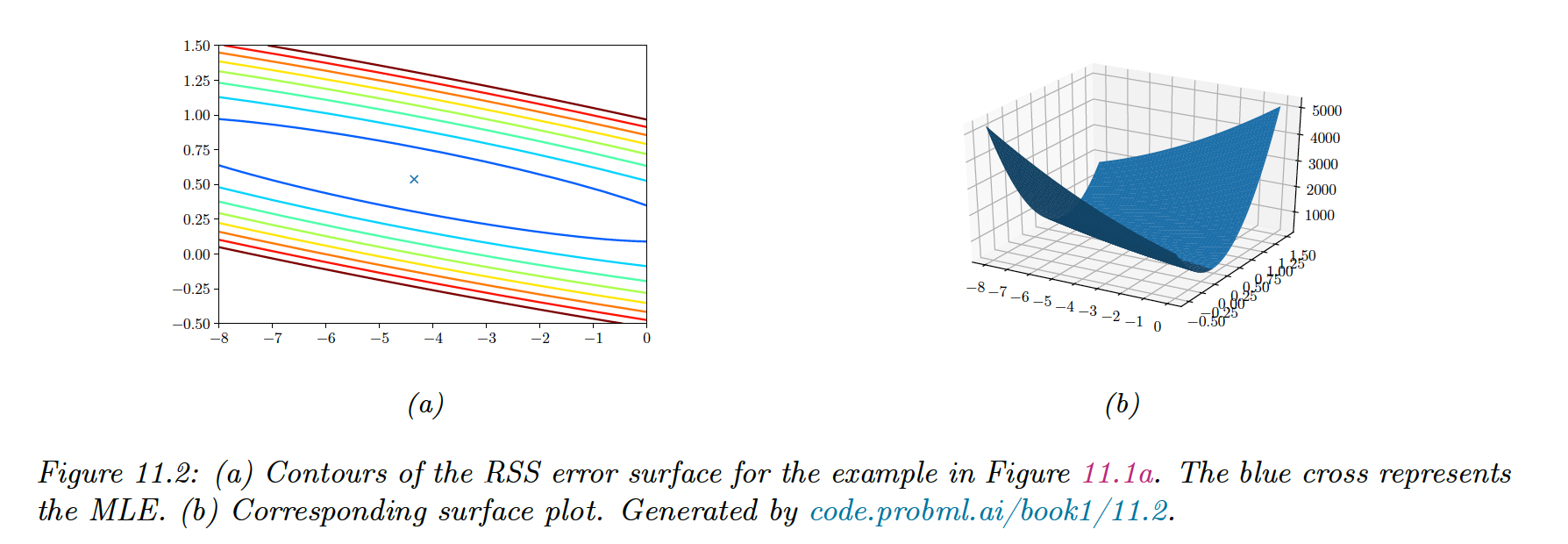
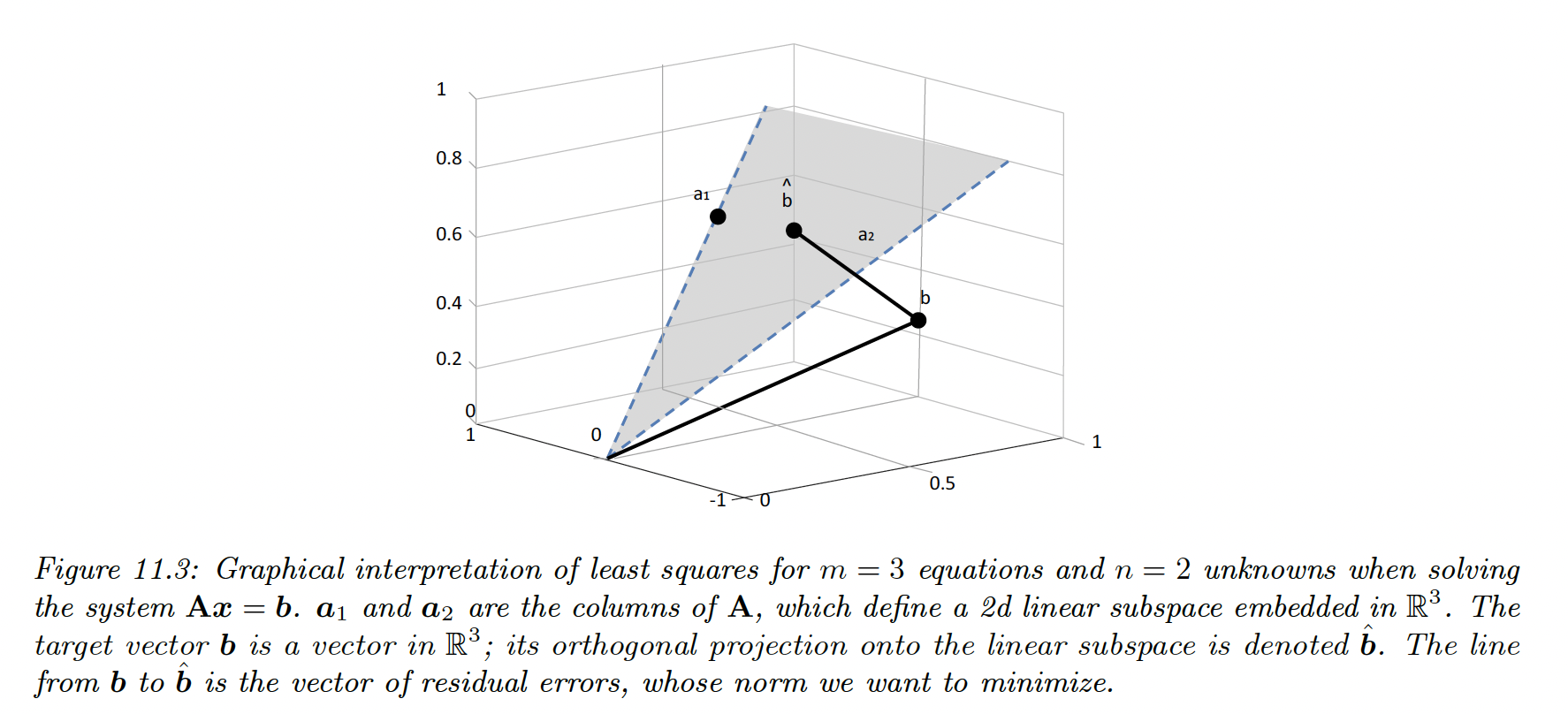
11.2.2.2 Geometric interpretation of least squares
We assume , so there are more equations than unknown, the system is over-determined.
We seek a vector that lies in the linear subspace spanned by , as close as possible to :
Since , there exists some weight vector such that:
To minimize the norm of the residual , we want the residual to be orthogonal to every column of :
Hence, our projected value is given by:
11.2.2.3 Algorithmic issues
Even if we can theoretically invert to compute the pseudo-inverse , we shouldn’t do it since could be ill-conditioned or singular.
A more general approach is to compute the pseudo-inverse using SVD. scikit-learn.linear_model uses scipy.linalg.lstsq, which in turn uses DGELSD, which is an SVD-based solver implemented by the Lapack library, written in Fortran.
However, if , it can be faster to use QR decomposition:
Since is upper triangular, we can solve it using back substitution, avoiding matrix inversion.
An alternative to matrix decomposition is to use an iterative solver, such as the conjugate gradient method (assuming is symmetric positive definite) and the GMRES (generalized minimal residual method) in the general case.
11.2.2.4 Weighted least squares
In some cases, we want to associate a weight with each example. For example, in heteroskedastic regression, the variance depends on the input:
thus:
where .
One can show that the MLE is given by:
11.2.3 Other approaches to computing the MLE
11.2.3.1 Solving for offset and slope separately
Above, we computed at the same time by adding a constant column to .
Alternatively, we can solve for and separately:
Thus, we can first estimate on centered data, then compute .
11.2.3.2 1d linear regression
In the case of 1d inputs, the above formula reduces to:
where and
11.2.3.3 Partial regression
We can compute the regression coefficient in the 1d case as:
Consider now the 2d case: , where
The optimal regression coefficient for is where we keep constant:
We can extend this approach to all coefficients, by fixing all inputs but one.
11.2.3.4 Online computing of the MLE
We can update the means online:
One can show that we can also update the covariance online as:
We find similar results for .
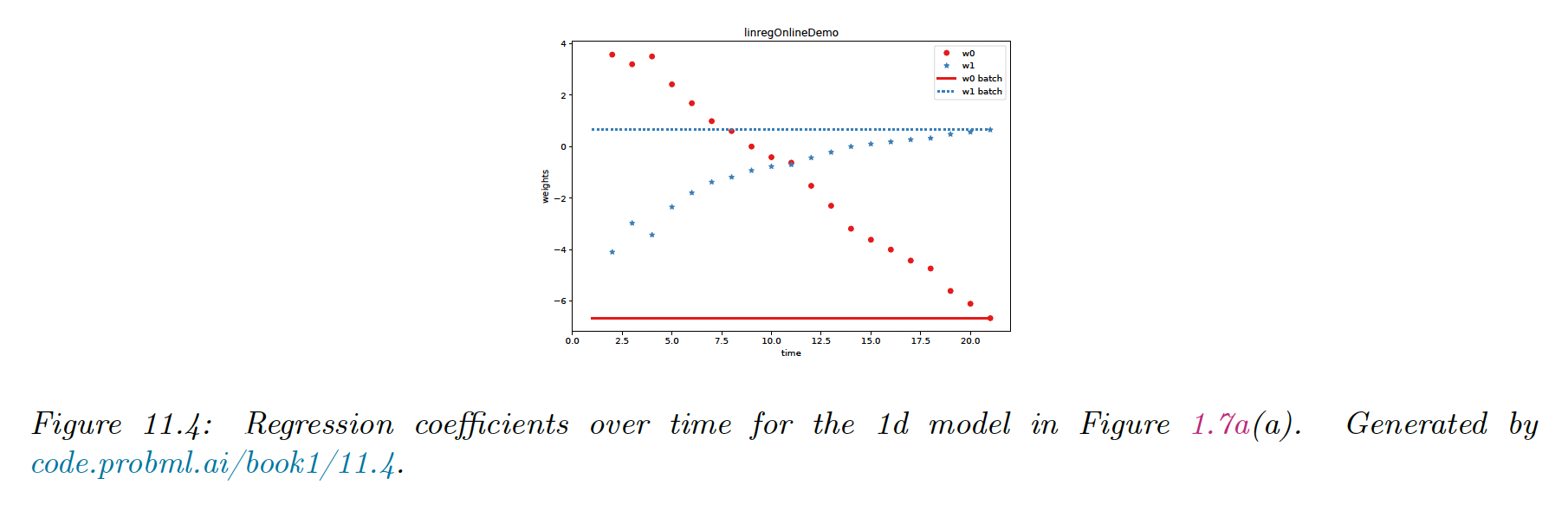
To extend this approach to dimensions inputs, the easiest approach is SGD. The resulting algorithm is called least mean square.
11.2.3.5 Deriving the MLE from a generative perspective
Linear regression is a discriminative model of the form , but we can also use generative models for regression.
The goal is to compute the conditional expectation:
Suppose we fit using a MVN. The MLEs for the parameters of the joint distribution are the empirical means and covariance:
Hence we have:
which we can rewrite as:
using
Thus we see that fitting the joint model and then conditioning it is the same as fitting the conditional model. However, this is only true for Gaussian models.
11.2.3.6 Deriving the MLE for
After estimating , it is easy to show that:
which is the MSE on the residuals.
11.2.4 Measuring goodness of a fit
11.2.4.1 Residuals plot
We can check the fit of the model by plotting the residuals vs the input , for a chosen dimension.
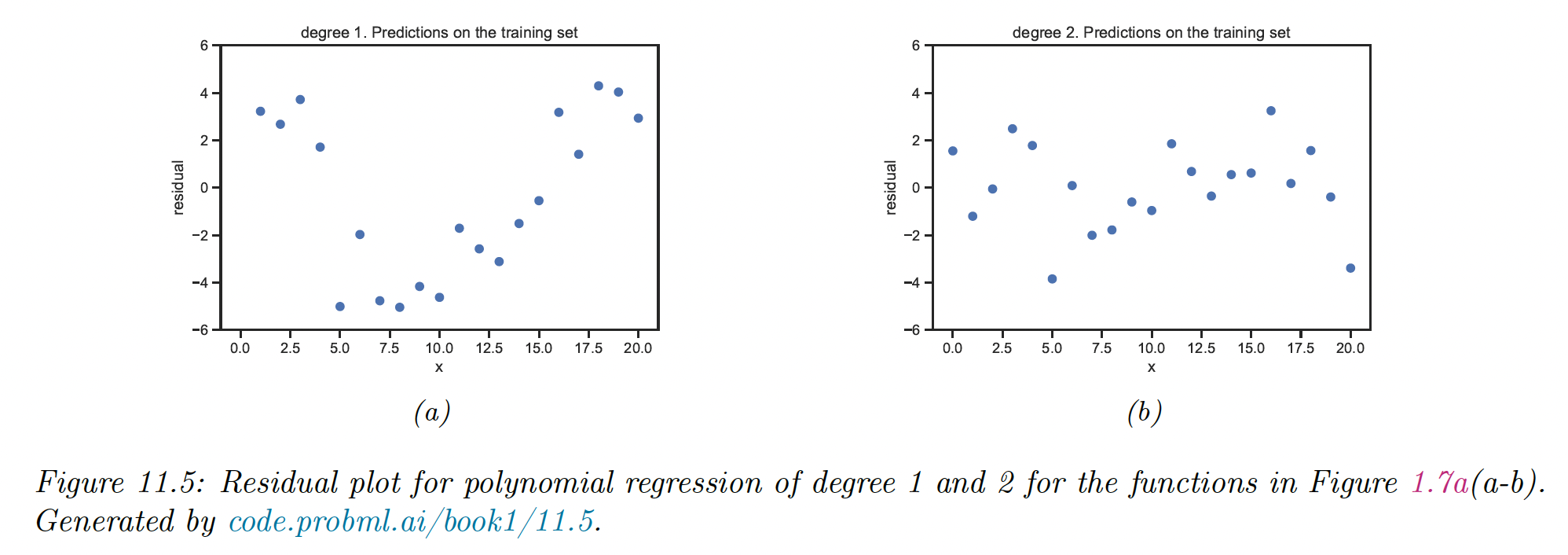
The residual model assumes a distribution, therefore the residual plot should show a cloud of points around 0 without any obvious trend. This is why b) above is a better fit than a).
We can also plot the prediction against , which should show a diagonal line.
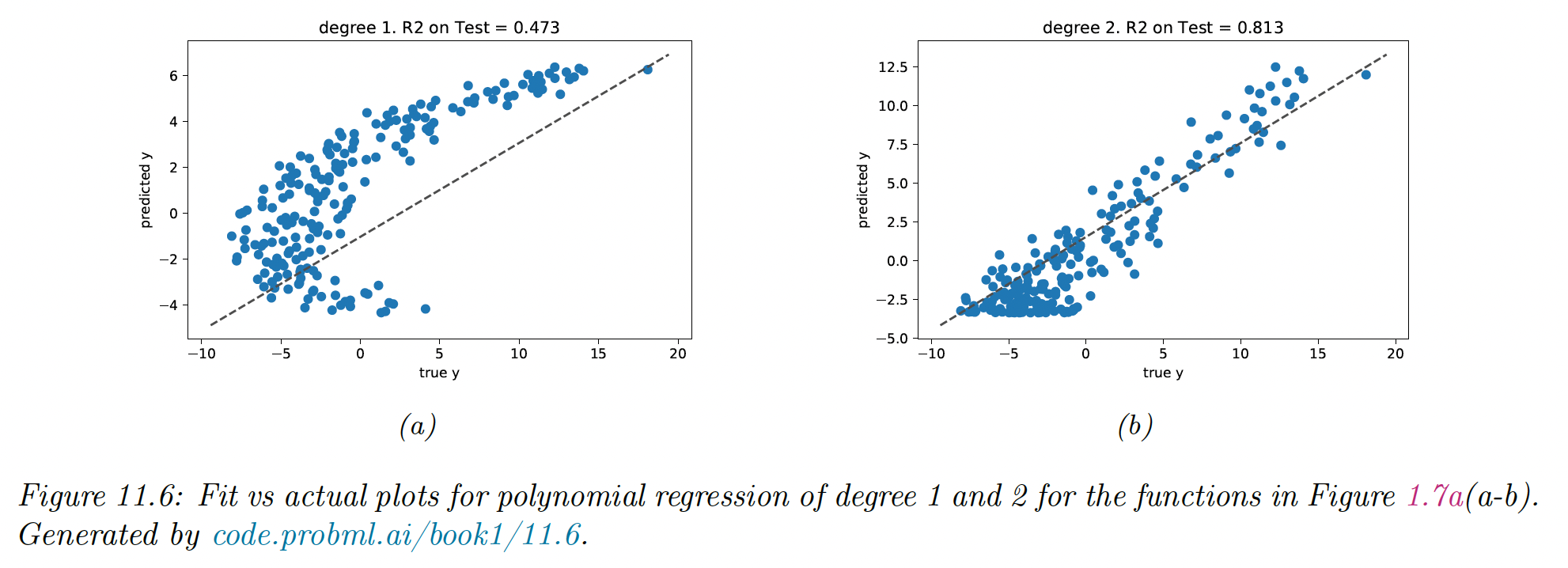
11.4.2.2 Prediction accuracy and R2
We can assess the fit quantitatively using the RSS or the RMSE:
The R2, or coefficient of determination is a more interpretable measure:
It measures the variance in the prediction relative to a simple constant prediction .